Cartik/Ru-train-dataset
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Cartik/Ru-train-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Big Russian Dataset是一个结合了多种主要俄语数据集的集合,包含一定程度的推理内容。该数据集经过去重、清理、使用GPT-4.1评分和过滤处理。数据集包含对话、来源、主题等多种特征,以及正确性、信息量、参与度等多个评分指标。它主要用于文本生成任务,主要语言为俄语,涉及指令、对话、数学、物理和代码等主题。数据集还包括多个子集,如IlyaGusev/saiga_scored、attn-signs/kolmogorov-3等,并对其进行了过滤处理。
The Big Russian Dataset is a combination of various primarily Russian-language datasets with some sort of reasoning. The dataset was deduplicated, cleaned, scored using GPT-4.1, and filtered. It includes features such as conversation, source, topic, and various scoring metrics like correctness, informativeness, and engagement. The dataset is designed for text-generation tasks, primarily in Russian, and covers topics like instruction, conversation, math, physics, and code. It incorporates multiple sub-datasets like IlyaGusev/saiga_scored and attn-signs/kolmogorov-3, which have been filtered according to specific conditions.
提供机构:
Cartik
搜集汇总
数据集介绍
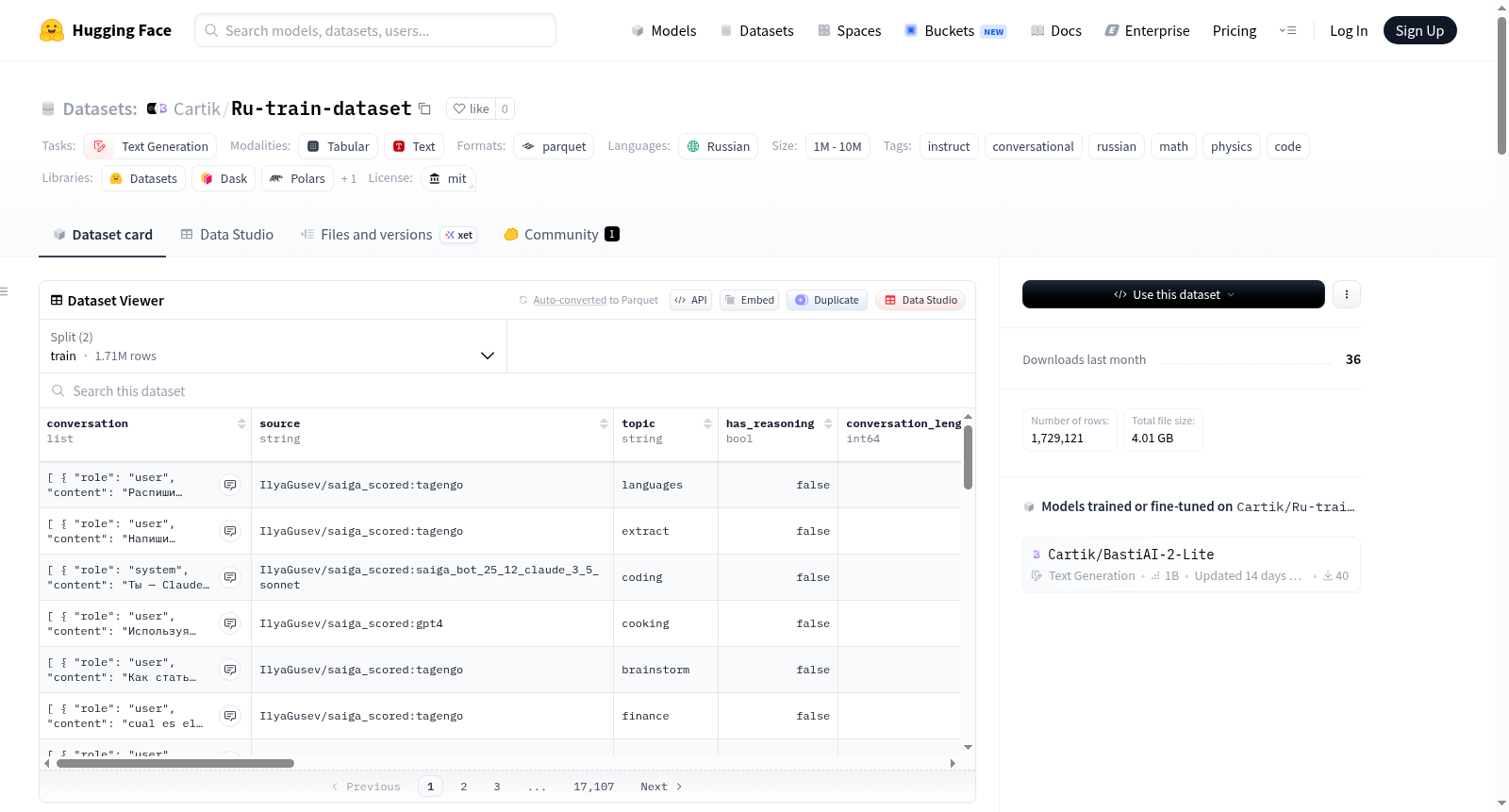
构建方式
Ru-train-dataset(亦被称为Big Russian Dataset)是由ZeroAgency.ru整合多种以俄语为主导的对话与指令数据集而成。在构建过程中,首先对来自二十余个开源数据源(如saiga_scored、russian_math、ru_slimorca-300k等)的原始样本进行去重与清洗,随后利用gpt-4.1模型对每条对话进行多维度的自动化评分,包括正确性、指令遵循度、信息量、参与度、质量、无错误性、礼貌性、帮助性、安全性等十余项指标。基于严格的过滤条件,仅保留拒绝回答分数低于1、隐私泄露分数低于1,且在各项质量评估中均达到设定阈值的样本,最终从约214.9万条原始数据中筛选出171万余条高质量训练样本,并保留1.8万条未经过滤的测试样本。数据集以parquet格式存储,包含train与test两个划分。
特点
该数据集最显著的特点在于其多维度的质量标注体系与精细化的过滤策略。每条对话样本不仅包含角色与内容字段,还附带由gpt-4.1模型评估的12项细粒度质量分数,涵盖正确性、指令遵循、信息性、参与度、质量、无错误、礼貌伦理、帮助性、安全性、简洁性、连贯性和相关性,并融合了总体得分、无冗余、拒绝回答、角色扮演、隐私泄露及推理能力等扩展指标。此外,数据集保留了原始来源、分类主题、是否含推理过程、对话长度、问题原文及唯一标识符等辅助字段,便于用户进行子集筛选与分析。数据集中部分样本包含显式的推理过程,以<think>标签标记,并针对不同场景(通用问答、任务解决、推理型任务)设计了多样化的系统提示词,增强了模型训练的多样性。
使用方法
该数据集专为俄语大语言模型的指令微调与对齐训练设计,可直接用于文本生成任务。用户可通过HuggingFace Datasets库加载,指定split为'train'或'test'获取对应划分。数据以对话格式组织,每条样本的'conversation'字段包含角色轮次列表,适用于构建监督式微调的训练数据。建议在加载后根据'overall_score'或其他质量分数进一步筛选特定质量区间的子集,或利用'source'字段按来源数据集进行组合实验。对于需要推理能力的任务,可筛选'has_reasoning'为True的样本,并利用'<think>'标签解析模型回答中的推理链。数据集的MIT许可证允许广泛的学术与商业使用。
背景与挑战
背景概述
近年来,大规模语言模型的快速发展对高质量、多语言训练数据的需求日益迫切。在此背景下,由俄罗斯团队ZeroAgency于近期构建并开源的Ru-train-dataset(亦称Big Russian Dataset)应运而生。该数据集汇聚了超过三十个以俄语为主的公开数据源,涵盖数学、物理、编程及通用指令遵循等多元领域,旨在弥补俄语高质量指令微调数据的稀缺性。其核心研究问题聚焦于如何通过系统化的数据清洗、去重及基于GPT-4.1的多维度评分过滤,构建一个兼具规模与质量的俄语对话数据集。该数据集的发布为俄语自然语言处理社区提供了重要的基础资源,有望推动俄语大模型的指令微调与推理能力提升。
当前挑战
构建Ru-train-dataset面临双重挑战。首先,在领域问题层面,俄语高质量指令数据的匮乏是制约俄语大模型性能的关键瓶颈,现有开源数据集多存在质量参差、噪声干扰及领域覆盖不全等问题,亟需一个经过严格筛选的综合性语料库来支撑模型训练。其次,在构建过程中,团队需应对数据异构性带来的统一格式难题,将来自数十个不同来源、格式与评分体系的对话样本进行标准化,并借助GPT-4.1进行细粒度的质量评估(涉及正确性、安全性、有用性等十余个维度),最终通过严苛的过滤条件剔除低质、有害及重复样本,在保留170万高质量样本的同时,确保数据的多样性与推理能力的体现,这对数据处理的精度与效率提出了极高要求。
常用场景
经典使用场景
Ru-train-dataset,作为一个大规模俄语指令对话数据集,其经典使用场景聚焦于俄语大语言模型的监督微调与对齐训练。该数据集整合了来自多个来源的超过170万条高质量对话样本,涵盖了数学、物理、编程等多元主题,并经由GPT-4.1进行质量评分与严格过滤。研究者通常利用其丰富的对话结构、角色标注以及多维度的质量指标(如正确性、安全性、有用性等)来训练模型遵循复杂指令、提升回答的连贯性与相关性,尤其在强化模型对俄语语境的理解与生成能力方面具有不可替代的价值。数据集中包含的推理型样本(以<think>标签标记)进一步拓展了其在引导模型进行逐步思考与逻辑推演方面的应用潜力。
实际应用
在实际应用方面,Ru-train-dataset赋能了一系列面向俄语用户的智能对话系统与虚拟助理的开发。基于该数据集微调的模型能够更精准地响应用户在日常生活、教育辅导、技术支持等场景中的俄语查询,例如解答数学难题、编写代码片段或提供安全的常识性建议。因注入了严格的伦理与安全过滤机制,该数据集特别适合部署于对内容合规性要求极高的客服自动化、在线教育平台及政府公共服务机器人中。此外,其包含的推理增强样本使得模型在需要逻辑断言的复杂任务(如科学计算或法律咨询)中展现出更可靠的表现,从而拓展了俄语AI在专业辅助工具领域的实用边界。
衍生相关工作
围绕Ru-train-dataset的发布,已催生或关联了一系列具有代表性的研究工作与衍生资源。其整合所依赖的原始数据集,例如IlyaGusev/saiga_scored、Vikhrmodels/russian_math和attn-signs/russian-reasoning等,各自在俄语对话系统、数学推理和逻辑链生成方面提供了重要贡献。该数据集的高质量评分策略,借鉴了多个领域的前沿评估框架,构成了后续俄语指令数据集构建工作的基准。同时,其推理型回答的标注范式为探索链式思维提示在俄语模型中的应用创造了可重复的实验平台。该数据集也常作为俄语能力评测的基座,支撑着诸如多语言模型跨语言迁移、俄语对齐技术对比等后续学术探索,体现了其作为俄语NLP领域关键基础设施的深远影响。
以上内容由遇见数据集搜集并总结生成


