izumi-lab/llm-japanese-dataset
收藏Hugging Face2024-01-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/izumi-lab/llm-japanese-dataset
下载链接
链接失效反馈官方服务:
资源简介:
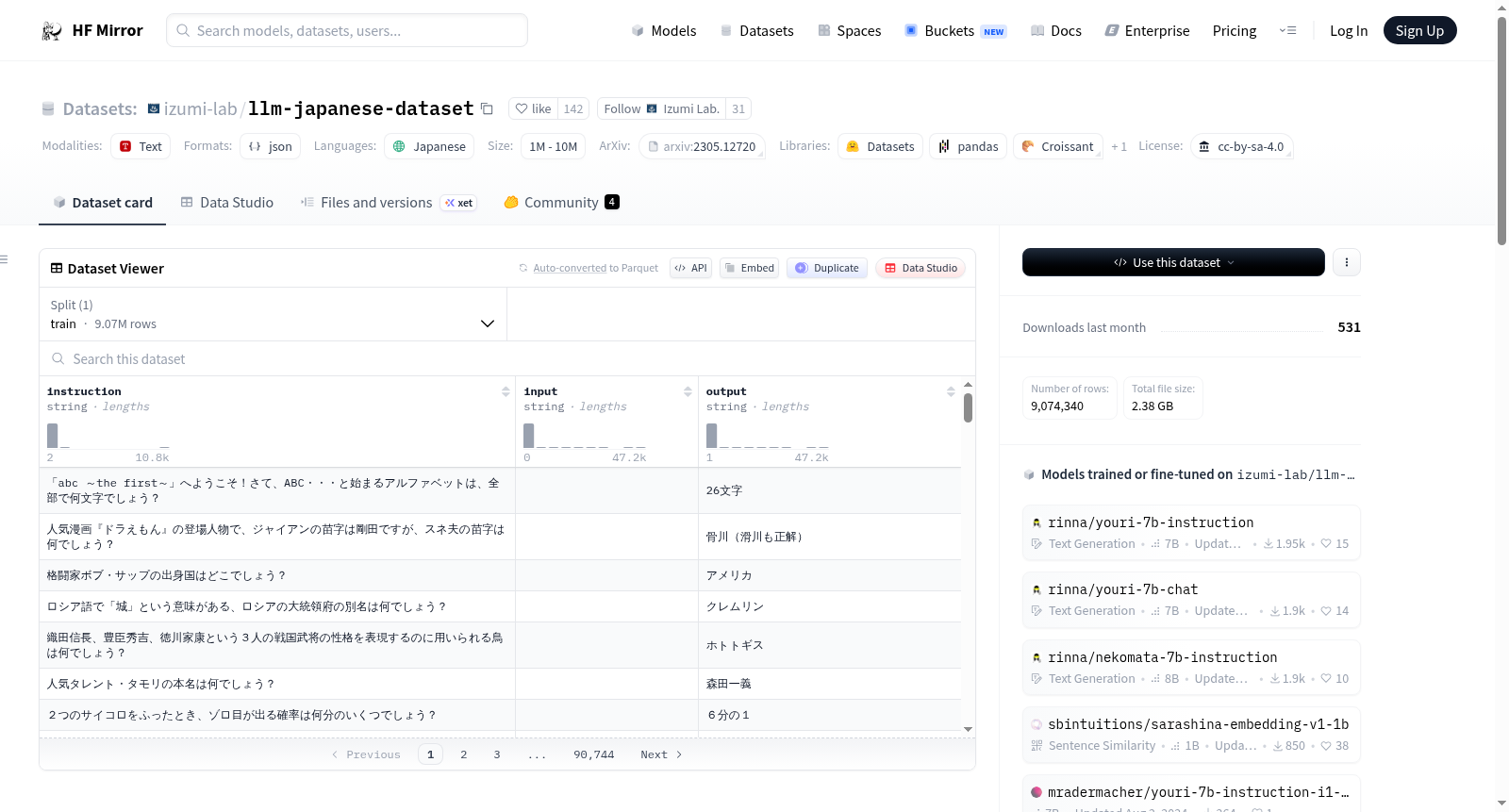
llm-japanese-dataset是一个用于构建日语指令(聊天)任务的数据集,主要用于对英语构建的LLM模型进行LoRA等微调。数据集包含多个版本,最新版本为1.0.3,数据量约为9,074,340条。数据集更新历史包括删除Alpaca数据集、更新Wikipedia摘要版本、删除Asian Language Treebank (ALT)数据集的缺失输出等。数据集的详细信息可以参考提供的论文链接,使用方式通过Hugging Face的datasets库加载。数据集遵循CC-BY-SA 4.0许可证,同时也有MIT许可证版本。
llm-japanese-dataset is a dataset dedicated to building Japanese instruction (chat) tasks, primarily used for fine-tuning English-based LLM models using methods such as LoRA. It offers multiple versions, with the latest being 1.0.3, and contains approximately 9,074,340 samples. The dataset's update history includes the removal of the Alpaca dataset, updates to the Wikipedia summary subset, the removal of missing outputs from the Asian Language Treebank (ALT) dataset, and other adjustments. Detailed information about the dataset can be accessed via the provided paper link, and it can be loaded using Hugging Face's datasets library. The dataset is licensed under CC-BY-SA 4.0, and a MIT-licensed version is also available.
提供机构:
izumi-lab
原始信息汇总
数据集概述
数据集名称
- llm-japanese-dataset
数据集用途
- 用于调整英语构建的LLM模型,以适应聊天(指令)响应任务。
数据集更新历史
- 2023/5/15:从数据集中移除了Alpaca dataset,以应对其NC许可证变更。
- 2024/1/4:删除了Wikipedia summary中仅由空白字符构成的输出,并更新了Wikipedia版本至20240101。
- 2024/1/18:删除了Asian Language Treebank (ALT)数据集中的缺失输出。
数据集版本信息
- v1.0.1:包含9,045,386数据(移除了Alpaca dataset)。
- v1.0.2:包含9,074,350数据(移除了空白输出样本并更新了Wikipedia版本)。
- v1.0.3:包含9,074,340数据(移除了ALT中的空白输出样本)。
数据集详细信息
- 详细信息请参考以下链接:
许可证
- CC-BY-SA 4.0
数据集大小
- 1M<n<10M
数据集语言
- 日本語(ja)
搜集汇总
数据集介绍
构建方式
在日语自然语言处理领域,构建高质量指令数据集对于提升大语言模型的本土化能力至关重要。llm-japanese-dataset通过系统整合多种公开日语语言资源,包括维基百科摘要、亚洲语言树库(ALT)以及日语问答语料等,构建了一个大规模的指令-响应对集合。其构建过程注重数据清洗与版本迭代,例如移除了输出为空白字符的样本,并响应外部数据集许可变更,及时剔除了Alpaca数据集,确保了数据集的合规性与纯净度。
使用方法
在应用层面,研究者可通过Hugging Face的`datasets`库便捷加载此数据集,指定相应版本号即可获取特定迭代版本的数据。该数据集主要服务于大语言模型的指令微调任务,用户可将其用于训练或评估模型在日语指令理解与生成方面的性能。具体使用细节,包括不同版本间的数据差异,可进一步参考其关联的GitHub仓库与学术论文,以获取全面的技术指导。
背景与挑战
背景概述
随着大语言模型在全球范围内的兴起,日语自然语言处理领域面临着专用指令数据稀缺的挑战。2023年,由Masanori Hirano、Masahiro Suzuki和Hiroki Sakaji等研究人员主导,构建了llm-japanese-dataset,旨在为日语大语言模型的指令微调提供高质量资源。该数据集整合了多种公开语言资源,核心研究问题聚焦于提升日语大语言模型在对话与指令遵循任务中的性能,对推动日语人工智能技术的发展具有重要影响力。
当前挑战
该数据集致力于解决日语大语言模型在指令微调任务中数据质量与多样性的挑战,包括如何构建大规模、高质量的日语指令对以适配复杂语言场景。在构建过程中,挑战主要源于多源数据的整合与清洗,例如需处理不同数据源的格式差异、剔除空白或无效输出,并应对上游数据许可变更所带来的动态调整,确保数据集的合规性与时效性。
常用场景
经典使用场景
在日语自然语言处理领域,izumi-lab/llm-japanese-dataset作为大规模指令调优数据集,其经典应用场景在于为预训练的大型语言模型提供高质量的日语对话数据。研究者常利用该数据集,通过LoRA等参数高效微调技术,对以英语为主的通用模型进行日语指令遵循能力的适配,从而构建能够流畅处理日语问答、摘要生成及对话任务的专用模型。
解决学术问题
该数据集有效应对了日语资源相对匮乏的学术挑战,为跨语言迁移学习提供了关键支撑。它解决了日语指令微调数据稀缺的问题,使得研究者能够系统评估模型在日语语境下的指令理解与生成性能,推动了日语大语言模型对齐技术、跨语言泛化能力及低资源语言建模方法的发展,对促进语言技术公平性具有深远意义。
实际应用
在实际部署中,该数据集支撑了多种日语智能系统的开发。基于其微调的模型可集成至聊天机器人、智能客服及内容创作工具中,为用户提供准确的日语信息查询、文本润色与摘要服务。在教育科技领域,它能辅助语言学习应用生成贴合日语语法与文化背景的练习材料,提升人机交互的自然度与实用性。
数据集最近研究
最新研究方向
在日语自然语言处理领域,随着大语言模型技术的蓬勃发展,针对日语指令微调数据集的研究日益成为焦点。izumi-lab/llm-japanese-dataset作为专门为日语大语言模型构建的指令对话数据集,其最新研究方向聚焦于提升数据质量与模型适应性。前沿探索涉及利用该数据集进行低秩自适应(LoRA)等高效微调技术,以优化英语预训练模型在日语任务中的表现,同时关注数据清洗与版本迭代,如移除空白输出和更新维基百科摘要,确保数据的时效性与准确性。这一进展不仅推动了日语大语言模型的本土化应用,还为跨语言迁移学习提供了重要支撑,促进了全球人工智能技术在多元语言环境中的均衡发展。
以上内容由遇见数据集搜集并总结生成


