SBB/sbb-dc-ocr
收藏Hugging Face2022-08-05 更新2024-04-21 收录
下载链接:
https://hf-mirror.com/datasets/SBB/sbb-dc-ocr
下载链接
链接失效反馈官方服务:
资源简介:
柏林国家图书馆OCR数据集包含了从1470年到1945年期间的153,942份数字化作品。在发布时,已有28,909份作品经过OCR处理,生成了4,988,099页的全文。每页OCR文本的语言通过langid工具进行识别,并包含语言预测的置信度分数。数据集支持的任务包括语言建模和掩码语言建模,适用于训练历史/OCR文本的语言模型。数据集包含多种语言,主要语言为德语、荷兰语、英语、法语和西班牙语。数据集的创建基于柏林国家图书馆数字收藏的OCR全文,并通过一系列数据处理步骤增强其可用性。
The Berlin State Library OCR Dataset contains 153,942 digitized works spanning from 1470 to 1945. At the time of its release, 28,909 of these works had undergone OCR processing, generating full texts across 4,988,099 pages. The language of each page's OCR text was identified using the langid tool, with confidence scores for the language predictions included. The dataset supports tasks including language modeling and masked language modeling, which are suitable for training language models on historical or OCR texts. The dataset covers multiple languages, with German, Dutch, English, French and Spanish as the primary languages. The dataset was developed based on the OCR full texts from the digital collections of the Berlin State Library, and its usability was enhanced through a series of data processing steps.
提供机构:
SBB
原始信息汇总
数据集概述
数据集名称
- 名称: Berlin State Library OCR
- 别名: 柏林州立图书馆OCR数据集
数据集基本信息
- 语言: 多语言(德语、荷兰语、英语、法语、西班牙语等)
- 语言创建方式: 专家生成
- 许可证: Creative Commons Attribution 4.0 International (CC-BY-4.0)
- 多语言支持: 是
- 数据集大小: 1M<n<10M
- 标签: OCR, 图书馆
- 任务类别: 填空, 文本生成
- 任务ID: 掩码语言建模, 语言建模
数据集内容
- 数据实例: 每个实例代表一个OCR处理的文本页。
- 数据字段:
- file name: 原始XML文件名
- text: 该页的OCR文本
- wc: OCR引擎预测的每个令牌的单词置信度
- ppn: 图书馆内部使用的Pica生产编号
- language:
langid.py预测的语言 - language_confidence:
langid.py给出的置信度分数 - 其他: 包括出版商、出版地、日期、标题、作者等元数据信息
数据集创建
- 来源数据: 来自柏林州立图书馆数字收藏的OCR全文
- 数据准备: 使用
dataprep.ipynb脚本处理数据,包括加载CSV文件、添加语言信息和元数据映射 - 注释: 机器生成的注释,包括OCR置信度和语言预测置信度
使用考虑
- 偏见讨论: 由于数据集包含历史材料,文本中可能包含与现代观念不符的观点和态度,使用时需谨慎考虑这些潜在偏见对语言模型的影响。
附加信息
- 数据集创建者: Labusch, Kai; Zellhöfer, David
- 贡献者: @davanstrien
许可证和引用信息
- 许可证: Creative Commons Attribution 4.0 International
- 引用信息: 见README文件中的引用格式
以上信息总结了Berlin State Library OCR数据集的关键特征和使用注意事项,为潜在用户提供了清晰的数据集概览。
搜集汇总
数据集介绍
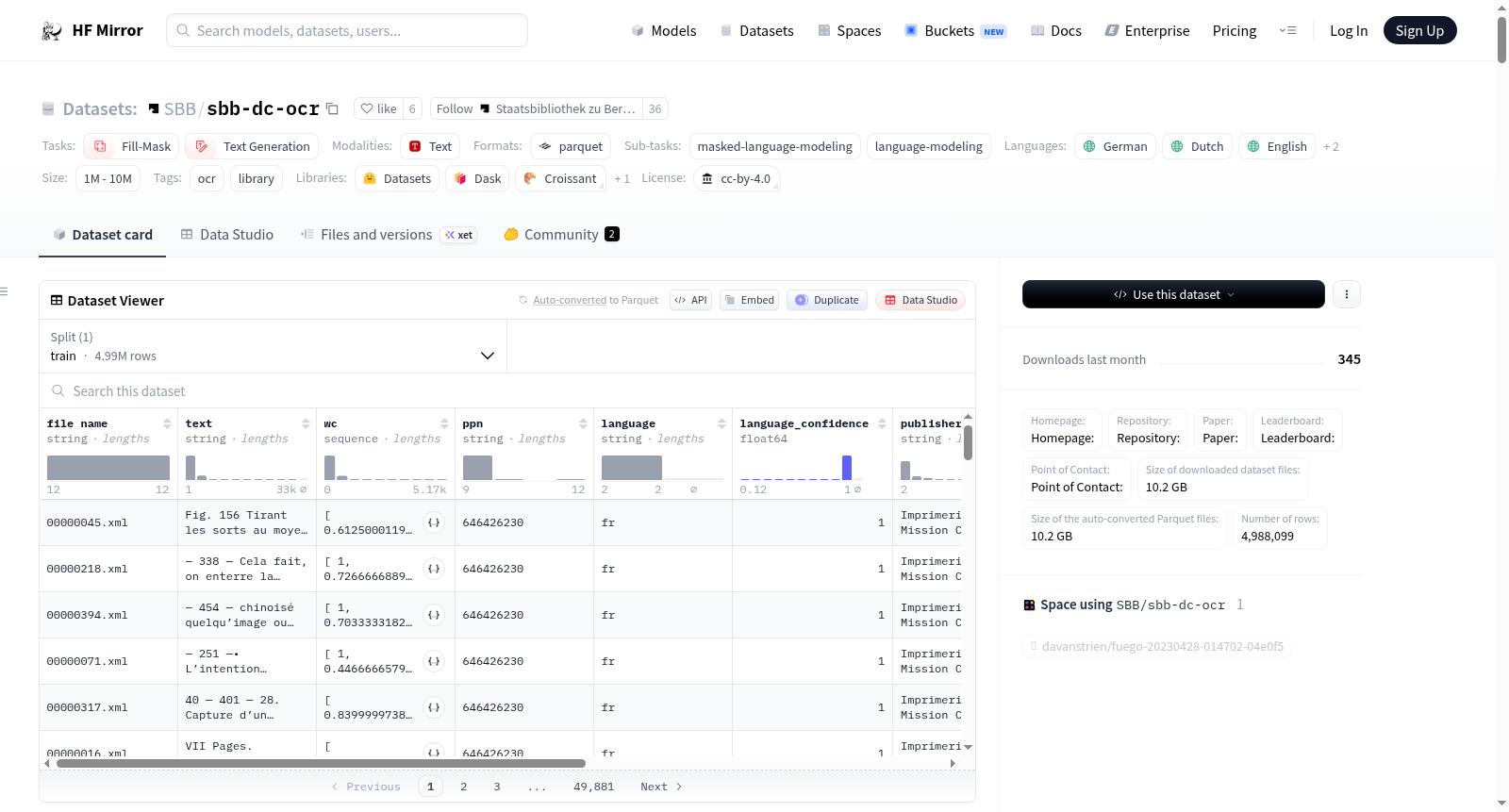
构建方式
在数字人文领域,柏林国家图书馆光学字符识别数据集(SBB/sbb-dc-ocr)的构建体现了对历史文献的现代化处理。该数据集源自柏林国家图书馆数字馆藏中153,942部数字化作品,涵盖1470年至1945年的历史时期。通过光学字符识别技术,对28,909部作品进行了文本提取,生成了4,988,099页全文数据。构建过程中,利用langid.py工具自动识别每页文本的语言,并附有置信度评分;同时整合了作品的元数据,如作者、出版地、日期和标题,并通过内部处理脚本将原始XML文件转化为结构化数据,以支持语言模型的训练需求。
特点
该数据集在历史文本处理领域展现出独特的多语言与多维度特征。其核心在于覆盖德语、荷兰语、英语、法语和西班牙语等多种语言,其中德语文本占据主导,反映了馆藏的历史地域分布。每页文本不仅包含OCR提取的原始内容,还提供了词汇级置信度序列,允许研究者评估识别质量。此外,数据集融合了丰富的书目元数据,如出版信息和作者详情,为文本分析提供了上下文背景。这些特征共同构建了一个跨越时空的语料库,既支持语言建模任务,也为历史语言学和文化研究提供了宝贵资源。
使用方法
在自然语言处理研究中,该数据集主要应用于语言建模和掩码语言建模任务。使用者可通过HuggingFace平台直接加载数据集,利用其单一训练分割进行模型训练或评估。鉴于数据集包含OCR置信度和语言标签,研究者可基于这些字段进行过滤,以构建特定语言或质量阈值的子集,从而优化训练数据的适用性。对于历史文本分析,元数据字段如日期和出版地可用于时序或地域性研究。需要注意的是,由于文本源自历史文献,可能存在与现代观念相悖的内容,使用时应考虑潜在的偏见影响。
背景与挑战
背景概述
柏林州立图书馆光学字符识别数据集(SBB/sbb-dc-ocr)由柏林州立图书馆于2019年发布,主要研究人员包括Kai Labusch与David Zellhöfer。该数据集源自1470年至1945年间馆藏的153,942部数字化作品,涵盖德语、荷兰语、英语、法语及西班牙语等多语言历史文献。其核心研究问题在于为历史文本的语言建模任务提供大规模、多语言的训练资源,尤其关注光学字符识别后文本的质量评估与语言识别。该数据集的建立显著推动了数字人文领域的发展,为历史文献的自动化处理与分析奠定了坚实基础。
当前挑战
该数据集旨在解决历史文献光学字符识别与多语言文本建模的挑战,具体包括识别因年代久远、印刷质量不一或字体变异导致的字符识别错误,以及处理多语言混杂文本的准确语言分类。在构建过程中,面临的主要挑战涉及从原始扫描文档中提取并标准化光学字符识别文本,需克服版面分析复杂性与识别置信度不一致的问题;同时,整合多源元数据时存在匹配缺失,部分文本的语言预测信息未能完整对齐,影响了数据的一致性与完整性。
常用场景
经典使用场景
在数字人文与历史语言学领域,柏林州立图书馆OCR数据集为研究多语言历史文献的文本挖掘提供了珍贵资源。该数据集收录了1470年至1945年间近五百万页的OCR处理文本,涵盖德语、荷兰语、英语等多种语言,并附有语言识别置信度与OCR词级置信度信息。学者们常利用其构建跨时代语言模型,分析历史文本的语言演变规律,或通过过滤特定语言与置信度阈值,优化训练数据的质量与代表性。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,有学者利用其多语言文本训练历史感知的掩码语言模型,以探究词汇语义的历史漂移;另有研究结合OCR置信度与语言特征,开发了针对低质量扫描文档的文本清洗管道。此外,该数据还被用于构建跨语言文献检索基准,推动了数字图书馆中多模态检索技术的发展。
数据集最近研究
最新研究方向
在数字人文与历史文献保护领域,柏林州立图书馆OCR数据集凭借其多语言、跨世纪的文本资源,为前沿研究提供了丰富素材。当前研究聚焦于利用该数据集训练适应历史文本的语言模型,以提升对早期印刷体文字和古旧文献的识别精度。结合OCR置信度与语言检测信息,学者们能够筛选特定时期或语种的文本,进而优化模型在历史语境下的表现。这一方向不仅推动了文化遗产的数字化保存,也为跨语言信息检索和文本分析技术注入了新的活力,在学术界与图书馆界引发了广泛关注。
以上内容由遇见数据集搜集并总结生成


