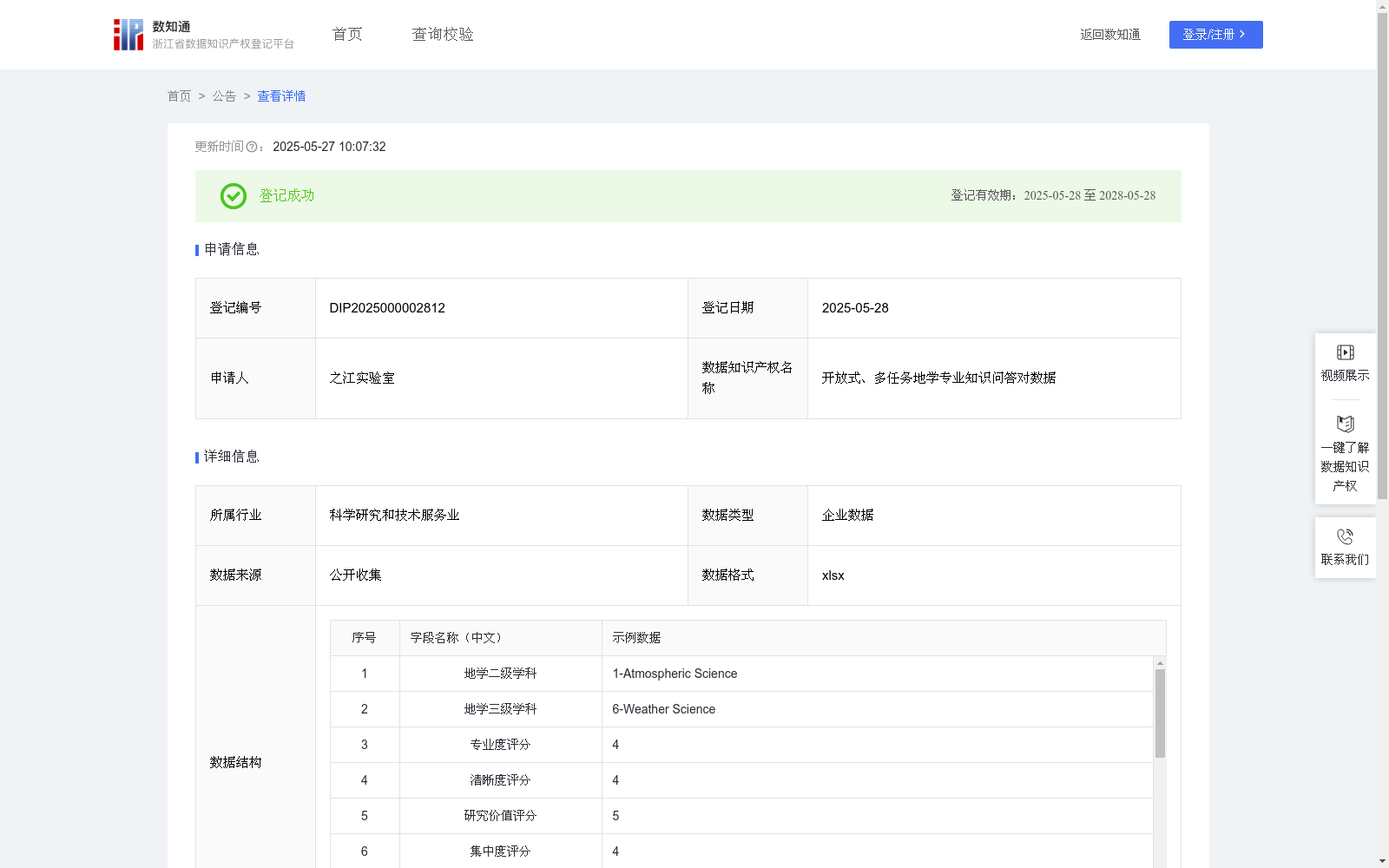
开放式、多任务地学专业知识问答对数据
收藏浙江省数据知识产权登记平台2025-05-27 更新2025-05-28 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/132671
下载链接
链接失效反馈官方服务:
资源简介:
该数据知识产权数据的总数大于50万条,能够直接用于地学领域大模型训练,使其学习地学领域专有的知识结构和表达术语,从而具备在地质、气候、环境等多个子学科领域上的文本任务处理和复杂问题推理能力。面相全球科研工作者打造开源开放的专业地学领域大语言模型,通过简单自然语言指令即可实现复杂地学科研任务的高效及时处理。该数据集不仅支持科研、教育、决策等多种应用场景,还能通过大模型助手工具在矿产勘探、环境监测等实际场景中发挥重要作用,推动地学领域的技术创新和知识传播。1. 从全球OA地学期刊中采集英文论文摘要,筛选保留标题与摘要内容完整且非空的样本,并通过标题去重,构建地学领域基础数据库。
2. 基于大规模语言模型自动抽取摘要信息和实体,通过实体重叠度和摘要相似性构建地学知识图谱。
3. 利用知识图谱和大规模语言模型自动生成多样化的提问角色和场景,涵盖单源和多源的事实型、推理型、应用型等不同类型问题,并通过上下文关联算法生成准确的答案,构建初始问答对数据集。
4. 对问题进行地学领域的二分类判断,并分析地学二级学科的分布,剔除偏离地学领域的边缘问题。
5. 构建五维评价模型:专业度(学科知识准确性)、清晰度(表述明确无歧义)、研究价值(反映学科前沿)、聚焦程度(问题边界清晰)、难度(逻辑推理分级),进行综合评分,保留各维度评分均大于60%的高质量问答对作为最终输出。
This dataset contains over 500,000 data entries, which can be directly used for training geoscience large language models (LLMs). It enables the models to learn the exclusive knowledge structures and terminological expressions of the geoscience field, thereby equipping them with the capabilities to handle text tasks and perform complex problem-solving reasoning across multiple sub-disciplines such as geology, climatology, and environmental science. Developed for global researchers, this open-source and open-access professional geoscience LLM can efficiently and timely handle complex geoscientific research tasks via simple natural language instructions.
This dataset supports multiple application scenarios including scientific research, education, and decision-making, and can also play a critical role in practical scenarios such as mineral exploration and environmental monitoring through LLM assistant tools, promoting technological innovation and knowledge dissemination in the geoscience domain.
1. Collect English abstracts of papers from global open-access (OA) geoscience journals, screen and retain samples with complete and non-empty title and abstract content, and deduplicate based on titles to build a basic geoscience database.
2. Automatically extract abstract information and entities using large language models, and construct a geoscience knowledge graph based on entity overlap and abstract similarity.
3. Leverage the knowledge graph and large language models to automatically generate diverse question roles and scenarios, covering single-source and multi-source questions of different types including factual, reasoning, and applied ones, and generate accurate answers via context association algorithms to build an initial question-answer pair dataset.
4. Perform binary classification judgment for each question within the geoscience field, analyze the distribution of secondary geoscience disciplines, and eliminate marginal questions that deviate from the geoscience domain.
5. Construct a five-dimensional evaluation model: professionalism (accuracy of disciplinary knowledge), clarity (unambiguous and explicit expression), research value (reflecting disciplinary frontiers), focus (clear question boundary), and difficulty (logical reasoning grading). Conduct comprehensive scoring, and retain high-quality question-answer pairs with scores above 60% in all dimensions as the final output.
提供机构:
之江实验室
创建时间:
2025-04-16
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个开放式、多任务的地学专业知识问答对数据集,包含1797条高质量问答对,涵盖地质、气候、环境等多个子学科领域。数据集通过五维评价模型筛选,适用于地学领域大模型训练和多种实际应用场景。
以上内容由遇见数据集搜集并总结生成


