有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
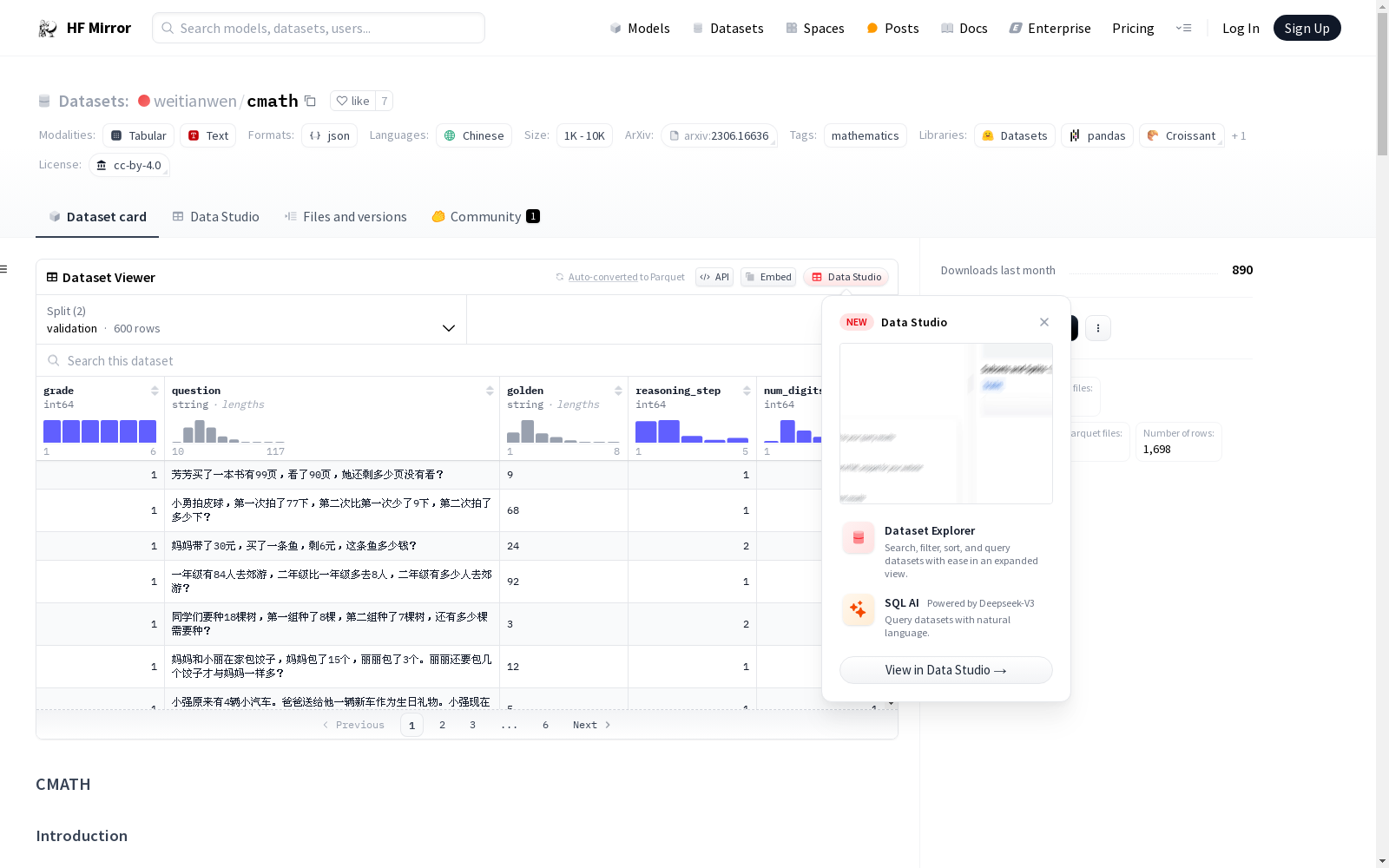
CMATH 数据集包含 1.7k 道中国小学数学应用题,这些题目来自实际的中国教材和考试,并带有详细的注释。该数据集旨在评估流行的大型语言模型(LLMs)在小学数学水平上的能力,并发现只有 GPT-4 在所有六个小学年级中达到了成功(准确率 >= 60%),而其他模型在不同年级水平上表现不佳。此外,通过在 CMATH 数据集中增加干扰信息来评估 LLMs 的鲁棒性,发现 GPT-4 是唯一保持鲁棒性的模型。
初始发布包含 600 个示例,每个小学年级 100 道题目。剩余部分将在年底发布。
为了评估 LLMs 对“无关”信息的鲁棒性,手动创建了一个包含 60 个示例的小型“干扰数据集”,每个年级 10 个示例。每个示例包含一个原始问题和五个带有 1 到 5 条无关信息的增强问题。
提供了一个 eval.py 脚本,用于实现自动化评估。
CC BY 4.0
@misc{wei2023cmath, title={CMATH: Can Your Language Model Pass Chinese Elementary School Math Test?}, author={Tianwen Wei and Jian Luan and Wei Liu and Shuang Dong and Bin Wang}, year={2023}, eprint={2306.16636}, archivePrefix={arXiv}, primaryClass={cs.CL} }
rag-datasets/rag-mini-bioasq
该数据集主要用于问答和句子相似性任务,涉及生物医学领域。数据集包含两个配置:text-corpus和question-answer-passages,分别对应不同的数据文件路径。数据集来源于BioASQ任务11b的训练数据集,并通过`generate.py`脚本生成了子集。
hugging_face 收录
红外谱图数据库
收集整理红外谱图实验手册等数据,建成了红外谱图数据库。本数据库收录了常见化合物的红外谱图。主要包括化合物数据和对应的红外谱图数据。其中,原始红外谱图都进行了数字化处理,从而使谱峰检索成为可能。用户可以在数据库中检索指定化合物的谱图,也可以提交谱图/谱峰数据,以检索与之相似的谱图数据,以协助进行谱图鉴定。
国家基础学科公共科学数据中心 收录
Natural Scene Braille Character Recognition Dataset
There are a total of 1157 Braille segment images in this dataset, including 925 in the training set and 232 in the testing set. There are two folders in the directory of this dataset: character_label and segment_label. The character_rabel file contains three formats of Braille segment images: (1) Braille segment images and label files stored in ICDAR-2015 format, each. jpg file corresponds to a. txt file, where each line stores the position and recognition label of a braille character rectangle box. The data corresponds to the coordinates of the four points in the rectangle box and the recognized numerical label; (2) The original format of the data is stored in the folder org. Each .jpg file in this folder corresponds to a .json file which marked by labelme software; (3) VOC format, stored in voc-data folder. This folder stores images and corresponding .xml files in VOC format, and marks the position of each braille character rectangle box and its corresponding numerical label information in the .xml file. In addition, the original Braille images of natural scenes and the corresponding Braille segment markings .json files are stored in the folder segment_label.
DataCite Commons 收录
CT-ORG
3D CT, 140 Cases, 6 Categories of Organ Segmentation.
github 收录
猫狗图像数据集
该数据集包含猫和狗的图像,每类各12500张。训练集和测试集分别包含10000张和2500张图像,用于模型的训练和评估。
github 收录