weitianwen/cmath
收藏Hugging Face2023-10-14 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/weitianwen/cmath
下载链接
链接失效反馈官方服务:
资源简介:
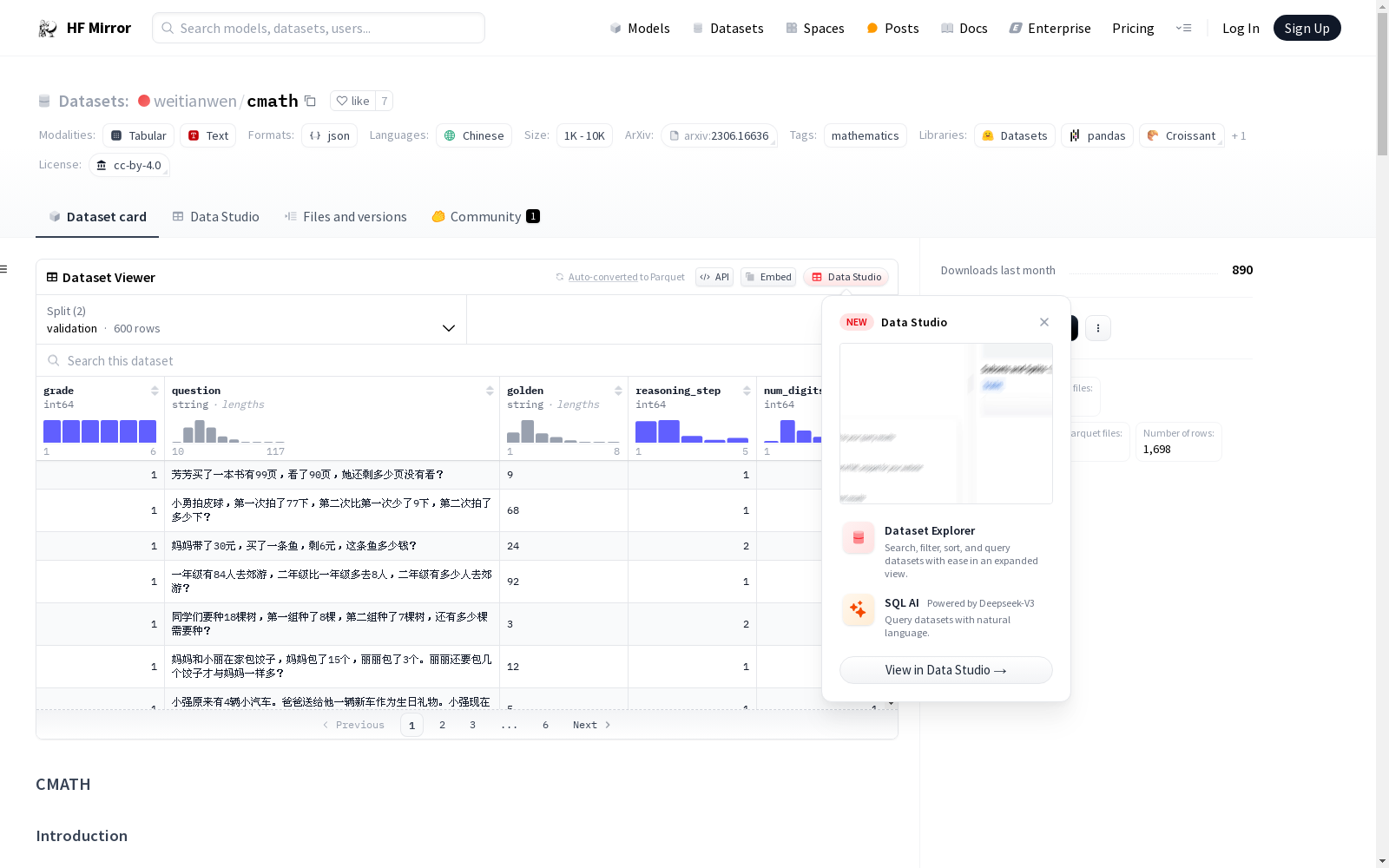
CMATH数据集是一个包含1.7k个小学级别数学应用题的数据集,来源于实际的中国练习册和考试。该数据集旨在提供一个基准工具,用于评估大型语言模型(LLMs)在小学数学问题上的能力。数据集分为两部分:cmath_dev和distractor。cmath_dev是数据集的初始发布版本,包含600个例子,每个小学年级100个问题。distractor数据集则是为了评估LLMs对无关信息的鲁棒性,包含60个例子,每个年级10个。
The CMATH dataset is a corpus of 1.7k primary school-level mathematical word problems sourced from real Chinese exercise books and examinations. This dataset is intended to serve as a benchmark tool for evaluating the performance of Large Language Models (LLMs) on primary school mathematics problem-solving tasks. The dataset is split into two subsets: cmath_dev and distractor. The cmath_dev, the initial released version of the dataset, contains 600 examples, with 100 problems for each primary school grade. The distractor subset is designed to evaluate LLMs' robustness against irrelevant information, comprising 60 examples, with 10 problems per grade.
提供机构:
weitianwen
原始信息汇总
CMATH 数据集
简介
CMATH 数据集包含 1.7k 道中国小学数学应用题,这些题目来自实际的中国教材和考试,并带有详细的注释。该数据集旨在评估流行的大型语言模型(LLMs)在小学数学水平上的能力,并发现只有 GPT-4 在所有六个小学年级中达到了成功(准确率 >= 60%),而其他模型在不同年级水平上表现不佳。此外,通过在 CMATH 数据集中增加干扰信息来评估 LLMs 的鲁棒性,发现 GPT-4 是唯一保持鲁棒性的模型。
数据集
cmath_dev
初始发布包含 600 个示例,每个小学年级 100 道题目。剩余部分将在年底发布。
distractor
为了评估 LLMs 对“无关”信息的鲁棒性,手动创建了一个包含 60 个示例的小型“干扰数据集”,每个年级 10 个示例。每个示例包含一个原始问题和五个带有 1 到 5 条无关信息的增强问题。
脚本
提供了一个 eval.py 脚本,用于实现自动化评估。
许可证
CC BY 4.0
引用
@misc{wei2023cmath, title={CMATH: Can Your Language Model Pass Chinese Elementary School Math Test?}, author={Tianwen Wei and Jian Luan and Wei Liu and Shuang Dong and Bin Wang}, year={2023}, eprint={2306.16636}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
CMATH数据集的构建,源于实际的中国小学课本及考试题库,精心挑选并详细注释了1.7k个小学级别数学应用题。该数据集旨在为评估大型语言模型(LLMs)在小学数学能力方面的表现提供一个基准工具。数据集的构建充分考虑了模型的评估需求,涵盖了六个小学年级的数学问题,并针对模型对干扰信息的处理能力,特别增加了含有干扰信息的题目。
特点
CMATH数据集的特点在于其详尽的注释和来源的真实性,为研究LLMs在数学领域的应用提供了可靠的评价标准。数据集按照小学年级划分问题,覆盖了数学应用题的多样性。此外,数据集包含了专门设计的干扰信息,用以评估模型在处理非相关干扰时的鲁棒性,这为模型能力的深入分析提供了重要维度。
使用方法
使用CMATH数据集,研究者可以通过提供的脚本`eval.py`进行自动化的评估。数据集分为训练集和干扰信息增强的测试集,用户可以依据需要选择相应的数据子集进行模型训练和评估。详细的文档和示例有助于用户快速上手,而开源的许可协议(CC BY 4.0)则保证了数据的自由使用与传播。
背景与挑战
背景概述
在探索大型语言模型(LLM)在数学问题解决方面的能力背景下,中国小学数学问题数据集(CMATH)应运而生。该数据集由1.7k个来自实际中国作业本和考试的小学级别数学文字问题及其详细注释构成,创建于2023年,主要研究人员包括Tianwen Wei、Jian Luan、Wei Liu、Shuang Dong和Bin Wang。该数据集的核心研究问题是评估流行LLM在小学数学能力方面的对应年级水平,其研究成果为相关领域提供了重要的基准工具,并揭示了LLM在数学问题解决方面的局限性,对推动LLM的持续发展与进步具有重要影响力。
当前挑战
CMATH数据集在构建过程中及所解决问题的领域面临多项挑战。首先,大型语言模型在处理不同年级的数学问题时表现出不同程度的困难,其中仅GPT-4在所有六个小学年级中取得了超过60%的准确率。其次,数据集构建过程中对LLM的鲁棒性进行了评估,通过在原始问题中添加无关信息来增加干扰,仅有GPT-4保持了其鲁棒性。这些挑战凸显了LLM在理解和解决数学问题时的局限性,指明了未来研究和模型发展的方向。
常用场景
经典使用场景
在探索大型语言模型在数学领域的应用能力时,CMATH数据集提供了不可或缺的基准工具。该数据集通过包含1.7k个详细注释的小学级别数学文字问题,来源于实际的中国教材和考试,成为评估大型语言模型数学能力的重要资源。经典的使用场景在于,研究者可以利用该数据集对各种商业和开源语言模型进行小学各年级数学问题解答能力的测试,以量化模型在数学领域的表现。
解决学术问题
CMATH数据集解决了如何评估大型语言模型在小学数学水平上的能力的问题。通过该数据集,研究者可以识别出模型在不同年级水平的数学问题解答上的局限性,推动了对语言模型在数学教育应用中的深入理解和改进。此外,数据集还通过添加干扰信息来评估模型的鲁棒性,揭示了模型在面对实际应用中可能遇到的不相关信息时的表现,从而促进了模型的发展和完善。
衍生相关工作
基于CMATH数据集,学术界已经衍生出了一系列相关工作。研究者们不仅对现有的大型语言模型进行了评估,还探讨了如何通过增强模型来提升其解决数学问题的能力。此外,该数据集也激发了对于如何在教育领域更有效地利用人工智能技术的讨论和研究。
以上内容由遇见数据集搜集并总结生成


