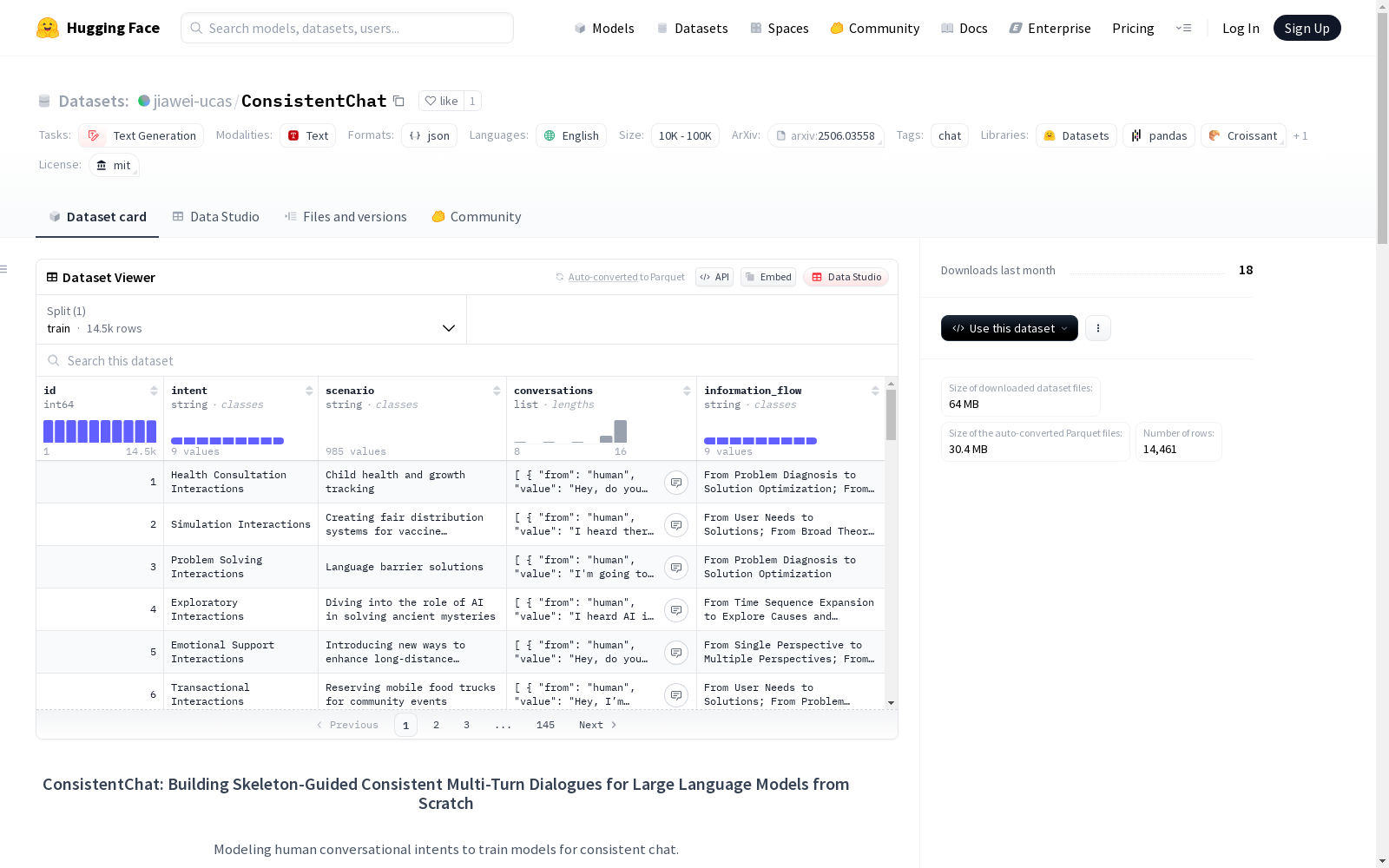
ConsistentChat
收藏ConsistentChat 数据集概述
基本信息
- 名称: ConsistentChat
- 许可证: MIT
- 任务类别: 文本生成
- 语言: 英语
- 标签: 聊天
- 数据规模: 10K-100K
数据集简介
ConsistentChat 是一个用于训练大语言模型的多轮对话数据集,专注于构建骨架引导的一致性多轮对话。该数据集通过建模人类对话意图来解决现有指令数据合成方法主要关注单轮指令而忽略跨轮一致性的问题。
核心方法
采用骨架引导的多轮对话生成框架,包含两个阶段:
- 意图建模: 通过将每个对话分配到九个明确定义的意图轨迹之一来捕捉人类对话的全局结构
- 骨架生成: 构建与建模意图一致的用户查询结构序列,作为约束和指导下游指令合成过程的支架
数据统计
- 总对话数: 约15,000个多轮对话
- 总话语数: 224,392条话语
- 生成模型: Qwen-2.5-72B-Instruct
详细统计信息
数据集包含九种对话交互类型,每种类型的详细统计如下:
| 统计指标 | 问题解决 | 教育交互 | 健康咨询 | 探索性交互 | 娱乐交互 | 模拟交互 | 情感支持 | 信息检索 | 交易交互 |
|---|---|---|---|---|---|---|---|---|---|
| 每对话平均话语数 | 15.39 | 15.62 | 15.60 | 15.45 | 15.65 | 15.59 | 15.57 | 15.40 | 15.38 |
| 查询平均词数 | 19.64 | 18.73 | 19.67 | 19.94 | 20.79 | 19.22 | 20.82 | 18.99 | 20.01 |
| 查询最大词数 | 37 | 38 | 38 | 46 | 42 | 43 | 46 | 37 | 42 |
| 响应平均词数 | 59.09 | 61.91 | 60.34 | 60.44 | 56.03 | 56.63 | 62.85 | 55.58 | 56.06 |
| 响应最大词数 | 135 | 119 | 124 | 128 | 125 | 118 | 121 | 133 | 119 |
| 每轮平均词数 | 39.36 | 40.32 | 40.00 | 40.19 | 38.41 | 37.93 | 41.83 | 37.28 | 38.03 |
| 每轮最大词数 | 135 | 119 | 124 | 128 | 125 | 118 | 121 | 133 | 119 |
| 总对话数 | 1631 | 1632 | 1633 | 1615 | 1585 | 1604 | 1573 | 1637 | 1551 |
| 总话语数 | 25104 | 25494 | 25474 | 24952 | 24808 | 25002 | 24486 | 25216 | 23856 |
使用方式
python from datasets import load_dataset
加载数据集
dataset = load_dataset("jiawei-ucas/ConsistentChat")
打印数据集结构
print(dataset)
访问训练集中的示例
print(dataset["train"][0])
实验效果
在Light、TopDial和MT-Eval基准测试中,使用ConsistentChat微调的模型在聊天一致性方面实现了20-30%的提升,任务成功率最高提高了15%,显著优于在现有单轮和多轮指令数据集上训练的模型。
引用
bibtex @misc{chen2025consistentchat, title={ConsistentChat: Building Skeleton-Guided Consistent Dialogues for Large Language Models from Scratch}, author={Jiawei Chen and Xinyan Guan and Qianhao Yuan and Guozhao Mo and Weixiang Zhou and Yaojie Lu and Hongyu Lin and Ben He and Le Sun and Xianpei Han}, year={2025}, eprint={2506.03558}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2506.03558}, }