ft-instruction-synthesizer-collection
收藏魔搭社区2025-11-27 更新2024-06-29 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/ft-instruction-synthesizer-collection
下载链接
链接失效反馈官方服务:
资源简介:
# Instruction Pre-Training: Language Models are Supervised Multitask Learners (EMNLP 2024)
This repo contains the **fine-tuning data collection for the [context-based instruction synthesizer](https://huggingface.co/instruction-pretrain/instruction-synthesizer)** used in our paper [Instruction Pre-Training: Language Models are Supervised Multitask Learners](https://huggingface.co/papers/2406.14491).
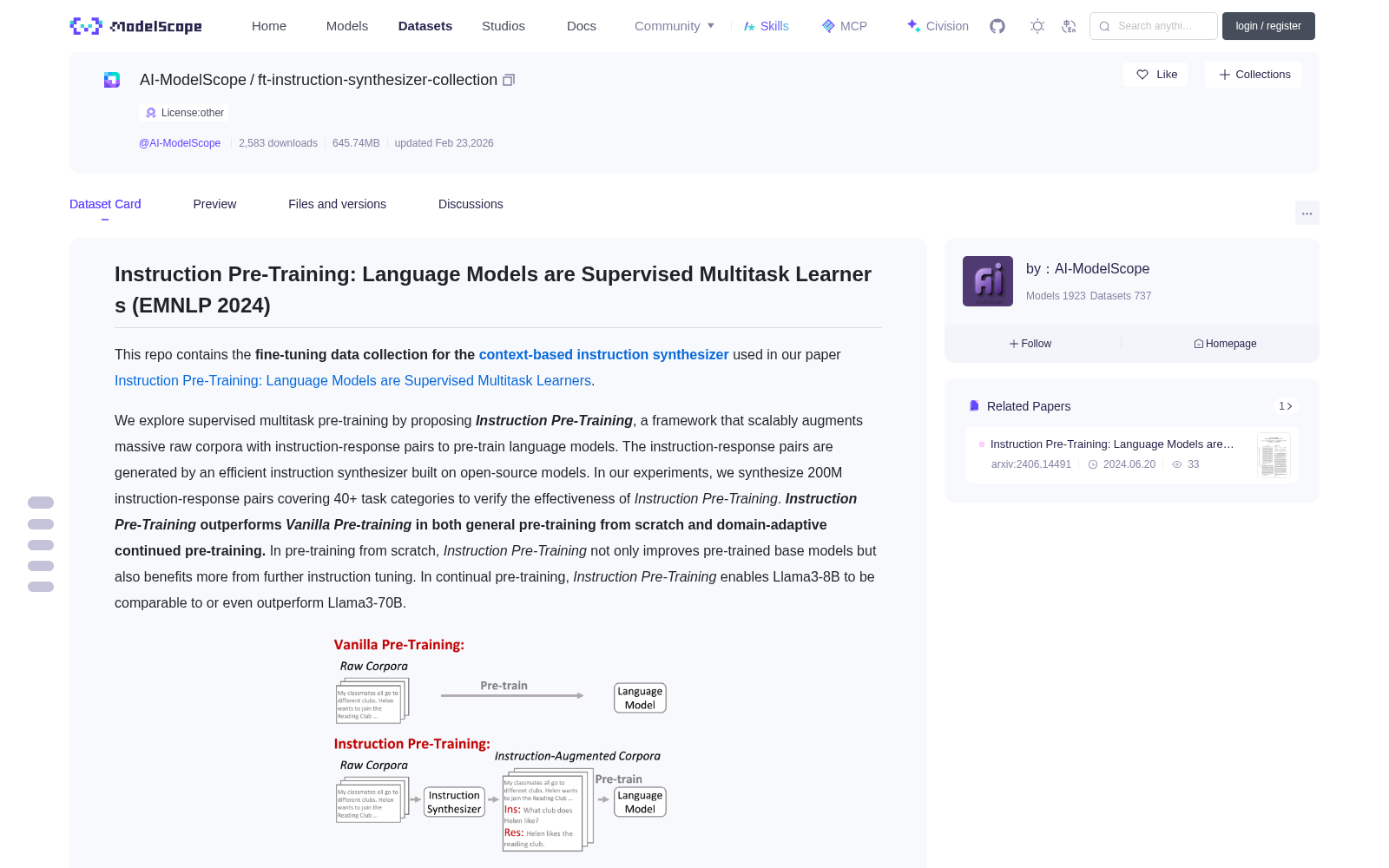
We explore supervised multitask pre-training by proposing ***Instruction Pre-Training***, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train language models. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of *Instruction Pre-Training*. ***Instruction Pre-Training* outperforms *Vanilla Pre-training* in both general pre-training from scratch and domain-adaptive continued pre-training.** In pre-training from scratch, *Instruction Pre-Training* not only improves pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, *Instruction Pre-Training* enables Llama3-8B to be comparable to or even outperform Llama3-70B.
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/vRdsFIVQptbNaGiZ18Lih.png" width="400">
</p>
**************************** **Updates** ****************************
* 2024/11/30: Released the multimodal version of the instruction synthesizer: [Visual Instruction Synthesizer](https://huggingface.co/AdaptLLM/Adapt-MLLM-to-Domains)
* 2024/9/20: Our paper has been accepted by EMNLP 2024 main conference🎉
* 2024/9/11: Updated [FAQ on continual pre-training from Llama3](https://huggingface.co/instruction-pretrain/instruction-synthesizer)
* 2024/8/29: Updated [guidelines](https://huggingface.co/instruction-pretrain/medicine-Llama3-8B) on evaluating any 🤗Huggingface models on the domain-specific tasks
* 2024/7/31: Updated pre-training suggestions in the `Advanced Usage` section of [instruction-synthesizer](https://huggingface.co/instruction-pretrain/instruction-synthesizer)
* 2024/7/15: We scaled up the pre-trained tokens from 100B to 250B, with the number of synthesized instruction-response pairs reaching 500M. The performance trend on downstream tasks throughout the pre-training process:
<p align='left'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/0okCfRkC6uALTfuNxt0Fa.png" width="500">
</p>
* 2024/6/21: Released the [paper](https://huggingface.co/papers/2406.14491), [code](https://github.com/microsoft/LMOps), and [resources](https://huggingface.co/instruction-pretrain)
## Resources
**🤗 We share our data and models with example usages, feel free to open any discussions at [this page](https://huggingface.co/papers/2406.14491)! 🤗**
- Thanks to the demo [davanstrien/instruction-synthesizer](https://huggingface.co/spaces/davanstrien/instruction-synthesizer) for implementing our approach
- Context-Based Instruction Synthesizer: [instruction-synthesizer](https://huggingface.co/instruction-pretrain/instruction-synthesizer)
- Fine-Tuning Data for the Synthesizer: [ft-instruction-synthesizer-collection](https://huggingface.co/datasets/instruction-pretrain/ft-instruction-synthesizer-collection)
- General Models Pre-Trained from Scratch (on 100B tokes):
- [InstructLM-500M](https://huggingface.co/instruction-pretrain/InstructLM-500M)
- [InstructLM-1.3B](https://huggingface.co/instruction-pretrain/InstructLM-1.3B)
- Domain-Specific Models Pre-Trained from Llama3-8B:
- [Finance-Llama3-8B](https://huggingface.co/instruction-pretrain/finance-Llama3-8B)
- [Biomedicine-Llama3-8B](https://huggingface.co/instruction-pretrain/medicine-Llama3-8B)
- General Instruction-Augmented Corpora: [general-instruction-augmented-corpora](https://huggingface.co/datasets/instruction-pretrain/general-instruction-augmented-corpora)
- Domain-Specific Instruction-Augmented Corpora (no finance data to avoid ethical issues): [medicine-instruction-augmented-corpora](https://huggingface.co/datasets/instruction-pretrain/medicine-instruction-augmented-corpora)
## Multitask Fine-Tuning to Synthesize Instructions Based on Raw Texts
We conduct multitask fine-tuning on a language model to develop a context-based instruction synthesizer capable of generating instruction-response pairs from any raw text. The overall tuning and inference framework is:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/0889QyG59QM3rPeZlcTzZ.png" width="700">
</p>
The tuning data are curated to be highly diverse, enabling the instruction synthesizer to generalize to unseen data. Therefore, during inference, we can directly employ the instruction synthesizer to create instruction-response pairs based on the raw pre-training corpora. An overview of the datasets is:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/140_he6XwK4QLv7Kf-Uye.png" width="700">
</p>
During tuning, each sequence fed into the synthesizer concatenates multiple examples, all sampled from the same dataset. Additionally, we calculate the tuning loss only on the instruction-response pairs.
For example, to cook samples of one dataset into our required fine-tuning format:
```python
from datasets import load_dataset
# Templates
context_template = ' <CON> {context} </CON>'
QA_template = '<QUE> {question} <ANS> {answer} </END>'
delimiter = '\n\n'
bos_token = '<s>' # replace this with the bos token of your synthesizer's base model, e.g., "<s>" for llama2 but "<|begin_of_text|>" for llama3
eos_token = '</s>' # replace this with the eos token of your synthesizer's base model, e.g., "</s>" for llama2 but "<|end_of_text|>" for llama3
def cook_context(raw_context):
"""Format the context."""
return bos_token + context_template.replace('{context}', raw_context) + delimiter
def cook_instruction_response_pairs(QA_list):
"""Format downstream instruction(Q)-response(A) pairs."""
ins_res_list = []
for qa_entry in QA_list:
qa = QA_template.replace('{question}', qa_entry['Q']).replace('{answer}', qa_entry['A'])
ins_res_list.append(qa)
return delimiter.join(ins_res_list) + eos_token
# Take SQuAD for example
# # the full list of datasets is:
# # datasets = ['squad', 'TopiOCQA', 'HotpotQA', 'WikiTableQuestions' 'Quac', 'QED', 'FairyTaleQA', 'mctest', 'NarrativeQA', 'race', 'race_c', 'ReClor', 'LogiQA', 'AQUA_RAT_yes_opt', 'TriviaQA', 'CosmosQA', 'ECQA', 'NLQuAD', 'NewsQA', 'tweet_qa', 'quail', 'dream', 'multirc', 'ROPES', 'QuaRTz', 'CoQA', 'DoQA', 'qasper' 'PubMedQA_no_opt', 'PubMedQA_yes_opt', 'COVID_QA', 'ConvFinQA', 'SpartQA', 'bAbI', 'QASC']
dataset_name = 'squad'
ds = load_dataset(
"instruction-pretrain/ft-instruction-synthesizer-collection",
data_files=f"{dataset_name}/shard/*jsonl",
split='train'
)
# Collect all the inputs and outputs for fine-tuning
results = []
for entry in ds:
text = cook_context(entry['context'])
ins_res_pairs = cook_instruction_response_pairs(entry['QA_list'])
results.append({'input': text, 'output': ins_res_pairs})
# Print out the formatted example
print(f'{results[0]["input"]}{results[0]["output"]}')
# NOTE: In further fine-tuning, we concatenate multiple such input-output pairs from the same dataset into a single sequence,
# and calculate loss only on the output part
```
**UPDATE 2024/8/30**: Since we have explicitly added BOS and EOS tokens when formatting the data, you do NOT need to add them during tokenization. For example, the tokenization would be: `input_token_ids = tokenizer(input, add_special_tokens=False, **kwargs).input_ids`
## Licensing Information
This data collection contains datasets from various sources. Please ensure compliance with their respective licenses.
## Citation
If you find our work helpful, please cite us:
[Instruction Pre-Training](https://huggingface.co/papers/2406.14491) (EMNLP 2024)
```bibtex
@article{cheng2024instruction,
title={Instruction Pre-Training: Language Models are Supervised Multitask Learners},
author={Cheng, Daixuan and Gu, Yuxian and Huang, Shaohan and Bi, Junyu and Huang, Minlie and Wei, Furu},
journal={arXiv preprint arXiv:2406.14491},
year={2024}
}
```
[Adapt LLM to Domains](https://huggingface.co/papers/2309.09530) (ICLR 2024)
```bibtex
@inproceedings{
cheng2024adapting,
title={Adapting Large Language Models via Reading Comprehension},
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=y886UXPEZ0}
}
```
# 指令预训练:语言模型是监督多任务学习者(EMNLP 2024)
本仓库收录了我们发表于论文《指令预训练:语言模型是监督多任务学习者》中所使用的**基于上下文的指令合成器(context-based instruction synthesizer)**的微调数据集集合。论文链接:https://huggingface.co/papers/2406.14491,指令合成器仓库:https://huggingface.co/instruction-pretrain/instruction-synthesizer。
我们提出了**指令预训练(Instruction Pre-Training)**这一框架,通过为大规模原始语料库可扩展地添加指令-回复对以预训练语言模型,以此探索监督多任务预训练。该指令-回复对由基于开源模型构建的高效指令合成器生成。在实验中,我们合成了覆盖40余个任务类别的2亿条指令-回复对,以验证指令预训练的有效性。**指令预训练(Instruction Pre-Training)**在从零开始的通用预训练与领域自适应持续预训练场景中,均优于**基础预训练(Vanilla Pre-training)**。在从零开始的预训练中,指令预训练不仅能够优化预训练基础模型,还能在后续的指令微调中获得更显著的性能提升。在持续预训练场景中,指令预训练可使Llama3-8B模型达到甚至超越Llama3-70B模型的性能水平。
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/vRdsFIVQptbNaGiZ18Lih.png" width="400">
</p>
**************************** **更新日志** ****************************
* 2024/11/30:发布指令合成器的多模态版本:[视觉指令合成器(Visual Instruction Synthesizer)](https://huggingface.co/AdaptLLM/Adapt-MLLM-to-Domains)
* 2024/9/20:我们的论文已被EMNLP 2024主会议收录🎉
* 2024/9/11:更新了[Llama3持续预训练常见问题解答(FAQ)](https://huggingface.co/instruction-pretrain/instruction-synthesizer)
* 2024/8/29:更新了[面向特定领域任务的Huggingface模型评估指南](https://huggingface.co/instruction-pretrain/medicine-Llama3-8B)
* 2024/7/31:在[instruction-synthesizer](https://huggingface.co/instruction-pretrain/instruction-synthesizer)的「高级用法」板块中更新了预训练建议
* 2024/7/15:我们将预训练令牌数从1000亿扩展至2500亿,合成的指令-回复对数量达到5亿条。预训练过程中下游任务的性能趋势如下:
<p align='left'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/0okCfRkC6uALTfuNxt0Fa.png" width="500">
</p>
* 2024/6/21:发布了[论文](https://huggingface.co/papers/2406.14491)、[代码](https://github.com/microsoft/LMOps)与[相关资源](https://huggingface.co/instruction-pretrain)
## 资源
🤗 我们公开了数据集与模型并附带示例用法,欢迎在[该页面](https://huggingface.co/papers/2406.14491)发起任何讨论!🤗
- 感谢[davanstrien/instruction-synthesizer](https://huggingface.co/spaces/davanstrien/instruction-synthesizer) demo实现了我们的方法
- 基于上下文的指令合成器:[instruction-synthesizer](https://huggingface.co/instruction-pretrain/instruction-synthesizer)
- 合成器的微调数据集:[ft-instruction-synthesizer-collection](https://huggingface.co/datasets/instruction-pretrain/ft-instruction-synthesizer-collection)
- 从零开始预训练的通用模型(基于1000亿令牌):
- [InstructLM-500M](https://huggingface.co/instruction-pretrain/InstructLM-500M)
- [InstructLM-1.3B](https://huggingface.co/instruction-pretrain/InstructLM-1.3B)
- 基于Llama3-8B的领域专属预训练模型:
- [Finance-Llama3-8B](https://huggingface.co/instruction-pretrain/finance-Llama3-8B)
- [Biomedicine-Llama3-8B](https://huggingface.co/instruction-pretrain/medicine-Llama3-8B)
- 通用指令增强语料库:[general-instruction-augmented-corpora](https://huggingface.co/datasets/instruction-pretrain/general-instruction-augmented-corpora)
- 领域专属指令增强语料库(未包含金融数据以规避伦理问题):[medicine-instruction-augmented-corpora](https://huggingface.co/datasets/instruction-pretrain/medicine-instruction-augmented-corpora)
## 基于原始文本合成指令的多任务微调
我们对语言模型进行多任务微调,以构建能够从任意原始文本生成指令-回复对的基于上下文的指令合成器。整体微调与推理框架如下:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/0889QyG59QM3rPeZlcTzZ.png" width="700">
</p>
我们对微调数据进行了精心筛选与整理,以使指令合成器能够泛化至未见数据。因此,在推理阶段,我们可直接使用该指令合成器基于原始预训练语料库生成指令-回复对。数据集概览如下:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/66711d2ee12fa6cc5f5dfc89/140_he6XwK4QLv7Kf-Uye.png" width="700">
</p>
在微调阶段,输入至合成器的每个序列会拼接多个示例,所有示例均来自同一数据集。此外,我们仅在指令-回复对上计算微调损失。
例如,将某一数据集的样本整理为我们所需的微调格式的代码如下:
python
from datasets import load_dataset
# 模板
context_template = ' <CON> {context} </CON>'
QA_template = '<QUE> {question} <ANS> {answer} </END>'
delimiter = '
'
bos_token = '<s>' # 将此处替换为你的合成器基础模型的起始令牌(BOS token),例如Llama2为"<s>",Llama3为"<|begin_of_text|>"
eos_token = '</s>' # 将此处替换为你的合成器基础模型的结束令牌(EOS token),例如Llama2为"</s>",Llama3为"<|end_of_text|>"
def cook_context(raw_context):
"""格式化上下文。"""
return bos_token + context_template.replace('{context}', raw_context) + delimiter
def cook_instruction_response_pairs(QA_list):
"""格式化下游任务的指令(Q)-回复(A)对。"""
ins_res_list = []
for qa_entry in QA_list:
qa = QA_template.replace('{question}', qa_entry['Q']).replace('{answer}', qa_entry['A'])
ins_res_list.append(qa)
return delimiter.join(ins_res_list) + eos_token
# 以SQuAD为例
# # 完整数据集列表如下:
# # datasets = ['squad', 'TopiOCQA', 'HotpotQA', 'WikiTableQuestions' 'Quac', 'QED', 'FairyTaleQA', 'mctest', 'NarrativeQA', 'race', 'race_c', 'ReClor', 'LogiQA', 'AQUA_RAT_yes_opt', 'TriviaQA', 'CosmosQA', 'ECQA', 'NLQuAD', 'NewsQA', 'tweet_qa', 'quail', 'dream', 'multirc', 'ROPES', 'QuaRTz', 'CoQA', 'DoQA', 'qasper' 'PubMedQA_no_opt', 'PubMedQA_yes_opt', 'COVID_QA', 'ConvFinQA', 'SpartQA', 'bAbI', 'QASC']
dataset_name = 'squad'
ds = load_dataset(
"instruction-pretrain/ft-instruction-synthesizer-collection",
data_files=f"{dataset_name}/shard/*jsonl",
split='train'
)
# 收集所有用于微调的输入与输出
results = []
for entry in ds:
text = cook_context(entry['context'])
ins_res_pairs = cook_instruction_response_pairs(entry['QA_list'])
results.append({'input': text, 'output': ins_res_pairs})
# 打印格式化后的示例
print(f'{results[0]["input"]}{results[0]["output"]}')
# 注意:在后续微调中,我们将来自同一数据集的多个此类输入-输出对拼接为单个序列,
# 并仅在输出部分计算损失
**2024/8/30 更新**:由于我们在格式化数据时已显式添加了起始令牌与结束令牌,因此在分词时无需再次添加。例如,分词方式应为:`input_token_ids = tokenizer(input, add_special_tokens=False, **kwargs).input_ids`
## 授权信息
本数据集集合收录了来自多个来源的数据集,请确保遵守其各自的授权协议。
## 引用
若您的工作受益于本项目,请引用我们的论文:
[指令预训练](https://huggingface.co/papers/2406.14491)(EMNLP 2024)
bibtex
@article{cheng2024instruction,
title={Instruction Pre-Training: Language Models are Supervised Multitask Learners},
author={Cheng, Daixuan and Gu, Yuxian and Huang, Shaohan and Bi, Junyu and Huang, Minlie and Wei, Furu},
journal={arXiv preprint arXiv:2406.14491},
year={2024}
}
[适配大语言模型至领域](https://huggingface.co/papers/2309.09530)(ICLR 2024)
bibtex
@inproceedings{
cheng2024adapting,
title={Adapting Large Language Models via Reading Comprehension},
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=y886UXPEZ0}
}
提供机构:
maas
创建时间:
2024-06-26
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于微调基于上下文的指令合成器的数据集合,旨在生成指令-响应对以增强原始语料库,支持指令预训练框架。它通过多样化的微调数据促进合成器的泛化能力,并与相关研究论文相关联。
以上内容由遇见数据集搜集并总结生成


