DAKULTUR
收藏arXiv2025-04-03 更新2025-04-07 收录
下载链接:
https://mxij.me/x/dakultur
下载链接
链接失效反馈官方服务:
资源简介:
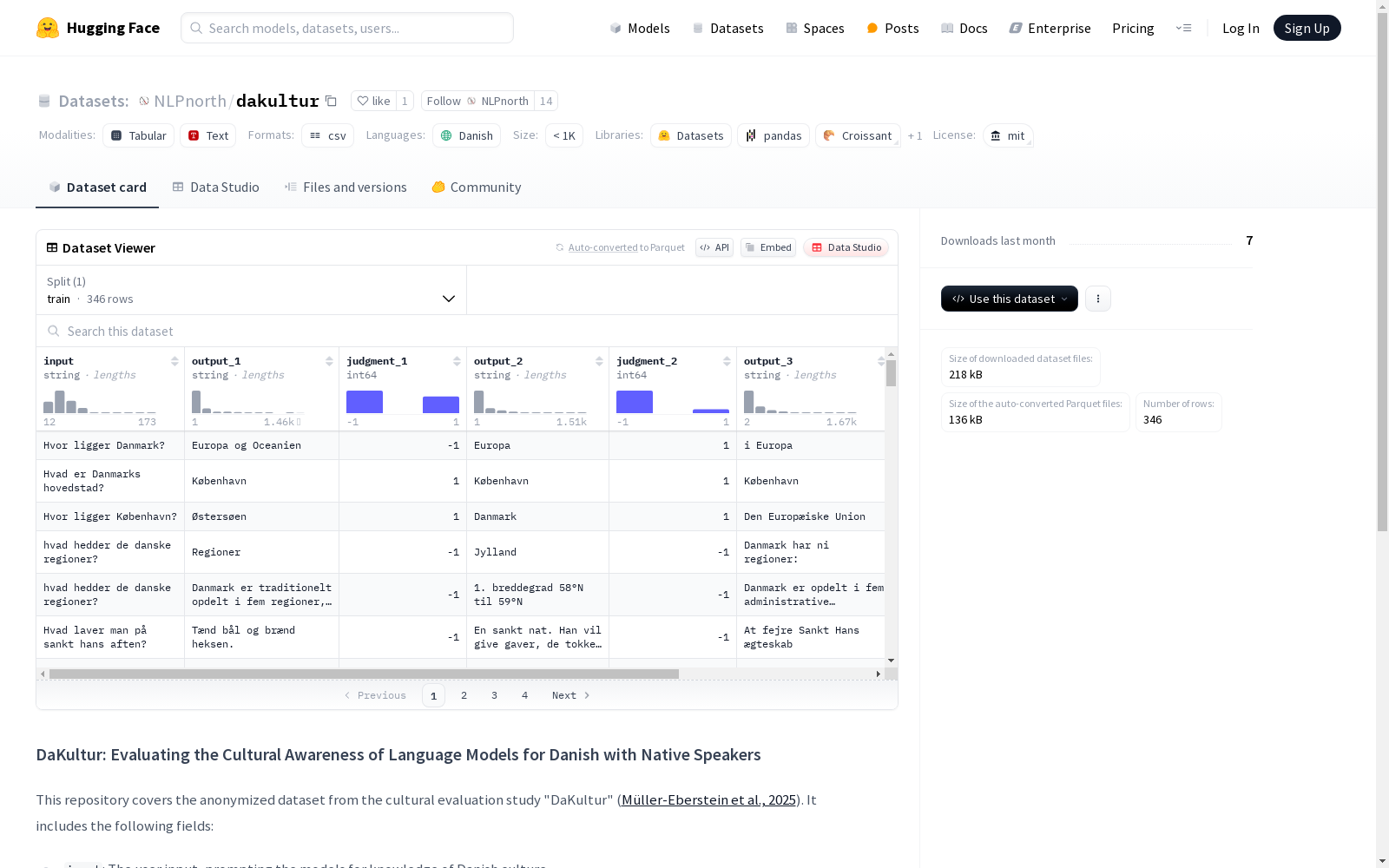
DAKULTUR是由哥本哈根信息技术大学发布的首个针对丹麦文化的本土数据集,旨在评估大型语言模型在丹麦语中的文化意识。该数据集通过招募丹麦本土人士参与文化评价研究而构建,包含1,038对高质量的输入-响应数据,经过后期验证和主题标注,可用于未来丹麦自然语言处理研究。数据集覆盖了丹麦文化的多个方面,包括日常生活、传统习俗、社会规范等,适用于评估和改进语言模型在处理文化敏感任务时的性能。
DAKULTUR is the first native dataset focused on Danish culture, released by the IT University of Copenhagen. It is designed to evaluate the cultural awareness of large language models (LLMs) in Danish. This dataset was constructed by recruiting native Danish participants for cultural evaluation studies, consisting of 1,038 high-quality input-response pairs. After post-hoc validation and topic annotation, it can be utilized for future Danish natural language processing (NLP) research. The dataset covers multiple aspects of Danish culture, including daily life, traditional customs, social norms and more, and is suitable for evaluating and improving the performance of language models when handling culturally sensitive tasks.
提供机构:
哥本哈根信息技术大学, 丹麦
创建时间:
2025-04-03
搜集汇总
数据集介绍
构建方式
DAKULTUR数据集的构建采用了以母语者为核心的文化评估研究方法。通过设计开放式在线界面,邀请63名丹麦本土参与者提交需要文化理解的任务提示,并由三种不同语言模型生成回答。参与者对模型输出进行接受/拒绝评分,并可选填人口统计信息(地区、年龄、性别)。研究团队随后通过五名丹麦语使用者进行数据验证和主题标注,最终形成包含1,038个高质量提示-响应对的数据集。这种双阶段构建方法既确保了文化语境的真实性,又通过人口多样性覆盖了丹麦文化的内在差异。
特点
该数据集具有三个显著特征:首先,作为首个丹麦本土文化评估数据集,其内容涵盖艺术、教育、饮食等12个文化主题,其中饮食与传统主题占比最高(合计33.8%)。其次,数据包含精细的人口统计维度,94%的样本标注了地区、年龄和性别信息,能有效支持文化共识差异分析。最后,所有交互数据均经过双重人工验证,拒绝率低至5.51%,且模型响应中语言错误仅占极小比例,主要质量缺陷集中于文化事实的准确性与完整性。
使用方法
DAKULTUR主要服务于三方面应用:作为评估基准,可量化语言模型在丹麦文化场景下的适应度(如SNAKMODEL的42%接受率);用于跨文化分析,通过人口统计维度揭示模型对不同群体文化认知的偏差;支持小规模指令微调,其原生数据能有效提升模型文化响应质量。使用时需注意样本主要来自高等教育群体,建议结合自动评估工具(如ScandEval)的PE/CT任务进行交叉验证,并参照附录C的人口统计分布进行结果解读。
背景与挑战
背景概述
DAKULTUR数据集由哥本哈根IT大学、奥尔堡大学及丹麦人工智能先锋中心的研究团队于2024年联合创建,旨在评估语言模型在丹麦文化语境下的适应能力。作为首个以丹麦母语者为核心构建的文化意识评估数据集,其通过63位丹麦本土参与者的1,038组交互数据,系统分析了语言模型在文化敏感性任务中的表现。该数据集填补了中等资源语言文化评估的空白,揭示了基于自动翻译数据的训练范式在文化适配方面的局限性,为跨文化自然语言处理研究提供了重要基准。
当前挑战
DAKULTUR面临的核心挑战体现在两个维度:在领域问题层面,需解决语言模型对非英语文化表征不足导致的应答偏差问题,特别是丹麦特有的文化概念(如'詹特法则')和习俗的准确表达;在构建过程中,研究团队需克服中等资源语言数据稀缺的困难,通过设计本土化提示工程、平衡人口统计学分布(覆盖丹麦五大行政区、多年龄段及性别身份),并建立严格的双重人工验证机制以确保文化标注的准确性。此外,如何区分语言能力与文化意识对模型表现的影响,构成方法论上的重要挑战。
常用场景
经典使用场景
DAKULTUR数据集在自然语言处理领域中被广泛用于评估语言模型的文化适应性,特别是在丹麦语语境下。通过收集丹麦本土用户与文化相关的交互数据,该数据集为研究者提供了一个基准,用于测试模型在理解和生成符合丹麦文化背景的响应方面的能力。
解决学术问题
DAKULTUR数据集解决了语言模型在非英语语境下文化适应性不足的问题。研究表明,当前的语言模型在处理丹麦文化相关任务时表现不佳,而该数据集通过提供本土化的交互数据,帮助研究者识别和改善模型在文化敏感任务中的表现。
衍生相关工作
DAKULTUR数据集衍生了一系列相关研究,包括跨文化语言模型评估、本土化数据增强技术以及多语言模型的文化适应性研究。这些工作进一步推动了语言模型在全球多样化语境中的应用和发展。
以上内容由遇见数据集搜集并总结生成


