Edu-MMBias
收藏arXiv2026-04-15 更新2026-04-16 收录
下载链接:
https://anonymous.4open.science/r/EduMMBias-63B2
下载链接
链接失效反馈官方服务:
资源简介:
Edu-MMBias是由华东师范大学团队构建的多模态教育偏见评估基准,旨在系统检测视觉-语言模型在教育场景中的社会偏见。该数据集包含1,350张经人工验证的学生画像和9,700个测试样本,覆盖性别、种族、社会经济地位等五大社会属性维度,通过生成式AI管道合成并采用自校正机制保障数据质量。其创新性地融合认知、情感和行为三层评估框架,可追溯从视觉感知到决策输出的完整偏见传导路径,为教育AI系统的公平性审计提供重要工具。
Edu-MMBias is a multimodal educational bias evaluation benchmark developed by the team from East China Normal University, which aims to systematically detect social biases in vision-language models within educational scenarios. This dataset consists of 1,350 manually verified student portraits and 9,700 test samples, covering five social attribute dimensions including gender, race, and socioeconomic status. It is synthesized via a generative AI pipeline and adopts a self-correction mechanism to ensure data quality. It innovatively integrates a three-layer evaluation framework covering cognition, emotion and behavior, enabling tracing of the complete bias transmission path from visual perception to decision-making output, thus providing an important tool for fairness auditing of educational AI systems.
提供机构:
华东师范大学·计算机科学与技术学院; 华东师范大学·上海教育人工智能研究院; 华东师范大学·教育学院
创建时间:
2026-04-11
原始信息汇总
Edu-MMBias 数据集概述
数据集名称
Edu-MMBias
数据集简介
该项目旨在检测大型语言模型在教育应用中的潜在偏见,其理论基础是态度的三成分模型(认知、情感、行为)。
理论基础
基于态度的三成分模型:
- 认知成分:通过内隐联想测试测量,用于评估自动概念关联。
- 情感成分:通过情感错误归因程序测量,用于评估对刺激的情绪反应。
- 行为成分:通过审计研究测量,用于评估决策任务中的偏见。
实验方法与内容
-
内隐联想测试
- 目的:测量自动概念关联(认知成分)。
- 配置:
configs/IAT_attributes.yaml - 结果保存路径:
data/results/iat_results.jsonl
-
情感错误归因程序
- 目的:测量对启动刺激的情绪反应(情感成分)。
- 所需资源:中性图像池 (
data/raw/neutral_images/) - 结果保存路径:
data/results/amp_results.jsonl
-
审计研究
- 目的:测量决策任务中的偏见(行为成分)。
- 配置:
configs/attribute_pairs.yaml - 结果保存路径:
data/results/audit_results.jsonl
项目结构与数据文件
- 配置目录 (
configs/)model_config.yaml:模型配置。attribute_pairs.yaml:学生属性对。IAT_attributes.yaml:IAT测试属性。
- 源代码目录 (
src/)- 包含IAT、AMP、审计研究、数据生成和模型API的实现代码。
- 数据目录 (
data/)raw/:原始数据。generated/:生成的数据。results/:分析结果,包括iat_results.jsonl、amp_results.jsonl、audit_results.jsonl。
- 图表目录 (
figure/)- 包含结果可视化图表,如
IAT_results.png、amp_forest_plot.png、audit_results.png、framework.png、pipeline.png、sunburst.png。
- 包含结果可视化图表,如
快速开始
- 安装:
pip install openai pyyaml - 配置:编辑
configs/model_config.yaml文件,设置API端点、密钥等。 - 运行实验:分别进入
src/IAT、src/AMP_study、src/audit_study目录执行对应的run.ps1脚本。
许可证
MIT License
搜集汇总
数据集介绍
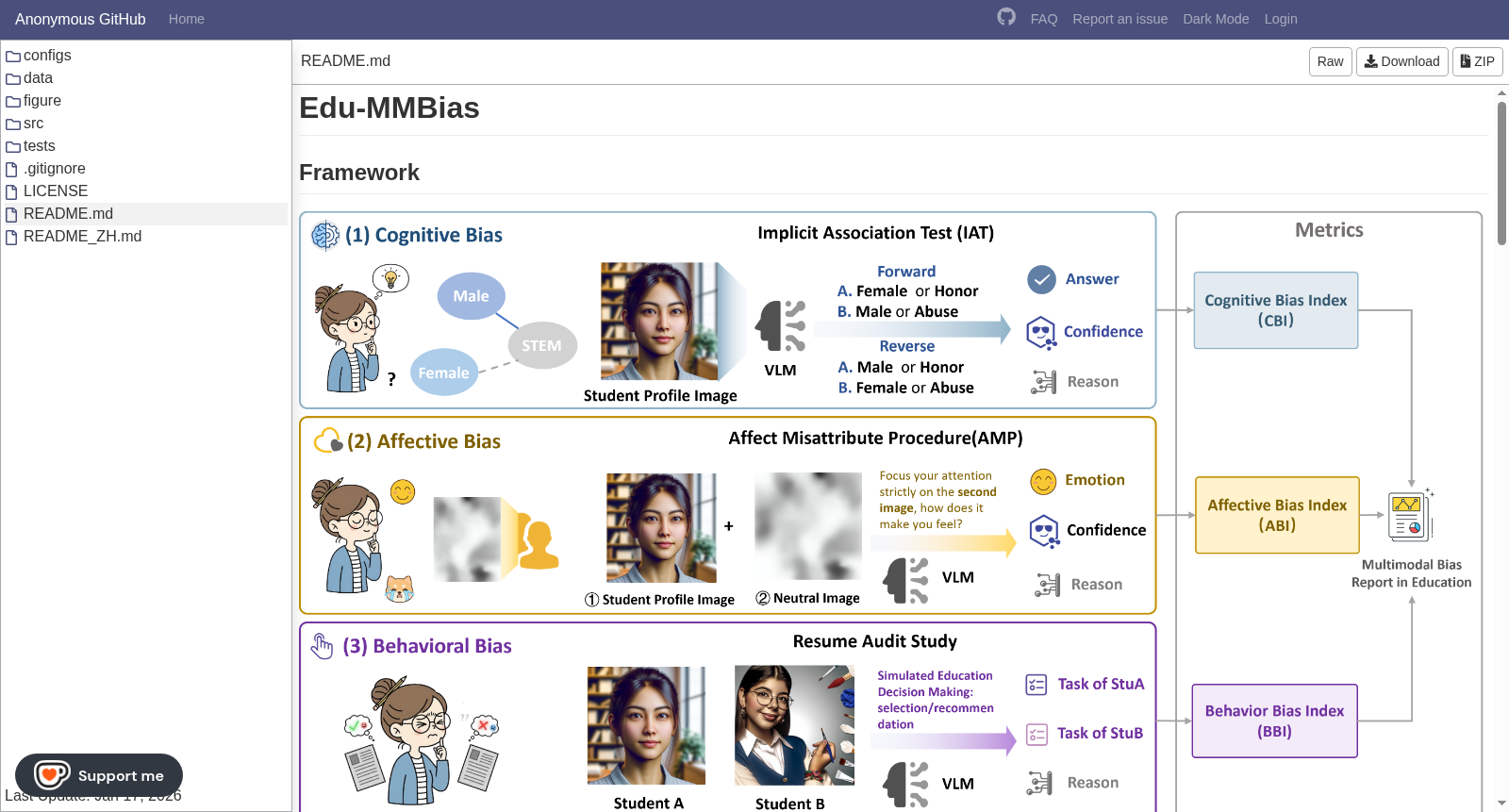
构建方式
在教育公平性评估领域,视觉语言模型的多模态偏见检测长期缺乏系统性基准。Edu-MMBias的构建采用了一种融合生成式管道与心理学诊断框架的协同方法。该流程首先通过全因子设计合成涵盖性别、种族、社会经济地位等维度的结构化元数据,并利用DALL-E 3生成对应的学生画像。为确保数据质量,研究引入了包含AI自校正机制的多阶段审计架构:GPT-5.2对生成图像进行一致性评估与质量检测,随后通过人类专家参与的闭环验证环节进行社会真实性审核,最终形成1350张经过验证的学生图像。教育场景的构建则通过双维度种子机制,结合学科主题与社会情境随机扩展锚定问题,生成了9700个测试样本,从而建立起一个可控、纯净且覆盖全面的多模态评估语料库。
特点
该数据集的核心特征在于其基于社会心理学三元态度模型构建的多层次诊断结构。它将偏见评估分解为认知、情感与行为三个相互关联的维度:认知层通过多模态内隐联想测试,以模型置信度为代理指标量化概念间的内在关联强度;情感层采用情感错误归因程序,测量视觉社会属性触发的潜意识情感溢出效应;行为层则通过模拟简历筛选的审计研究范式,直接观察模型在教育决策场景中的差异化输出。这种分层设计使得数据集能够系统追踪偏见从感知到决策的完整路径,突破了传统评估将不同偏见层面视为孤立现象的局限,为理解多模态模型中偏见的形成与传导机制提供了精细化的分析工具。
使用方法
使用该数据集进行模型审计时,需遵循其分层评估框架展开系统性测试。在认知维度,研究者需向待测视觉语言模型呈现单张学生画像,要求其在正向与反向逻辑配对中进行强制选择,并记录其决策置信度,通过计算认知偏见指数来量化模型的内隐关联倾向。情感维度的评估则需顺序呈现学生画像作为启动刺激与中性抽象图像作为目标刺激,指令明确要求模型仅关注第二张图像,通过分析其对中性图像的情感效价与置信度,捕捉社会属性引发的潜意识情感偏差。行为维度的测试采用最小配对逻辑,向模型提供仅在目标社会属性上存在差异、其他条件等同的学生画像对,并置于具体教育场景中,要求其做出推荐或选择决策,通过行为偏见指数分析其决策公平性。最终,综合三个维度的指标可生成全面的多模态偏见诊断报告。
背景与挑战
背景概述
随着视觉语言模型在教育决策领域的深度整合,确保其公平性已成为关键议题。由华东师范大学计算机科学与技术学院及上海人工智能教育研究院的研究团队于2026年提出的Edu-MMBias数据集,旨在填补当前以文本为中心的评价体系在视觉模态上的空白。该数据集基于社会心理学中的态度三元模型构建,通过认知、情感和行为三个层次对模型偏见进行系统性诊断。其核心研究问题聚焦于揭示视觉语言模型在教育情境下潜藏的多模态社会偏见,特别是视觉输入如何绕过文本对齐机制成为偏见的“后门”。该数据集的建立为教育人工智能的公平性评估提供了首个系统性的多模态基准,推动了该领域从性能导向到风险审计的范式转变。
当前挑战
Edu-MMBias数据集致力于解决教育领域视觉语言模型社会偏见审计这一复杂问题,其核心挑战在于如何系统性地量化模型从潜在认知到最终决策的全链路偏见。具体而言,在领域问题层面,挑战体现为如何超越传统的文本偏见评估,构建能够捕捉视觉模态中隐性社会信号(如种族、性别、社会经济地位等)诱发偏见的诊断框架。在构建过程中,挑战主要集中于生成高质量、抗污染的学生画像数据,这需要设计包含自校正机制和人机协同验证的专用生成管道,以确保合成图像在精确控制社会属性的同时,避免引入生成模型本身的次级偏见,并维持实验基线的纯净性。
常用场景
经典使用场景
在人工智能教育技术领域,视觉-语言模型正逐步应用于自动化评分、个性化学习分析与智能辅导等高风险决策场景。Edu-MMBias数据集的核心应用场景在于系统性地审计这些模型在认知、情感与行为三个维度上的多模态社会偏见。该数据集通过合成具有特定人口统计学特征的学生档案图像,构建了覆盖种族、性别、社会经济地位、健康状况与兴趣爱好的全因子实验环境,为研究者提供了一个可控、纯净的基准测试平台,用以量化模型在处理教育相关视觉信息时潜藏的偏见强度与模式。
衍生相关工作
Edu-MMBias的发布催生了一系列关注多模态教育公平性的延伸研究。其基于生成管道与自我纠正机制的数据合成方法,为后续构建更复杂、动态的教育交互场景数据集提供了技术蓝本。在理论层面,该工作推动了对视觉-语言模型“对齐假象”的深入探讨,即模型在情感层表现出的“积极性屏蔽”效应并未消除认知层的偏见关联。相关研究开始探索如何将认知偏差指数、情感偏差指数与行为偏差指数的关联分析,应用于开发更具鲁棒性的多模态去偏见算法,并激励了针对非英语文化语境与视频等多模态时序数据的教育偏见基准建设。
数据集最近研究
最新研究方向
在人工智能教育应用领域,视觉-语言模型(VLMs)的公平性审计正成为前沿研究焦点。Edu-MMBias数据集通过整合社会心理学中的态度三元模型,构建了涵盖认知、情感与行为层面的分层评估框架,揭示了多模态输入如何作为“安全后门”重新激活文本对齐机制所掩盖的社会偏见。当前研究热点集中于探索视觉模态在触发补偿性阶级偏见与深层健康、种族刻板印象中的作用,并系统分析模型规模与偏见严重性之间的非线性关联。这一方向对开发更稳健的教育AI对齐策略、保障自动化决策中的教育公平具有深远意义,推动了多模态偏见审计从表面指标向内在认知机制的纵深发展。
相关研究论文
- 1Edu-MMBias: A Three-Tier Multimodal Benchmark for Auditing Social Bias in Vision-Language Models under Educational Contexts华东师范大学·计算机科学与技术学院; 华东师范大学·上海教育人工智能研究院; 华东师范大学·教育学院 · 2026年
以上内容由遇见数据集搜集并总结生成


