P-MMEval
收藏P-MMEval: 多语言多任务并行基准
简介
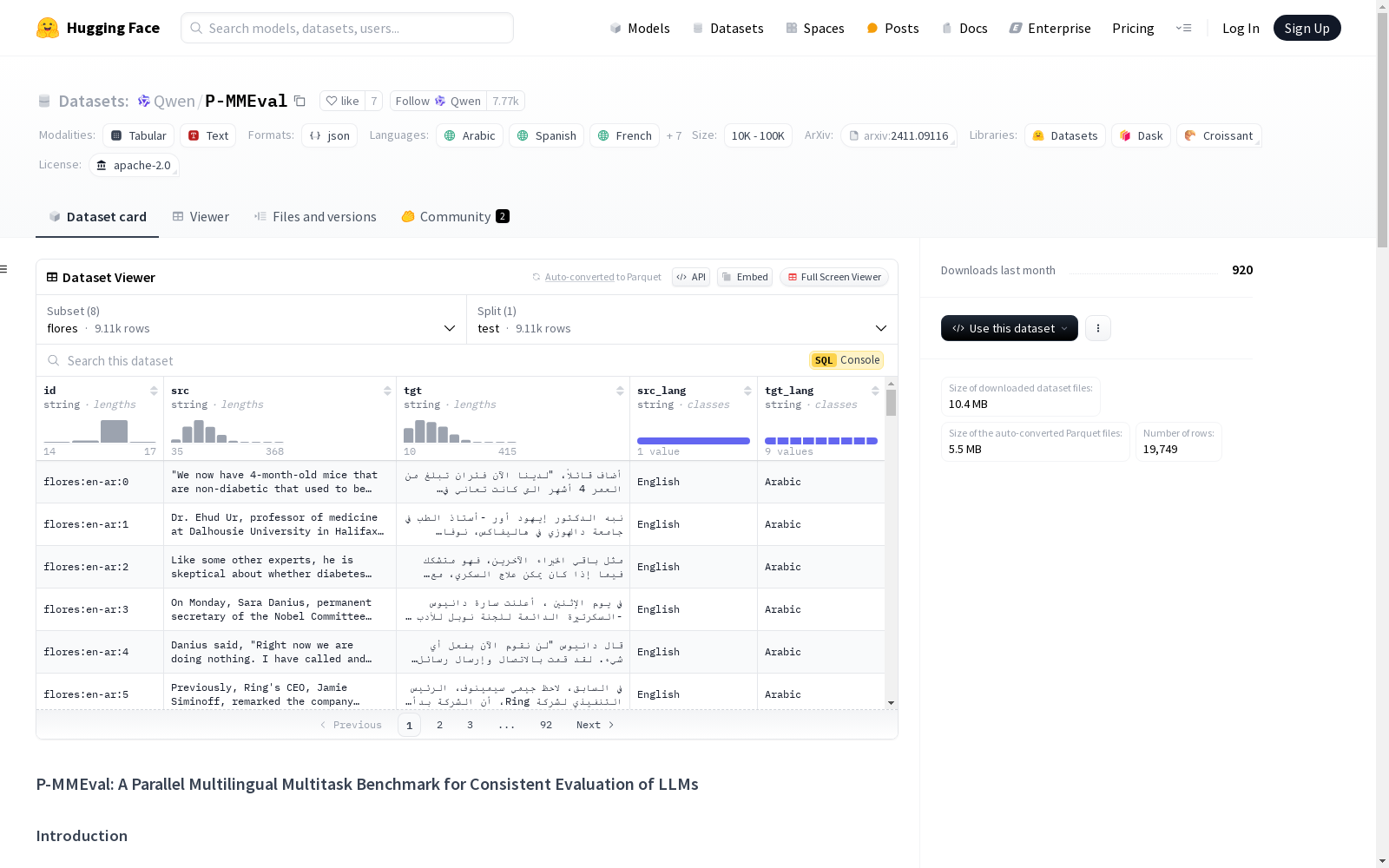
P-MMEval 是一个多语言基准,涵盖了有效的基本和能力专业化数据集。我们扩展了现有的基准,确保所有数据集之间的一致语言覆盖,并在多种语言之间提供并行样本,支持多达 10 种语言(即英语、中文、阿拉伯语、西班牙语、日语、韩语、泰语、法语、葡萄牙语、越南语)。因此,P-MMEval 有助于对多语言能力进行整体评估,并进行跨语言可转移性的比较分析。
支持的语言
- 阿拉伯语
- 西班牙语
- 法语
- 日语
- 韩语
- 葡萄牙语
- 泰语
- 越南语
- 英语
- 中文
支持的任务
- flores-200
- humaneval-xl
- mgsm
- mhellaswag
- mifeval
- mlogiqa
- mmmlu
- xnli
主要结果
除 LLaMA3.2 系列外,所有模型的多语言能力随着模型规模的增加而提高。LLaMA3.2-1B 和 LLaMA3.2-3B 在指令跟随能力上表现较差,导致答案提取的失败率较高。此外,Qwen2.5 在理解和能力专业化任务上表现出色,而 Gemma2 在生成任务上表现优异。闭源模型通常优于开源模型。
引用
如果发现此数据集有帮助,请引用以下论文:
@misc{zhang2024pmmevalparallelmultilingualmultitask, title={P-MMEval: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLMs}, author={Yidan Zhang and Yu Wan and Boyi Deng and Baosong Yang and Haoran Wei and Fei Huang and Bowen Yu and Junyang Lin and Fei Huang and Jingren Zhou}, year={2024}, eprint={2411.09116}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2411.09116}, }