integer32/oasst1-ru
收藏Hugging Face2024-06-16 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/integer32/oasst1-ru
下载链接
链接失效反馈官方服务:
资源简介:
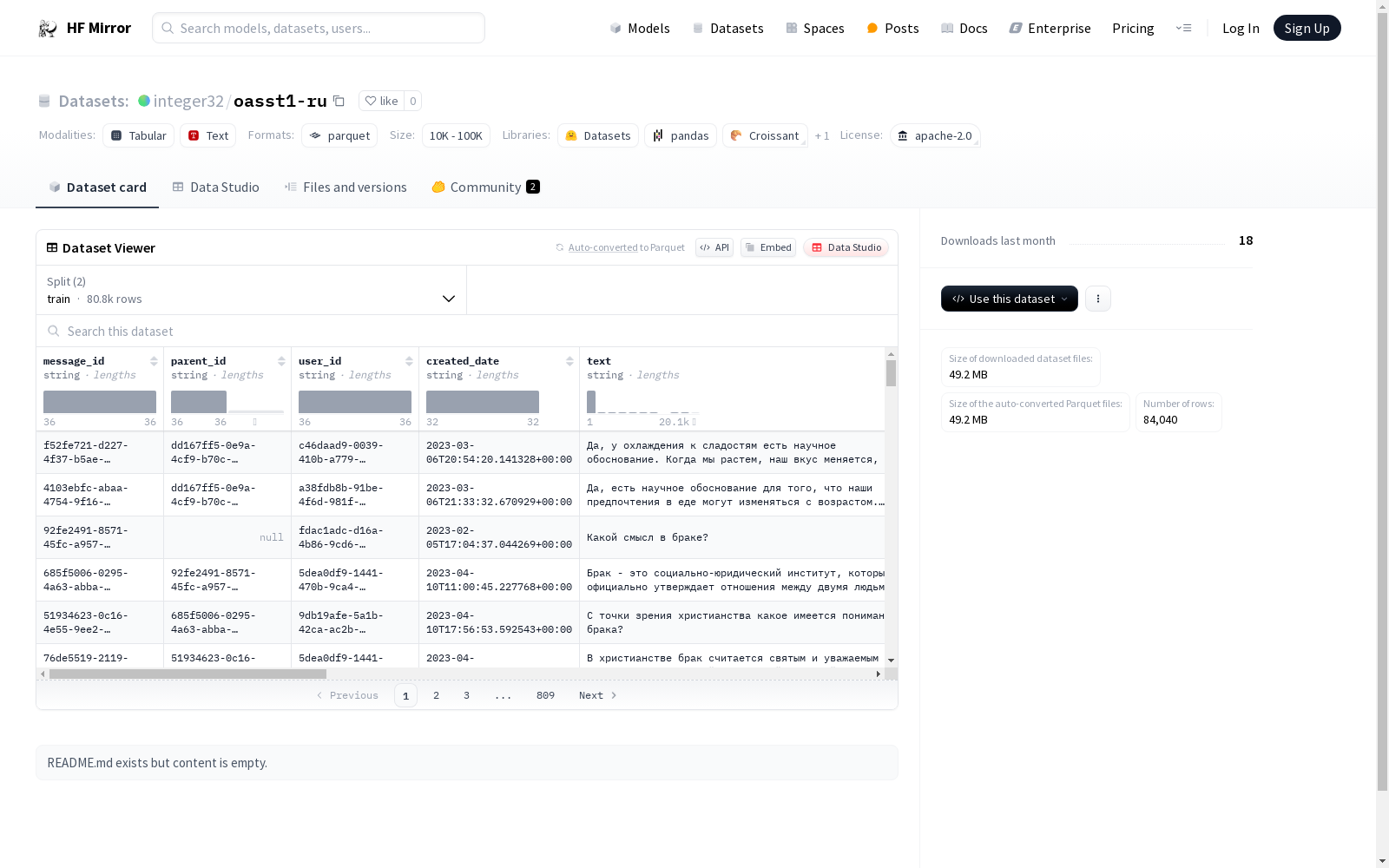
该数据集包含多个字段,如消息ID、父消息ID、用户ID、创建日期、文本内容、角色、语言、审核次数、审核结果、删除状态、排名、是否为合成数据、模型名称等。此外,还包括嵌套结构如detoxify(包含身份攻击、侮辱、淫秽、严重毒性、性暴露、威胁和毒性评分)、emojis(表情符号的数量和名称)和labels(标签的数量、名称和值)。数据集分为训练集和验证集,训练集包含80824个样本,验证集包含3216个样本。
The dataset contains multiple fields such as message ID, parent message ID, user ID, creation date, text content, role, language, review count, review result, deletion status, rank, whether it is synthetic data, model name, etc. Additionally, it includes nested structures such as detoxify (containing identity attack, insult, obscene, severe toxicity, sexual explicit, threat, and toxicity scores), emojis (count and names of emojis), and labels (count, names, and values of labels). The dataset is divided into training and validation sets, with the training set containing 80,824 samples and the validation set containing 3,216 samples.
提供机构:
integer32
原始信息汇总
数据集概述
数据集信息
- 许可证: Apache 2.0
- 数据集大小: 137,723,958 字节
- 下载大小: 49,242,048 字节
特征
- message_id: 字符串类型
- parent_id: 字符串类型
- user_id: 字符串类型
- created_date: 字符串类型
- text: 字符串类型
- role: 字符串类型
- lang: 字符串类型
- review_count: 64位整数类型
- review_result: 布尔类型
- deleted: 布尔类型
- rank: 64位浮点数类型
- synthetic: 布尔类型
- model_name: 空值类型
- detoxify: 结构体类型
- identity_attack: 64位浮点数类型
- insult: 64位浮点数类型
- obscene: 64位浮点数类型
- severe_toxicity: 64位浮点数类型
- sexual_explicit: 64位浮点数类型
- threat: 64位浮点数类型
- toxicity: 64位浮点数类型
- message_tree_id: 字符串类型
- tree_state: 字符串类型
- emojis: 结构体类型
- count: 序列化的64位整数类型
- name: 序列化的字符串类型
- labels: 结构体类型
- count: 序列化的64位整数类型
- name: 序列化的字符串类型
- value: 序列化的64位浮点数类型
数据分割
- validation:
- 样本数: 3,216
- 字节数: 5,519,713
- train:
- 样本数: 80,824
- 字节数: 132,204,245
配置
- config_name: default
- 数据文件:
- validation: data/validation-*
- train: data/train-*
- 数据文件:
搜集汇总
数据集介绍
构建方式
integer32/oasst1-ru数据集的构建,是通过收集包含用户交互信息的文本数据,并对其进行结构化处理。数据集涵盖了消息ID、父ID、用户ID、创建日期、文本内容、角色、语言、评论计数、评论结果、是否删除、排名、是否合成等多个维度信息,同时还包含了针对文本的毒性评分,如身份攻击、侮辱、粗俗、严重毒性、性 explicit、威胁和毒性等指标。此外,数据集还记录了消息树ID、树状态、表情符号计数及名称,以及标签的计数、名称和值。该数据集分为训练集和验证集两部分,以支持机器学习模型的训练和评估。
特点
integer32/oasst1-ru数据集的特点在于其内容的多元化和信息的详尽性。不仅包含了基本的用户交互文本和元数据,还提供了文本毒性的量化评分,这为研究文本的负面倾向和自动审核系统提供了丰富的数据资源。数据集的结构化设计使得研究者能够方便地进行数据分析和模型构建。此外,数据集的规模适中,便于在合理的时间内进行处理和学习。
使用方法
使用integer32/oasst1-ru数据集时,用户首先需要根据研究需求选择合适的split,例如训练集或验证集。数据集以Apache-2.0许可证开源,可通过指定的路径下载相应的数据文件。在数据处理过程中,用户可以依据数据集提供的字段进行文本分析、毒性评估、情感分析等任务,同时也可以利用这些数据来训练和优化机器学习模型,以提高模型的性能和准确性。
背景与挑战
背景概述
在自然语言处理领域,对话系统的质量评估与改进始终是核心研究问题之一。integer32/oasst1-ru数据集,诞生于近年来,由专业的研发团队精心构建,旨在为研究人员提供一个用于评估和改进对话系统质量的多元化资源。该数据集包含了大量的对话文本,涵盖了用户与系统间的交互信息,以及相关的元数据,如用户ID、创建时间、文本内容、角色、语言等。其详尽的标注信息,如评论计数、评论结果、删除状态、评分和毒性标签等,为研究提供了丰富的维度。该数据集在对话系统评估、毒性检测和文本质量提升等领域产生了广泛的影响,为相关研究提供了强有力的数据支撑。
当前挑战
尽管integer32/oasst1-ru数据集为对话系统研究提供了宝贵的资源,但在使用过程中也面临着诸多挑战。首先,如何准确识别和过滤对话中的毒性内容,以保护用户免受不良信息的影响,是一个持续的挑战。其次,数据集中存在的噪声和不一致性,如错误标注或重复数据,可能会对模型训练和评估造成干扰。此外,数据集的多样性和规模性要求在构建和存储过程中保持高效的数据管理,确保数据的质量和可用性。这些挑战不仅考验着研究人员的算法设计能力,也对其数据处理和系统评估提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域中,integer32/oasst1-ru数据集因其丰富的文本特征和元数据,成为对话系统评估与优化的经典资源。该数据集记录了用户间的对话及其伴随的各类属性,使得研究者能够深入探索对话的上下文和语境,进而提升对话系统的响应质量和准确性。
衍生相关工作
基于integer32/oasst1-ru数据集,学术界衍生出了一系列相关工作,包括对话系统的毒性检测模型、情感分析工具和对话质量评估框架等。这些研究不仅丰富了数据集的应用场景,也为对话系统的理论和实践发展提供了新的视角和方法论。
数据集最近研究
最新研究方向
integer32/oasst1-ru数据集作为自然语言处理领域的重要资源,近期研究主要聚焦于对话系统的质量评估与改进。学者们深入研究如何利用该数据集的多样化特征,如用户身份、对话时间、文本内容等,以提升对话生成模型在语境理解、情绪识别及毒性内容检测方面的能力。此外,该数据集在模型对俄罗斯语言处理的准确性提升方面具有显著意义,为理解复杂语境下的语言使用提供了新的视角。
以上内容由遇见数据集搜集并总结生成


