MedSSS-data
收藏Hugging Face2025-01-24 更新2025-01-25 收录
下载链接:
https://huggingface.co/datasets/pixas/MedSSS-data
下载链接
链接失效反馈官方服务:
资源简介:
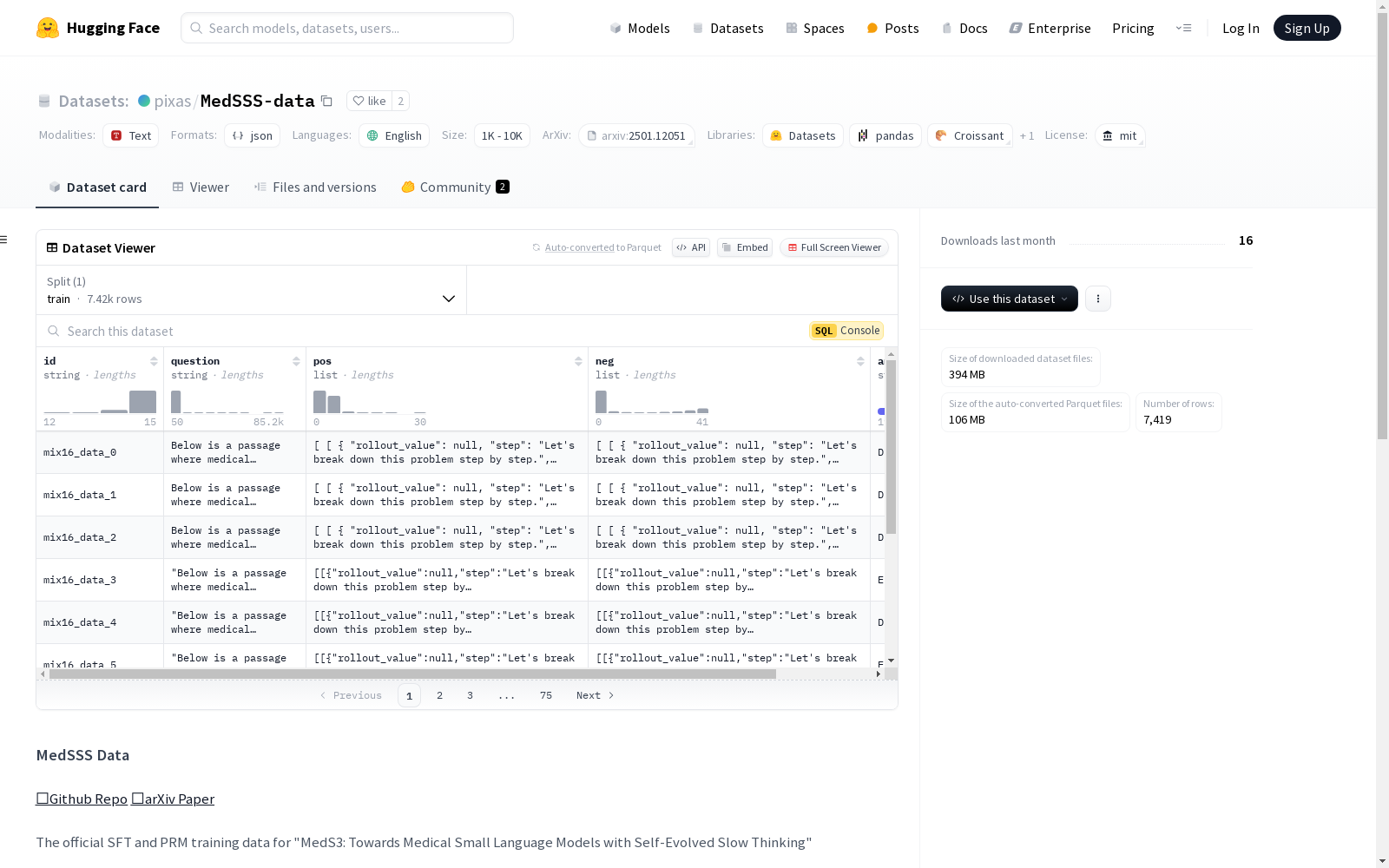
MedSSS数据集是一个合成的数据集,源自一个7.42k的种子数据集,涵盖了16个数据集和5种不同的医疗任务。该数据集通过蒙特卡洛树搜索进化,旨在提供高质量的监督微调(SFT)数据和过程奖励模型(PRM)数据。数据集涵盖了知识密集型问答(QA)、一般生物医学问答、医学自然语言推理(NLI)、长上下文问答和推理问答等多个文本领域,这些领域被精心选择以代表广泛的医学知识和推理,为训练医疗大型语言模型(LLMs)以及细粒度的医疗过程奖励模型提供了全面的基础。数据格式包括'pos'和'neg'两个字段,分别用于监督微调和过程奖励模型微调。每个实例包含多个轨迹,每个轨迹是一个列表,由多个字典项组成,每个字典项包含表示内部推理步骤的'step'字段和表示反向传播后的Q值的'value'字段。第三个值'rollout_value'是通过蒙特卡洛rollout获得的第一个值。
创建时间:
2025-01-20
搜集汇总
数据集介绍
构建方式
MedSSS-data数据集基于一个包含7.42k条初始数据的种子数据集构建而成,涵盖了16个不同数据集和5种多样化的医学任务。通过蒙特卡洛树搜索(Monte-Carlo Tree Search)技术,该数据集被进一步优化,旨在生成高质量的监督微调(SFT)数据和过程奖励模型(PRM)数据。数据来源广泛,涉及知识密集型问答、生物医学问答、医学自然语言推理、长上下文问答以及推理问答等多个领域,确保了数据集的多样性和代表性。
特点
MedSSS-data数据集的特点在于其结构化的数据格式,包含'pos'和'neg'两个字段,分别用于监督微调和过程奖励模型微调。每个数据实例由多个轨迹组成,每个轨迹包含多个推理步骤,每个步骤通过字典形式详细记录了推理过程、最终值以及首次蒙特卡洛展开值。这种设计不仅支持复杂的医学推理任务,还为模型提供了细粒度的奖励信号,有助于提升模型的推理能力和决策质量。
使用方法
使用MedSSS-data数据集时,用户可以通过解析每个实例的轨迹数据,提取推理步骤和对应的值进行模型训练。对于过程奖励模型的训练,建议将每个推理步骤通过'\n\n'连接,并在每个步骤前添加'Step k: '前缀,其中k表示步骤的索引。这种格式化的处理方式有助于模型更好地理解推理过程,并生成与MedSSS框架一致的过程奖励值。该数据集适用于医学领域的小型语言模型训练,尤其适合需要复杂推理和决策支持的场景。
背景与挑战
背景概述
MedSSS-data数据集由Pixas团队于2024年创建,旨在为医学领域的小型语言模型(Small Language Models, SLMs)提供高质量的监督微调(SFT)和过程奖励模型(PRM)训练数据。该数据集基于7.42k的种子数据集,通过蒙特卡洛树搜索(Monte-Carlo Tree Search)演化而来,涵盖了16个数据集和5种多样化的医学任务,包括知识密集型问答、生物医学问答、医学自然语言推理、长上下文问答以及推理问答。这些任务的设计旨在全面覆盖医学知识和推理的广泛领域,为医学语言模型的训练提供了坚实的基础。该数据集的发布标志着医学领域在小型语言模型训练数据方面的重大进展,为医学人工智能的发展提供了重要支持。
当前挑战
MedSSS-data数据集在构建和应用过程中面临多重挑战。首先,医学领域的复杂性和多样性要求数据集必须涵盖广泛的知识领域和推理任务,这对数据的多样性和质量提出了极高要求。其次,蒙特卡洛树搜索的引入虽然提升了数据的演化效率,但其计算成本较高,且需要精确控制搜索深度和广度以确保生成数据的合理性。此外,数据格式的设计需要兼顾监督微调和过程奖励模型的双重需求,这对数据结构的灵活性和可扩展性提出了挑战。最后,医学数据的隐私性和敏感性要求数据集在构建过程中严格遵守伦理规范,确保数据的匿名化和安全性。这些挑战共同构成了MedSSS-data数据集在医学人工智能领域应用的关键障碍。
常用场景
经典使用场景
MedSSS-data数据集在医学自然语言处理领域具有广泛的应用,尤其是在医学小语言模型的训练中。该数据集通过提供高质量的监督微调(SFT)数据和过程奖励模型(PRM)数据,帮助研究人员构建能够处理复杂医学推理任务的模型。其多样化的任务类型,如知识密集型问答、生物医学问答、医学自然语言推理等,使得该数据集成为训练具有深度推理能力的医学语言模型的理想选择。
解决学术问题
MedSSS-data数据集解决了医学语言模型训练中数据质量不足和任务多样性有限的问题。通过蒙特卡洛树搜索生成的合成数据,该数据集不仅提供了丰富的推理步骤和最终结果,还确保了数据的多样性和高质量。这种数据生成方法显著提升了模型在复杂医学推理任务中的表现,为医学自然语言处理领域的研究提供了强有力的支持。
衍生相关工作
MedSSS-data数据集的发布推动了多项相关研究工作的开展。基于该数据集,研究人员开发了多种医学小语言模型,如MedS3模型,这些模型在医学问答和推理任务中表现出色。此外,该数据集还激发了更多关于医学语言模型训练和推理过程优化的研究,进一步推动了医学自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


