dung3008/vqa-food-vietnamese
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/dung3008/vqa-food-vietnamese
下载链接
链接失效反馈官方服务:
资源简介:
---
configs:
- config_name: default
data_files:
- split: train
path: "train.jsonl"
- split: validation
path: "validation.jsonl"
- split: test
path: "test.jsonl"
---
提供机构:
dung3008
搜集汇总
数据集介绍
构建方式
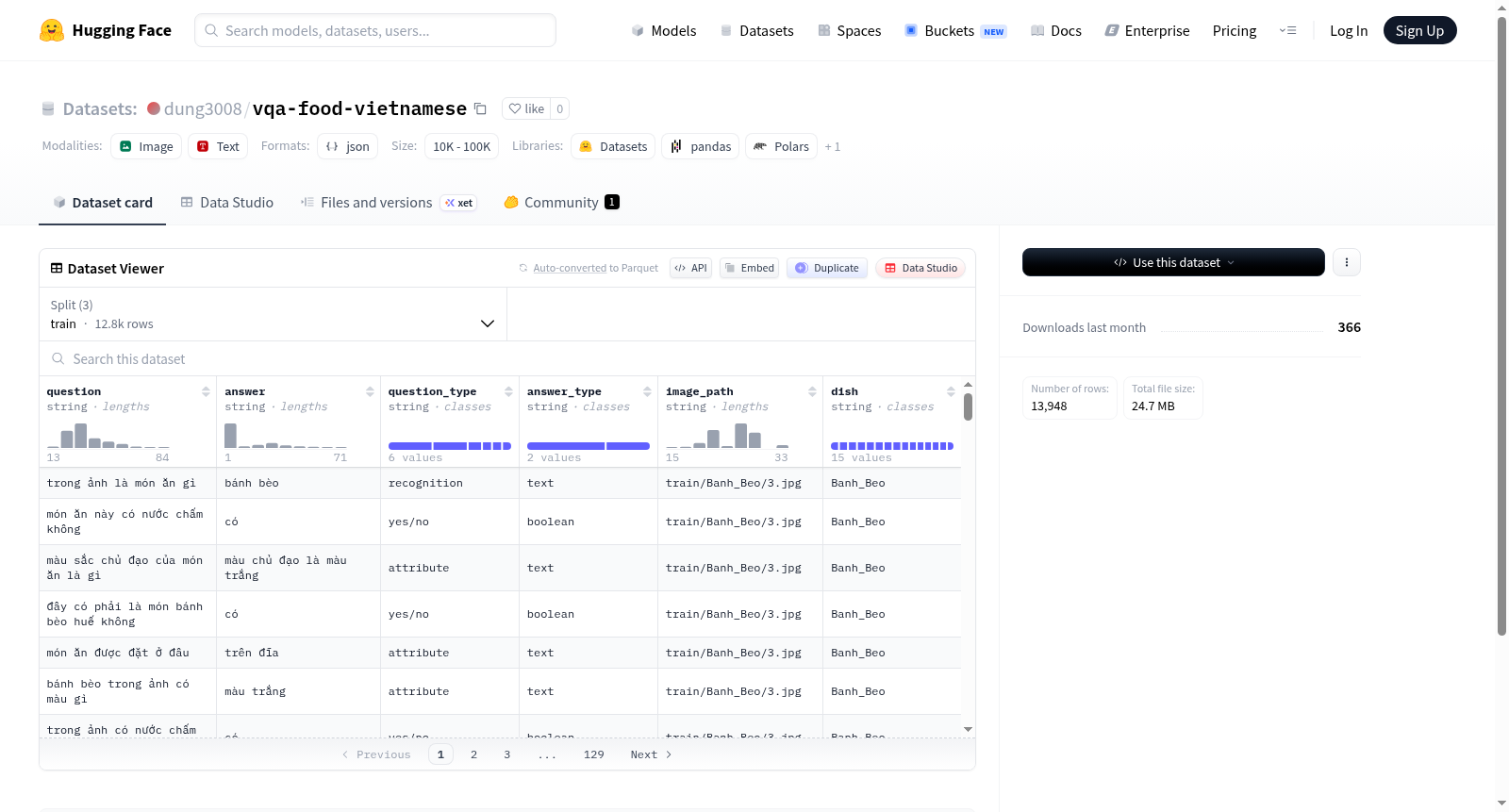
vqa-food-vietnamese数据集专为越南语美食领域的视觉问答任务而构建。其数据来源涵盖大量越南本地菜肴图像,每张图像均关联自然语言问题与对应的正确答案。数据集划分为训练集、验证集和测试集三部分,其中训练集包含12810个样本,验证集和测试集分别包含554和584个样本。每条样本记录由问题、答案、问题类型、答案类型、图像路径和菜肴名称六个字段组成,确保了多维度信息的完整性与结构化存储。原始数据以JSONL格式存储,便于高效加载与处理。
特点
该数据集聚焦于越南美食文化,具有鲜明的领域特色。其问题类型与答案类型的分列设计,支持对视觉问答任务进行细粒度分析,例如区分开放性问题与选择题等形式。图像路径字段指向真实的菜肴图片,使得模型训练能够直接利用视觉信息。菜肴名称字段则提供了语义标签,便于进行跨模态检索与分类研究。数据量虽不算庞大,但经过精心平衡的样本分布,使得该数据集成为越南语食品领域视觉问答研究的宝贵资源。
使用方法
使用该数据集时,首先通过HuggingFace的datasets库加载默认配置,即可获得train、validation和test三个子集。每个样本以字典形式呈现,包含question、answer等键值对。研究者可直接利用question字段作为输入文本,answer字段作为监督信号,结合image_path加载对应图像,构建多模态模型。此外,question_type与answer_type字段可用于过滤或分组分析,dish字段则支持按菜肴类别进行精细化训练与评估。推荐使用PyTorch或TensorFlow框架配合数据加载器,实现高效的批量训练与验证。
背景与挑战
背景概述
视觉问答(Visual Question Answering, VQA)作为连接计算机视觉与自然语言处理的前沿交叉领域,旨在使模型能够基于图像内容理解并回答自然语言问题。然而,现有VQA数据集多聚焦于通用场景或英文语境,针对特定领域及低资源语言的构建仍显不足。在此背景下,vqa-food-vietnamese数据集应运而生。该数据集由越南研究者开发,专注于越南美食领域,通过构建包含问题、答案、图像路径及菜品类别等多元信息的结构化数据,旨在推动多模态模型在越南语食品场景下的理解能力。数据集创建于近年,以其精细化的领域定位和语言特色,为低资源语言VQA研究提供了宝贵资源,尤其对东南亚美食文化的数字化理解具有重要推动作用。
当前挑战
该数据集面临的核心挑战首先来自领域定位的特殊性:越南美食种类繁多且地域差异显著,如何确保数据集涵盖菜品、烹饪方式及食材的多样性与代表性,避免模型产生地域性偏差,是解决越南语食品视觉问答任务的首要难题。其次,在构建过程中,收集高质量越南语自然问题与对应答案的标注成本高昂,且需兼顾问题类型(如颜色、数量、食材识别)的均衡分布。此外,每张图像需精确对齐菜品类别,并处理图像质量、光照条件及摆盘风格等视觉差异。最后,数据规模相对有限(训练集仅12810例),如何在小样本条件下训练出泛化能力强的多模态模型,成为技术落地的关键瓶颈。
常用场景
经典使用场景
在跨语言视觉问答(VQA)研究领域,vqa-food-vietnamese数据集为多模态理解与越南语自然语言处理的交叉探索提供了独特资源。该数据集聚焦于美食图像,包含问题、答案、图像路径及菜品标签等多维信息,经典地应用于训练和评估模型在越南语环境下对食物视觉内容的理解与推理能力。研究者可借助其丰富的问答对形式,推动面向特定领域与低资源语言的视觉对话系统发展,尤其适用于检验模型能否准确识别菜品、描述烹饪细节或回答饮食相关的文化知识。
解决学术问题
该数据集有力回应了低资源语言在视觉问答领域面临的标注数据匮乏与领域适配难题。通过提供越南语与烹饪图像紧密关联的结构化问答样本,它使得学界能够探索语言模型与视觉特征在非英语语境下的跨模态对齐方法。这一资源促进了面向特定文化场景的细粒度视觉理解研究,有助于揭示现有通用VQA模型在跨语言迁移时的局限性,并为构建更具包容性的多语言AI系统奠定了数据基础。
衍生相关工作
围绕vqa-food-vietnamese数据集,催生了若干富有启发性的衍生工作。研究者尝试将其与英文食物VQA数据集结合,进行跨语言知识蒸馏以提升模型在低资源场景下的表现。另有工作利用该数据集的菜品标签和问题类型信息,开发可解释性更强的视觉定位与属性预测模型。此外,部分工作以该数据集为基准,探索了数据增强策略对越南语多模态问答效果的改进,推动了小样本学习与领域自适应技术在美食领域的应用边界。
以上内容由遇见数据集搜集并总结生成


