CXMArena
收藏arXiv2025-05-14 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/sprinklr-huggingface/CXM_Arena
下载链接
链接失效反馈官方服务:
资源简介:
CXMArena是一个大型合成基准数据集,旨在评估在真实客户体验管理(CXM)场景中人工智能的性能。数据集由Sprinklr公司创建,模拟了品牌客户体验管理实体,包括产品规格、问题分类法和呼叫中心对话等知识文章。数据集包含五个重要的操作任务:知识库精炼、意图预测、代理质量遵守、文章搜索和多轮RAG与集成工具。数据集通过一个可扩展的语言模型(LLM)驱动管道生成,确保数据集的真实性和高质量。CXMArena旨在解决现有基准数据集缺乏现实性、深度知识库集成、真实世界噪声和关键操作任务的问题。
CXMArena is a large-scale synthetic benchmark dataset developed to evaluate the performance of artificial intelligence in real-world customer experience management (CXM) scenarios. Created by Sprinklr, the dataset simulates brand-side customer experience management entities, including knowledge articles such as product specifications, question taxonomies, and call center dialogues. It includes five critical operational tasks: knowledge base refinement, intent prediction, agent quality compliance, article search, and multi-turn retrieval-augmented generation (RAG) and integrated tools. The dataset is generated through a scalable large language model (LLM)-driven pipeline, which guarantees its authenticity and high quality. CXMArena is designed to resolve the shortcomings of existing benchmark datasets, which typically lack realism, deep knowledge base integration, real-world noise elements, and sufficient coverage of key operational tasks.
提供机构:
Sprinklr
创建时间:
2025-05-14
原始信息汇总
CXM Arena Benchmark Suite 数据集概述
数据集描述
- 名称: CXM Arena Benchmark Suite
- 用途: 评估客户体验管理(CXM)领域的AI能力
- 任务类型:
- 文本排序(text-ranking)
- 文本分类(text-classification)
- 问答(question-answering)
- 文本生成(text-generation)
- 文本检索(text-retrieval)
- 语言: 英语(en)
- 许可证: CC BY-NC-4.0
- 数据规模: 1K<n<10K
核心任务
- Agent Quality Adherence: 监控联络中心代理表现
- KB Refinement: 知识库文章精炼
- Articles Search and Comprehension: 文章搜索与理解
- Intent Prediction: 意图预测
- Multi-Turn RAG with Tools: 多轮对话RAG与工具使用
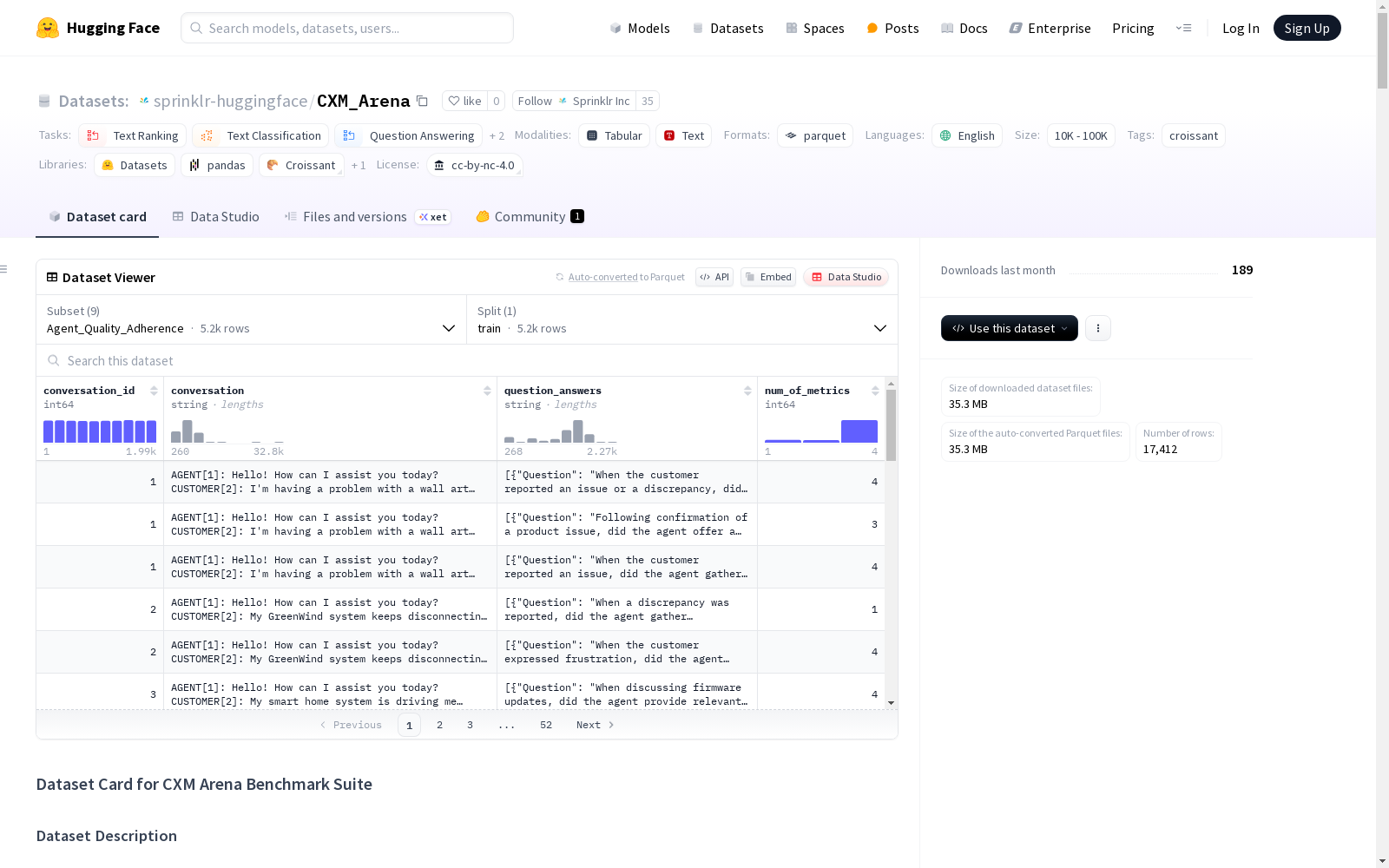
数据集组成与统计
Agent_Quality_Adherence
- 训练集: 5199个样本
- 文件大小: 7,977,029字节
KB_Refinement
- 矛盾对(contradictory_pairs): 293个样本
- 相似对(similarity_pairs): 518个样本
- 知识库文章: 1915篇
Articles
- 文章搜索文章: 2818篇
- 知识库精炼文章: 1915篇
- 多轮对话文章: 3381篇
Taxonomy
- Taxonomy 1: 95个样本
- Taxonomy 2: 208个样本
- Taxonomy 3: 37个样本
Intent_Prediction
- 训练集: 979个样本
Article_Search
- 训练集: 797个样本
Multi_Turn
- 训练集: 566个样本
Tool_Calling
- 训练集: 456个样本
Tools_Description
- 训练集: 150个样本
使用说明
-
直接用途:
- 评估联络中心代理监控系统
- 基准测试结合对话理解、段落理解和文本分类的流程
- 评估业务文章中相似和矛盾信息的识别能力
- 评估业务相关问答的检索系统
- 基准测试意图预测模型
- 评估多轮对话中的RAG系统性能
- 评估对话代理中的工具选择机制准确性
-
不适用场景:
- 高风险应用
- 非商业领域或多语言/多模态输入任务
- 不涉及多轮对话、知识检索或工具使用的任务
数据集创建
- 使用Gemini-2.0-flash和GPT-4o生成
- 包含"干净"和"噪声"版本内容以测试系统鲁棒性
- 工具调用子集基于456个生成对话的分析
引用格式
bibtex @misc{spinklr_cxm_arena_2025, title = {CXM Arena: A Unified Benchmark for Customer Experience Management Tasks}, author = {{Spinklr AI}}, year = {2025}, note = {A consolidated dataset synthetically generated using Gemini-2.0-flash and GPT-4o, encompassing tasks for agent quality adherence, KB refinement, article search and comprehension, intent prediction, and multi-turn RAG with tools. CC BY-NC-4.0.}, url = {https://huggingface.co/datasets/sprinklr-huggingface/CXM_Arena} }
搜集汇总
数据集介绍
构建方式
CXMArena数据集的构建采用了一种创新的、基于大型语言模型(LLM)的自动化流水线方法,旨在模拟真实的客户体验管理(CXM)场景。首先,通过定义虚构品牌的行业背景和关键特征,生成品牌概述叙事。随后,构建知识库(KB)的层次结构,包括信息知识库和问题知识库,并通过LLM生成详细内容。在知识库生成过程中,引入了结构化和语言噪声,以模拟真实世界知识库的不完美特性。对话生成阶段则利用生成的知识库,模拟客户与客服之间的多轮互动,同时注入控制噪声以增强真实性。最后,从生成的对话和知识库中提取特定任务的数据,如知识库优化、意图预测等。整个流程经过严格的自动化验证,确保数据的真实性和高质量。
特点
CXMArena数据集具有多个显著特点,使其在CXM领域的研究中具有重要价值。首先,数据集覆盖了五个关键的CXM操作任务,包括知识库优化、意图预测、客服质量 adherence、文章搜索和多轮RAG,这些任务在现有基准中常常被忽视。其次,数据集通过合成生成的方式,避免了隐私问题,同时通过控制噪声注入和严格的验证,确保了数据的真实性和多样性。此外,数据集中的对话和知识库紧密集成,对话内容基于相关知识库生成,提供了可验证的真实性链接。数据集还包含了丰富的元数据,如对话的意图标签、知识库引用和质量 adherence参数,为研究提供了全面的支持。最后,数据集的规模较大,包含近2000个模拟对话和超过1700篇知识库文章,能够满足大规模模型训练和评估的需求。
使用方法
CXMArena数据集的使用方法多样,适用于不同的研究任务。对于知识库优化任务,研究人员可以利用标注的相似和矛盾文章对,训练或评估模型在跨文档分析中的表现。意图预测任务则提供了带有意图标签的对话数据,可用于训练对话理解模型。客服质量 adherence任务通过对话和对应的质量评估查询,支持模型在客服表现评估中的应用。文章搜索任务提供了查询-知识库对的基准,可用于评估信息检索系统的性能。多轮RAG任务则通过对话历史和相关的知识库文章,支持模型在上下文感知辅助中的研究。数据集还提供了详细的评估协议和基准结果,帮助研究人员快速上手并进行对比实验。所有数据均以结构化格式提供,便于加载和处理,同时附有全面的文档和示例代码。
背景与挑战
背景概述
CXMArena数据集由Sprinklr公司的Raghav Garg、Kapil Sharma和Karan Gupta等研究人员于2025年提出,旨在解决客户体验管理(CXM)领域中大型语言模型(LLM)评估的空白。该数据集通过模拟真实的客户-代理交互和知识库(KB)集成,专注于五个核心操作任务:知识库精炼、意图预测、代理质量 adherence、文章搜索和集成工具的多轮RAG。CXMArena的创建填补了现有基准在真实性和任务覆盖范围上的不足,为CXM领域的研究和实践提供了重要的评估工具。
当前挑战
CXMArena数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,数据集需要解决复杂的CXM任务,如知识库精炼中的语义重叠和矛盾检测、意图预测中的大规模分类以及多轮RAG中的上下文感知检索。这些任务对现有模型提出了较高的要求,例如在文章搜索任务中,即使先进的嵌入模型也只能达到68%的准确率。在构建过程中,挑战包括合成数据的真实性保障、知识库一致性的维护以及噪声注入的控制。此外,数据隐私和多样性也是构建过程中需要克服的关键问题。
常用场景
经典使用场景
CXMArena数据集在客户体验管理(CXM)领域的研究中扮演了重要角色,特别是在评估大型语言模型(LLM)在复杂操作环境中的实际效用方面。该数据集通过模拟真实的客户-代理交互,结合深度知识库(KB)集成和现实世界噪声,为研究者提供了一个全面的基准测试平台。其经典使用场景包括知识库优化、意图预测、代理质量评估、文章搜索以及多轮检索增强生成(RAG)任务。
实际应用
在实际应用中,CXMArena数据集被广泛用于开发和优化客户服务中心的AI系统。例如,企业可以利用该数据集训练和评估其知识库维护系统,提升代理的意图识别准确率,以及优化多轮对话中的信息检索效率。这些应用显著提高了客户服务的自动化水平和响应质量,为企业提供了更高效的客户体验管理解决方案。
衍生相关工作
CXMArena的推出催生了一系列相关研究工作,特别是在基于LLM的客户服务自动化领域。许多研究团队利用该数据集开发了新型的知识库优化算法、意图分类模型和多轮对话管理系统。此外,该数据集还促进了工具集成和噪声处理技术的研究,为CXM领域的AI应用提供了更多创新思路和方法。
以上内容由遇见数据集搜集并总结生成


