InSpect
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/anonymous-dataset/InSpect
下载链接
链接失效反馈官方服务:
资源简介:
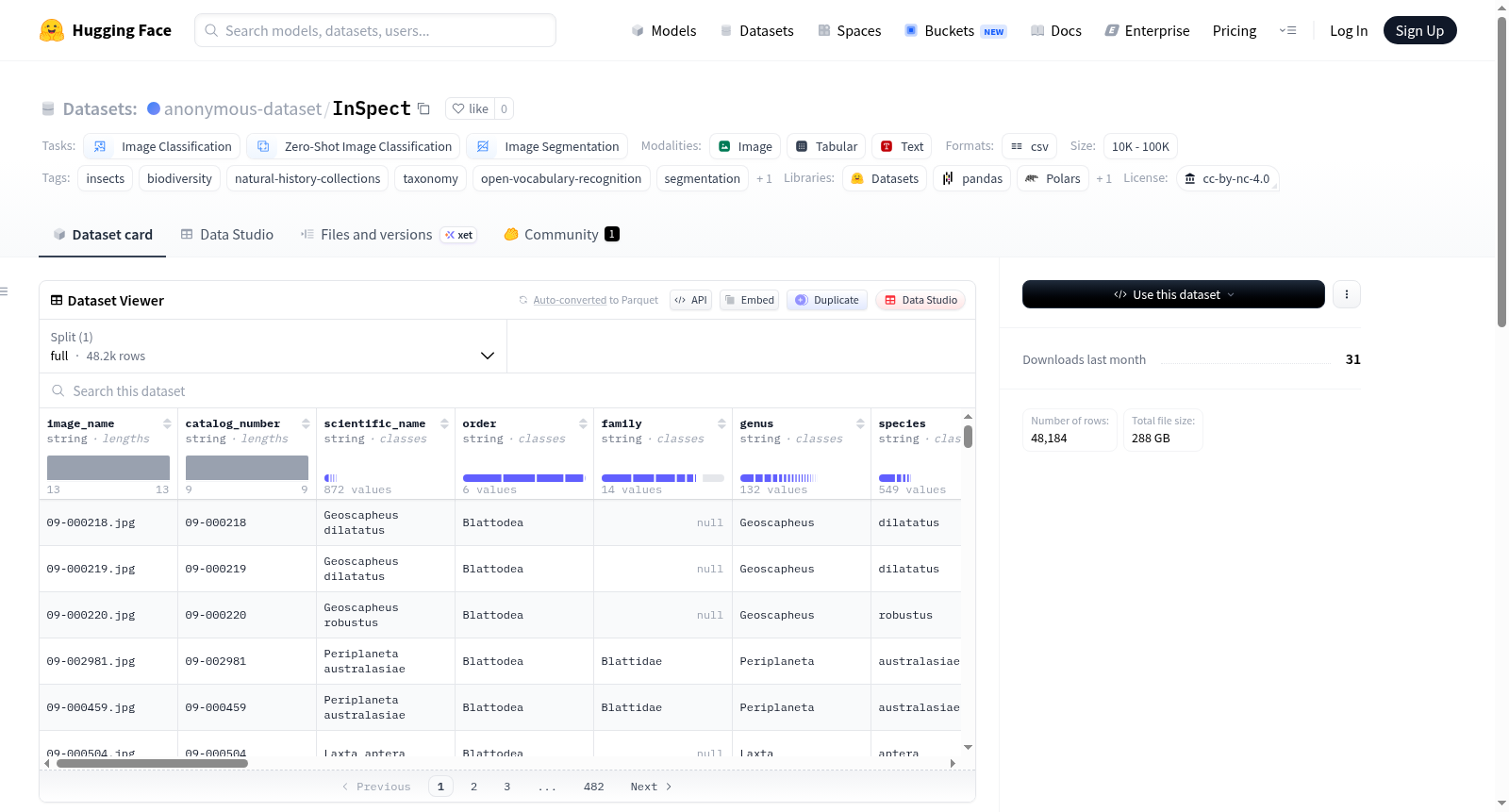
InSpect 是一个精心策划的自然历史收藏数据集,用于视觉昆虫标本理解。它包含数字化的昆虫标本图像,具有对齐的裁剪、层次分类学、标签衍生的结构化元数据和细粒度的解剖部位注释。数据集主要文件包括标本基准元数据表(CSV 和 JSONL 格式)、用于识别和分割的裁剪昆虫图像、解剖部位分割子集的图像和 COCO 风格的分割注释,以及裁剪前的原始图像。数据集支持开放分类识别和细粒度解剖部位分割等基准任务,适用于零样本、微调和未见分类单元评估,以及监督和文本引导的开放词汇分割设置。该数据集根据 CC BY-NC 4.0 许可证发布,仅限于非商业研究和教育用途。
InSpect is a curated natural history collection dataset for visual insect specimen understanding. It contains digitized insect specimen images with aligned cropping, hierarchical taxonomy, label-derived structured metadata, and fine-grained anatomical part annotations. The main dataset files include specimen benchmark metadata tables (in CSV and JSONL formats), cropped insect images for identification and segmentation, images of anatomical part segmentation subsets with COCO-style segmentation annotations, and original images before cropping. The dataset supports benchmark tasks such as open classification recognition and fine-grained anatomical part segmentation, suitable for zero-shot, fine-tuning, and unseen taxon evaluations, as well as supervised and text-guided open-vocabulary segmentation settings. It is released under the CC BY-NC 4.0 license, restricted to non-commercial research and educational use.
创建时间:
2026-05-04
原始信息汇总
InSpect 数据集概述
InSpect 是一个精选的自然历史馆藏昆虫标本视觉理解数据集,主要面向图像分类与分割任务。
数据集基本信息
- 许可证:CC BY-NC 4.0(仅限非商业研究与教育用途)
- 任务类型:图像分类、零样本图像分类、图像分割
- 标签/关键词:昆虫、生物多样性、自然历史馆藏、分类学、开放词汇识别、分割、解剖部位分割
数据集内容
数据集包含数字化昆虫标本图像及其相关标注,具体文件包括:
- 标本元数据表(
specimen_benchmark_metadata.csv):主元数据表,每条记录对应一张标本图像,包含划分信息、分类标签、图像/裁剪路径及标签派生的结构化元数据。 - JSONL 版本元数据(
specimen_benchmark_metadata.jsonl) - 裁剪昆虫图像(
final_benchmark_data_crops.zip):用于识别与分割任务。 - 分割图像(
segmentation_images.zip):解剖部位分割子集使用的图像。 - 分割标注(
segmentation_annotations.zip):COCO 格式的解剖部位分割标注。 - 原始图像(
original_images.zip):裁剪前的原始图像,多数图像包含一只昆虫及噪声元数据。
数据集结构
- 主要元数据文件包含基准测试使用的结构化记录。
- 图像文件和分割标注以压缩包形式提供下载。
- 识别实验使用裁剪后的昆虫图像,避免直接读取物理标本标签;评估基于元数据的识别时,会移除直接编码分类的元数据字段。
基准测试任务
1. 开放分类学识别
- 模型根据裁剪的昆虫图像预测分类学层级的标签。
- 评估设置包括:零样本评估、微调评估、未见分类单元评估。
- 额外包含基于元数据的设置,用于探查弱标本上下文。
2. 细粒度解剖部位分割
- 模型分割昆虫的解剖结构,如触角、腿、翅膀、头部、胸部、腹部。
- 评估设置包括:有监督分割、文本引导的开放词汇分割。
搜集汇总
数据集介绍
构建方式
InSpect数据集基于自然历史博物馆中数字化昆虫标本图像构建,通过系统化的数据采集与处理流程,生成了涵盖层级分类学、标签衍生结构化元数据及精细解剖部位标注的多元化数据资源。数据集包含原始图像、对齐裁剪后的昆虫区域图像、COCO格式的解剖部位分割标注以及结构化元数据表格。构建过程中,为避免物理标本标签信息干扰,识别实验专门采用裁剪后的昆虫图像,并在元数据评估时移除了直接编码分类学信息的字段。
使用方法
该数据集的使用主要围绕两大基准任务展开:开放分类学识别与细粒度解剖部位分割。对于识别任务,研究者可利用裁剪后的昆虫图像进行零样本、微调或未见分类类别的评估,并可选地结合元数据信息进行上下文感知预测。对于分割任务,数据集提供了COCO格式的标注文件,可直接用于训练和评估模型对昆虫解剖结构的像素级分割能力,支持传统监督学习及基于文本提示的开放词汇方案。
背景与挑战
背景概述
昆虫分类学与生物多样性研究长期依赖传统形态学鉴定,而数字化自然历史藏品为自动化物种识别与解剖结构分析提供了新的可能。InSpect数据集由相关研究机构于近年创建,专注于数字化昆虫标本图像的理解,涵盖层级化分类标签、标签派生结构化元数据及精细解剖部位标注。该数据集旨在推动开放词汇识别与解剖部位分割任务,为计算机视觉在生物多样性领域的应用奠定基础,其影响力体现在为跨物种识别与细粒度图像理解提供了标准化基准。
当前挑战
InSpect数据集应对的领域挑战包括昆虫分类的自动化与细粒度解剖结构识别,这对模型在零样本与未见类目场景下的泛化能力提出了高要求。构建过程中面临的挑战涵盖:原始标本图像存在噪声元数据且包含物理标签干扰,需设计裁剪策略以屏蔽直接标签读取;解剖部位标注的精细性与标准统一难度较大,需平衡多源标本的姿态与遮挡差异;同时,层级化分类体系需与开放词汇识别框架兼容,确保模型能在缺乏完整训练数据时有效推理。
常用场景
经典使用场景
在昆虫学与计算机视觉的交叉领域中,InSpect数据集为视觉昆虫标本理解提供了高度结构化的基准资源。其经典使用场景聚焦于开放分类学识别任务,研究者可基于裁剪后的昆虫标本图像,在零样本、微调及未见分类单元等评估协议下,预测物种级别的分类标签。此外,数据集还支持利用标签衍生的结构化元数据,探索标本弱上下文信息的识别能力。另一个核心场景是细粒度解剖部位分割,涵盖触角、足、翅、头、胸、腹等结构,既支持传统监督式分割,也兼容文本引导的开放词汇分割方法,从而推动从整体分类到部件解析的多层次视觉理解研究。
解决学术问题
InSpect数据集着力应对自然历史标本数字化过程中面临的若干关键学术难题。首先,它缓解了昆虫分类学中标记数据稀缺的困境,通过提供大规模、带层次化分类标签的标本图像,为训练和评估模型在细粒度物种识别上的表现奠定基础。其次,数据集引入了基于元数据的识别设置,有助于探究标本标签中隐含的上下文信息对分类性能的影响,从而揭示模型是否依赖“快捷线索”而非真正的生物学特征。此外,细粒度解剖部位分割的引入,挑战了模型对昆虫复杂形态结构的精确解析能力,推动了从粗粒度分类到精细结构感知的学术前沿。
实际应用
在实际应用层面,InSpect数据集的价值主要体现在生物多样性监测、害虫识别与农业保护等领域。通过训练鲁棒的昆虫识别模型,能够自动化处理大规模数字化标本图像,极大提升博物馆和自然历史收藏中物种标注的效率与准确性。与此同时,解剖部位分割能力可服务于昆虫形态学定量分析,例如评估翅脉损伤、触角形态变异等,为生态学研究提供量化工具。结合开放词汇分割的优势,模型还可灵活应用于现场拍摄的昆虫图像,支持非专业用户进行物种初步鉴定,进而助力公民科学项目和生物入侵早期预警系统的构建。
数据集最近研究
最新研究方向
InSpect数据集聚焦于昆虫标本图像的结构化理解,推动开放词汇识别与细粒度解剖分割的前沿探索。其基准涵盖零样本分类与基于元数据的弱标签学习,引导模型突破传统分类局限,应对未见类别的认知挑战。分割任务强调文本引导的开词汇范式,结合天线、翅、足等精细结构标注,助力生态监测与生物多样性自动化分析。该数据集通过严谨的元数据与图像裁剪设计,规避标本标签干扰,为自然历史藏品数字化提供可靠评估平台,其对开放环境下的物种自动鉴定与形态量化研究具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


