2505-deduplication-evals
收藏Hugging Face2025-11-24 更新2025-11-26 收录
下载链接:
https://huggingface.co/datasets/HPLT/2505-deduplication-evals
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了使用不同数据去重策略的HPLT 3.0预发布版本与HPLT 2.0版本比较的细粒度结果。数据集涵盖了西班牙语、法语、捷克语、乌克兰语、芬兰语、加泰罗尼亚语、加利西亚语、巴斯克语和挪威语等语言,并用于评估预训练模型在多种任务和提示下的性能。
提供机构:
HPLT创建时间:
2025-11-19
原始信息汇总
HPLT 3.0 去重策略比较评估数据集
数据集概述
该数据集包含 HPLT 3.0 预发布评估的细粒度结果,比较了不同数据去重策略在预 HPLT 3.0 语料库与先前 HPLT 2.0 版本之间的表现。
关键信息
评估目的
- 比较三种数据去重策略:预 HPLT 3.0 CD(按爬取去重)、预 HPLT 3.0 GD(全局去重)、预 HPLT 3.0 GDR(全局去重和再水合)
- 防止数据质量相对于 HPLT 2.0 出现回归
实验设置
- 在选定语言上预训练 22 亿参数的 Llama 风格解码器模型
- 使用 300 亿 tokens 进行训练
- 使用 HPLT-E 多语言评估框架进行评估
- 涵盖 124 个任务和 500+ 提示的全面多提示 k-shot 评估
语言覆盖
评估语言
- 西班牙语(spa_Latn)
- 法语(fra_Latn)
- 捷克语(ces_Latn)
- 乌克兰语(ukr_Cyrl)
- 芬兰语(fin_Latn)
- 加泰罗尼亚语(cat_Latn)
- 加利西亚语(glg_Latn)
- 巴斯克语(eus_Latn)
- 挪威语(博克马尔语和尼诺斯克语;nor_Latn)
数据集结构
配置信息
数据集包含 9 个配置,每个配置对应一个语言:
| 语言配置 | 样本数量 | 数据集大小 | 下载大小 |
|---|---|---|---|
| cat_Latn | 8,004 | 1,786,251 字节 | 99,314 字节 |
| ces_Latn | 8,816 | 2,030,164 字节 | 81,012 字节 |
| eus_Latn | 5,568 | 1,598,144 字节 | 58,635 字节 |
| fin_Latn | 11,600 | 2,861,252 字节 | 134,137 字节 |
| fra_Latn | 3,129 | 770,167 字节 | 30,495 字节 |
| glg_Latn | 3,480 | 784,095 字节 | 34,565 字节 |
| nor_Latn | 8,120 | 2,243,240 字节 | 99,819 字节 |
| spa_Latn | 5,568 | 1,263,252 字节 | 60,432 字节 |
| ukr_Cyrl | 1,972 | 575,270 字节 | 17,386 字节 |
数据特征
所有配置共享相同的特征结构:
- corpus(字符串):语料库名称
- category(字符串):任务类别
- dataset(字符串):评估数据集名称
- task(字符串):评估任务
- prompt(字符串):评估使用的提示
- model(字符串):预训练 tokens 数量
- ckpt_num(int64):模型检查点编号
- score(float64):标准指标性能得分
元数据
基本信息
- 策划者:High Performance Language Technologies (HPLT)
- 许可证:Apache 2.0
- 论文:https://arxiv.org/abs/2511.01066
- 代码库:https://github.com/hplt-project/hplt-e/tree/main
用途
该数据集旨在用于可重复性研究和研究目的。
引用信息
bibtex @article{oepen2025hplt, title={HPLT~{} 3.0: Very Large-Scale Multilingual Resources for LLM and MT. Mono-and Bi-lingual Data, Multilingual Evaluation, and Pre-Trained Models}, author={Oepen, Stephan and Arefev, Nikolay and Aulamo, Mikko and Ba{~n}{o}n, Marta and Buljan, Maja and Burchell, Laurie and Charpentier, Lucas and Chen, Pinzhen and Fedorova, Mariya and de Gibert, Ona and others}, journal={arXiv preprint arXiv:2511.01066}, year={2025} }
搜集汇总
数据集介绍
构建方式
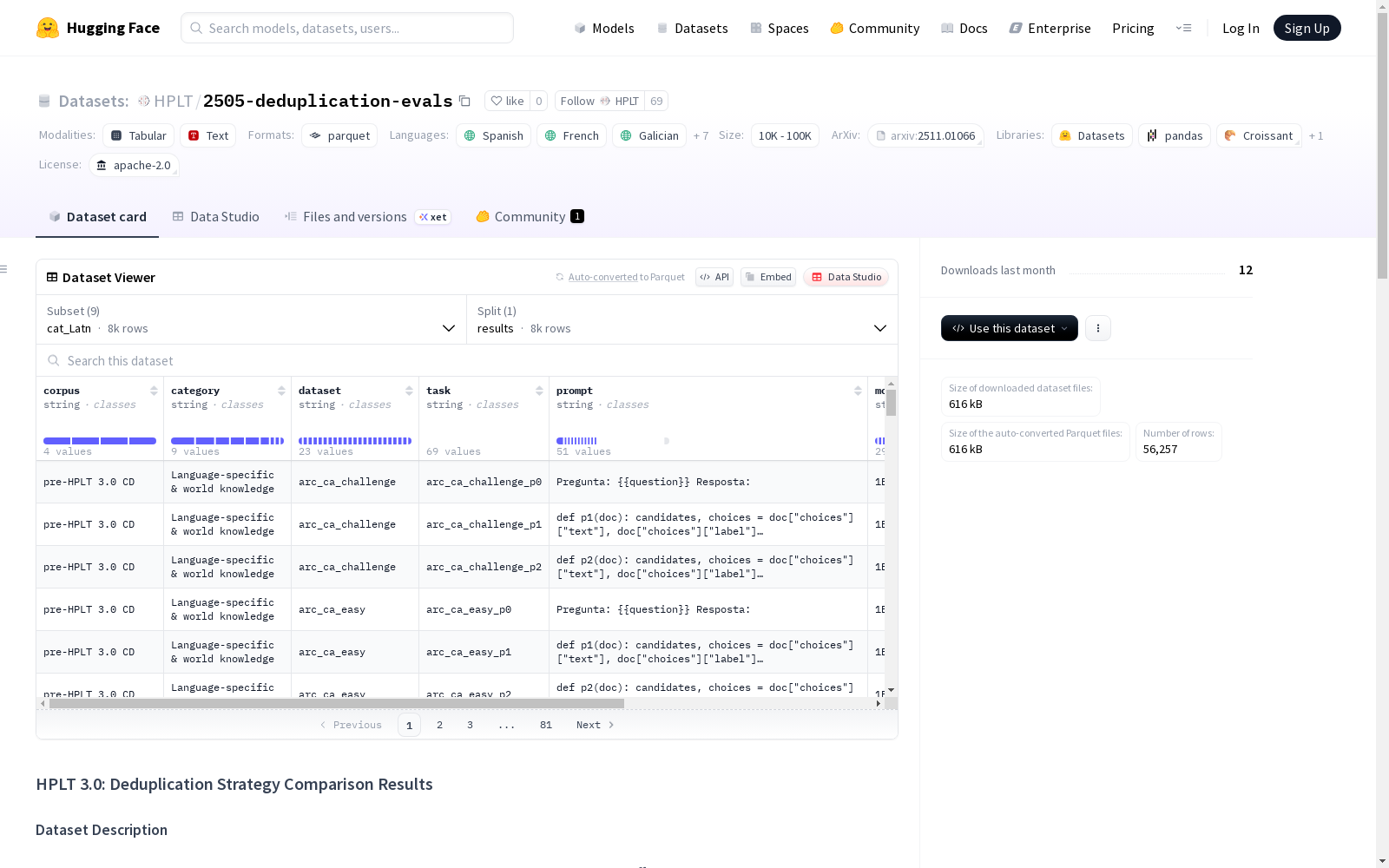
在自然语言处理领域,数据去重策略对模型性能具有深远影响。该数据集通过系统化实验设计构建,涵盖九种类型多样的语言,包括西班牙语、法语等。研究人员采用三种去重策略对比分析:基于单次爬取的局部去重、全局去重及结合数据重构的全局去重方法。通过训练22亿参数的Llama架构模型,并在300亿词汇量上对每种语言进行预训练,最终通过HPLT-E评估框架在124项任务中生成超过8000条评估记录。
特点
作为多语言模型评估的重要基准,该数据集展现出显著的跨语言特性。其核心价值在于包含124项任务的精细评估结果,覆盖常识推理等多元认知维度。数据维度设计科学严谨,每条记录包含语料来源、任务分类、提示模板等八个结构化字段,特别是通过标准化评分体系实现不同去重策略的量化对比。数据集涵盖从拉丁字母到西里尔字母的多种文字系统,为语言技术研究提供丰富样本。
使用方法
研究者可通过HuggingFace数据集库直接调用该资源,指定目标语言配置即可加载相应评估结果。以西班牙语为例,使用load_dataset函数并设置'spa_Latn'参数便能获取结构化数据。所得数据可转换为pandas DataFrame进行后续分析,便于比较不同去重策略在特定任务上的性能差异。该数据集支持多维度交叉分析,包括按语料版本、任务类别或模型检查点进行细粒度性能评估,为去重策略研究提供实证基础。
背景与挑战
背景概述
在自然语言处理领域,大规模多语言数据集的构建对提升模型泛化能力具有关键意义。HPLT项目组于2025年发布的2505-deduplication-evals数据集,聚焦于数据去重策略对预训练语料质量的系统性评估。该研究通过对比局部去重、全局去重及再水合三种策略在九种类型学多样语言上的表现,旨在优化多语言模型的架构设计。基于2.2B参数规模的Llama架构模型在300亿token上的实验证明,该数据集为跨语言模型的评估范式提供了重要基准。
当前挑战
多语言模型评估面临的核心挑战在于如何构建具有语言类型学代表性的测试集,同时确保评估指标能准确反映模型的实际能力。在数据集构建过程中,研究者需解决跨语言提示模板的等效性验证问题,并克服不同语种间数据稀疏性差异带来的偏差。此外,全局去重策略可能引发的语义信息损失与数据分布偏移,要求开发者在语料净化与信息完整性之间寻求精密平衡。
常用场景
经典使用场景
在自然语言处理领域,多语言模型评估数据集为研究数据去重策略对模型性能的影响提供了关键基准。该数据集通过对比不同去重方法在九种语言上的表现,系统评估了预训练语料质量对模型泛化能力的作用。其经典应用体现在对跨语言任务的统一评测框架中,为优化多语言数据清洗流程提供了实证依据。
实际应用
在实际应用层面,该数据集为构建高质量多语言模型提供了关键指导。企业机构可依据评测结果优化数据清洗流程,提升模型在西班牙语、乌克兰语等特定语言的性能表现。其评估框架已被应用于实际系统的数据质量控制,显著降低了多语言服务部署中的性能波动风险。
衍生相关工作
基于该数据集衍生的研究推动了多语言评估标准化进程。HPLT-E评估框架的持续完善受益于这些实证结果,后续工作进一步扩展了语言覆盖范围与任务类型。相关方法论为跨语言模型比较研究建立了新范式,促进了多语言学习领域的评估体系创新。
以上内容由遇见数据集搜集并总结生成


