SynthCheX-75K
收藏arXiv2025-05-16 更新2025-05-17 收录
下载链接:
https://raman1121.github.io/CheXGenBench/
下载链接
链接失效反馈官方服务:
资源简介:
SynthCheX-75K是一个包含75,000张高质量合成胸部X光片的数据集,由CheXGenBench基准测试中表现最优异的模型(Sana 0.6B)生成。该数据集旨在支持医疗图像分析研究,特别是文本到图像生成模型的评估。CheXGenBench是一个全面的基准测试框架,用于评估生成胸部X光片的文本到图像模型,同时考虑真实性、隐私风险和临床效用。该框架涵盖了20多个定量指标,系统地分析了生成质量、潜在的隐私漏洞以及11种领先的文本到图像架构的临床适用性。CheXGenBench的发布为医疗AI社区提供了一个标准化的基准,使得模型之间的比较更加客观和可重复,并促进了现有和未来生成模型的顺利集成。
SynthCheX-75K is a dataset consisting of 75,000 high-quality synthetic chest X-rays, generated by the top-performing model (Sana 0.6B) from the CheXGenBench benchmark. This dataset aims to support medical image analysis research, particularly the evaluation of text-to-image generation models. CheXGenBench is a comprehensive benchmark framework for evaluating text-to-image models that generate chest X-rays, taking into account authenticity, privacy risks, and clinical utility. The framework covers over 20 quantitative metrics, systematically analyzing the generation quality, potential privacy vulnerabilities, and clinical applicability of 11 leading text-to-image architectures. The release of CheXGenBench provides the medical AI community with a standardized benchmark, enabling more objective and reproducible cross-model comparisons, and facilitating the seamless integration of both existing and future generative models.
提供机构:
爱丁堡大学
创建时间:
2025-05-16
原始信息汇总
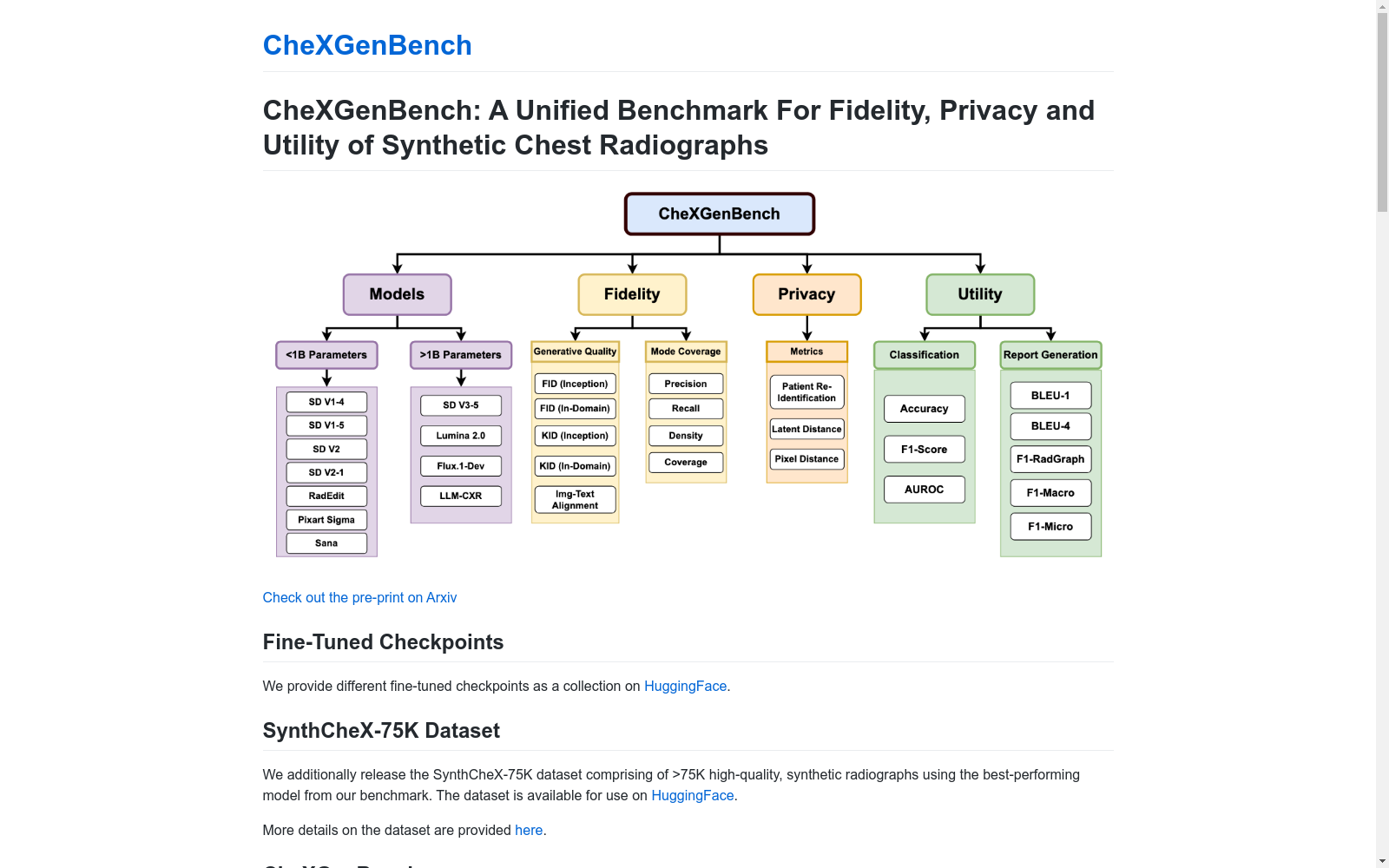
CheXGenBench 数据集概述
数据集基本信息
- 名称: CheXGenBench
- 全称: CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
- 预印本: 可在Arxiv查看
- GitHub地址: https://github.com/Raman1121/CheXGenBench
数据集内容
- SynthCheX-75K数据集:
- 包含超过75,000张高质量合成胸部X光片
- 使用基准测试中表现最佳的模型生成
- 可在HuggingFace获取
环境要求
- Python>=3.10.0
- Pytorch>=2.0.1+cu12.1
数据生成
- 训练图像下载: 需从指定链接下载MIMIC-CXR数据集并接受许可
- LLaVA-Rad注释:
- 位于
MIMIC_Splits/文件夹 - 包含训练CSV(
LLAVARAD_ANNOTATIONS_TRAIN.csv)和测试CSV(LLAVARAD_ANNOTATIONS_TEST.csv)
- 位于
- 数据组织要求:
- 生成图像时需保存原始提示和合成图像至CSV文件
- CSV文件需包含列:
prompt和img_savename
基准测试使用
生成保真度定量分析
- 整体分析:
- 计算整个测试数据集的指标
- 脚本路径:
./scripts/image_quality_metrics.sh - 内存节省版本:
./scripts/image_quality_metrics_memory_saving.sh - 结果存储位置:
Results/image_generation_metrics.csv
- 条件分析:
- 针对每种病理单独计算指标
- 脚本路径:
./scripts/image_quality_metrics_conditional.sh - 结果存储位置:
Results/conditional_image_generation_metrics.csv
隐私度量定量分析
- 需下载患者重新识别模型至
assets/checkpoints/文件夹 - 脚本路径:
./scripts/privacy_metrics.sh
下游效用定量分析
- 图像分类:
- 使用20,000个MIMIC数据集样本进行训练
- 提示文件路径:
MIMIC_Splits/Downstream_Classification_Files/training_data_20K.csv
- 放射学报告生成:
- 需按照LLaVA-Rad官方仓库步骤创建新环境
搜集汇总
数据集介绍
构建方式
SynthCheX-75K数据集的构建采用了前沿的文本到图像生成模型Sana(0.6B),该模型在CheXGenBench基准测试中表现卓越。构建过程包括对MIMIC-CXR数据集进行标准化训练分割,并采用增强的LLaVA-Rad注释以提升生成质量和隐私保护。通过50个周期的精细调优,生成75,000张高质量合成胸部X光片,随后利用HealthGPT医疗视觉语言模型进行严格的质量过滤,确保数据集的临床相关性和高保真度。
特点
SynthCheX-75K数据集以其规模化和病理多样性著称,涵盖14种胸部放射学病理类型,包括常见病征(如肺不张、心脏肥大)和罕见病例(如骨折、胸膜异常)。其独特之处在于采用RadDino域内编码器评估生成保真度,突破了传统DenseNet-121架构的局限性。数据集特别强化了对长尾分布病理的覆盖能力,通过精确的条件分析框架,可独立评估每种病理的生成质量,为医学影像分析提供了前所未有的细粒度研究资源。
使用方法
该数据集支持多模态医学AI研究的三大核心场景:首先,作为生成模型基准测试的黄金标准,可通过20余项量化指标系统评估保真度、隐私风险及临床效用;其次,支持数据增强应用,其高质量合成影像可单独用于训练放射学分类器(如ResNet-50),在10种病理分类任务中达到与真实数据相当的效能;最后,为跨模态研究提供接口,通过配套的LLaVA-Rad注释可实现图像-报告联合建模,推动放射学报告生成等复杂任务的发展。使用时需注意遵循分层采样策略以平衡病理分布,并配合发布的标准化评估协议确保结果可比性。
背景与挑战
背景概述
SynthCheX-75K是由爱丁堡大学、Sinkove和三星剑桥人工智能中心的研究团队于2025年推出的合成胸部X光片数据集,作为CheXGenBench基准测试框架的重要组成部分。该数据集包含75,000张由Sana 0.6B模型生成的高质量合成放射影像,旨在解决医学影像分析领域面临的数据稀缺和隐私保护等核心问题。SynthCheX-75K的创建标志着医学影像生成领域的重要进展,为诊断训练、罕见病症模拟等临床应用提供了新的研究资源。该数据集基于MIMIC-CXR数据集,采用先进的LLaVA-Rad注释系统,显著提升了生成影像的质量和临床相关性。
当前挑战
SynthCheX-75K面临的挑战主要体现在三个方面:首先,在领域问题方面,医学影像生成需要同时满足高保真度、隐私保护和临床实用性三大要求,而现有模型在长尾病理分布处理上表现不佳,难以平衡常见病症与罕见病例的生成质量。其次,在构建过程中,研究团队面临评估指标不可靠的挑战,传统FID指标在医学领域的适用性有限,需要开发RadDino等专用评估工具。最后,隐私风险控制是重大挑战,即使低质量生成模型也可能导致患者重新识别风险,需要开发像素距离、潜在距离等多维度隐私评估体系。此外,数据效用评估显示合成影像在多模态任务(如放射报告生成)中的表现仍有提升空间。
常用场景
经典使用场景
在医学影像分析领域,SynthCheX-75K数据集作为高质量合成胸部X光片的集合,为研究人员提供了一个标准化的基准测试平台。该数据集广泛应用于评估文本到图像生成模型在医学影像合成中的性能,特别是在生成质量、隐私保护和临床实用性方面的综合评估。通过这一数据集,研究者能够系统地比较不同生成模型在模拟真实胸部X光片方面的表现,从而推动医学影像生成技术的进步。
解决学术问题
SynthCheX-75K数据集解决了医学影像生成研究中的多个关键问题。首先,它填补了医学领域缺乏标准化评估框架的空白,通过统一的评估协议和多样化的量化指标,使得不同生成模型的性能比较更加客观和可重复。其次,数据集特别关注了长尾分布问题,通过病理特异性评估,揭示了生成模型在罕见病理条件下的性能瓶颈。此外,该数据集还首次系统评估了合成影像的隐私风险,为医学数据生成中的隐私保护研究提供了重要参考。
衍生相关工作
SynthCheX-75K数据集已经衍生出多个重要的研究方向和相关工作。基于该数据集,研究者开发了更先进的医学影像生成架构,如Sana模型在胸部X光合成中的创新应用。在评估方法方面,该数据集促进了新型医学影像质量评估指标的发展,如基于RadDino的特征提取方法。此外,围绕该数据集还开展了关于医学数据隐私保护的深入研究,包括患者重新识别风险的量化分析和隐私保护生成技术的开发。这些工作共同推动了医学AI领域在数据生成和评估方面的进步。
以上内容由遇见数据集搜集并总结生成


