anab/copa-sse
收藏Hugging Face2024-07-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/anab/copa-sse
下载链接
链接失效反馈官方服务:
资源简介:
COPA-SSE数据集包含了针对Balanced COPA数据集的众包解释,这些解释以类似三元组的常识陈述形式呈现,使用ConceptNet关系但自由编写的概念。数据集支持解释+预测或预测+解释的设置,适用于基于文本和基于图的架构。基础任务是COPA(因果问答)。数据集的语言为英语,遵循MIT许可证。
COPA-SSE数据集包含了针对Balanced COPA数据集的众包解释,这些解释以类似三元组的常识陈述形式呈现,使用ConceptNet关系但自由编写的概念。数据集支持解释+预测或预测+解释的设置,适用于基于文本和基于图的架构。基础任务是COPA(因果问答)。数据集的语言为英语,遵循MIT许可证。
提供机构:
anab
原始信息汇总
数据集概述
数据集名称
- 名称: COPA-SSE
- 全称: Semi-structured Explanations for Commonsense Reasoning
数据集属性
- 语言: 英语
- 许可证: MIT
- 多语言性: 单语种
- 规模: 1K<n<10K
- 标签:
- 常识推理
- 解释
- 基于图的推理
- 任务类别:
- 文本生成
- 多选题
- 任务ID: 解释生成
数据集内容
- 描述: COPA-SSE包含针对Balanced COPA数据集的众包解释,这些解释以ConceptNet关系的三元组形式呈现,但概念是自由书写的。
- 用途: 可用于训练模型进行解释+预测或预测+解释设置,适用于基于文本和基于图的架构。基础任务是COPA(因果问答)。
数据集结构
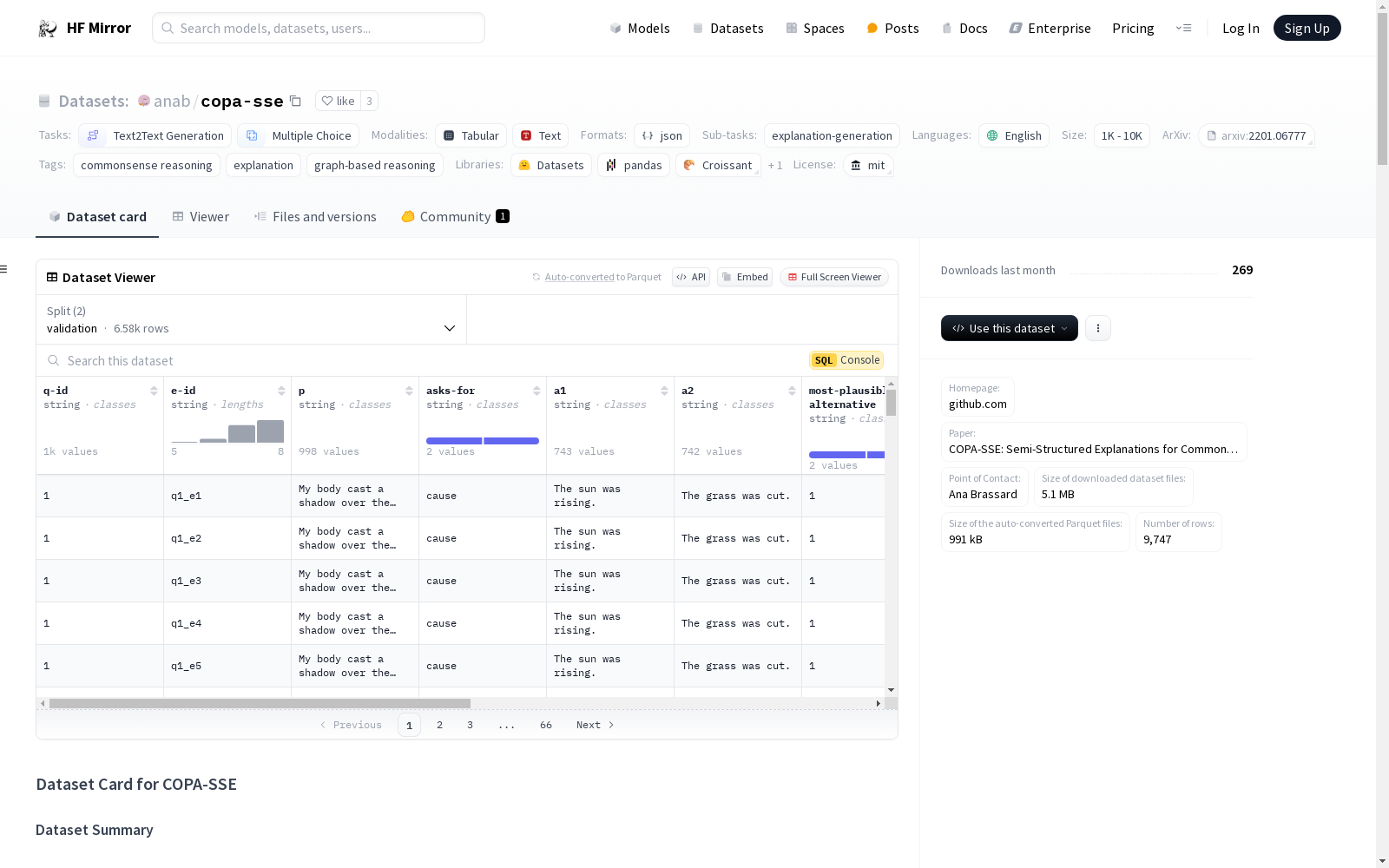
- 数据实例: 验证集和测试集分别包含带有附加解释的Balanced COPA样本,格式为
.jsonl。问题ID与Balanced COPA验证集和测试集的原始问题匹配。 - 数据字段:
- 原始问题
human-explanations: 包含解释ID、文本、作者ID、作者平均评分、所有评分、过滤后的评分和三元组形式解释的列表。
数据集创建
- 来源数据: 解释完全通过Amazon Mechanical Turk平台众包收集,每个解释由不同的注释者进行一到五星的评分。
- 注释者: 注释者为通过初步资格审核的Amazon Mechanical Turk工人,位于美国或英国,具有98%以上的HIT批准率和500个以上的批准HIT。
使用考虑
- 社会影响: 模型输出的解释可能不总是具有说服力或忠实性,研究人员应在考虑实际应用前仔细评估解释的质量。
- 偏见讨论: 一些解释可能基于有偏见的假设,这些偏见在收集过程中未被验证。
附加信息
- 数据集创建者: Ana Brassard, Benjamin Heinzerling, Pride Kavumba, Kentaro Inui
- 许可证信息: MIT License
- 引用信息: 见README文件中的引用格式。
搜集汇总
数据集介绍
构建方式
COPA-SSE数据集的构建基于Balanced COPA数据集,通过众包方式收集解释性文本。具体而言,利用Amazon Mechanical Turk平台,工作者被要求为每个COPA问题提供一个或多个概念-关系-概念三元组的解释。这些解释随后由不同的标注者进行1至5星的评级。最终数据集包含多种质量评级的解释,确保每个样本至少有一个评级为3.5星或更高的解释。
特点
COPA-SSE数据集的主要特点在于其半结构化的解释形式,这种形式既支持基于文本的模型,也适用于基于图的模型。此外,数据集中的解释以自由书写的概念和ConceptNet关系为基础,增强了数据的整体质量。数据集还包含了匿名的工作者ID和过滤后的评级,确保了数据的透明性和可靠性。
使用方法
COPA-SSE数据集适用于训练模型进行解释生成和预测任务,特别适合于文本生成和多选题任务。用户可以通过加载`.jsonl`格式的数据实例,利用其中的解释文本和三元组信息进行模型训练。数据集的结构清晰,包含原始COPA问题字段、解释ID、解释文本、三元组形式解释、工作者ID和评级信息,便于用户进行多方面的分析和应用。
背景与挑战
背景概述
COPA-SSE数据集由Ana Brassard、Benjamin Heinzerling、Pride Kavumba和Kentaro Inui等研究人员于2022年创建,隶属于Riken AIP自然语言理解团队和Tohoku大学NLP实验室。该数据集旨在为常识推理提供半结构化的解释,通过众包方式收集了Balanced COPA数据集的解释,这些解释以ConceptNet关系的三元组形式呈现。COPA-SSE的核心研究问题是如何在保持数据质量的同时,为现有的常识推理基准提供丰富的解释,从而推动文本和图结构模型的训练与评估。
当前挑战
COPA-SSE数据集在构建过程中面临多项挑战。首先,如何确保众包解释的质量,避免自由文本中常见的噪声和偏差,是一个主要问题。其次,解释的半结构化形式虽然有利于图模型,但其自然语言表达可能不够流畅,影响解释的可读性和实用性。此外,数据集中可能存在的社会偏见,如性别语言的使用,需要在使用时加以注意和纠正。最后,尽管数据集旨在生成解释图,但其自然语言解释的适用性仍需进一步验证,以确保其在实际应用中的有效性。
常用场景
经典使用场景
在常识推理领域,COPA-SSE数据集的经典使用场景主要集中在解释生成和因果问答任务上。该数据集通过提供半结构化的解释,帮助模型理解并生成关于日常事件因果关系的自然语言描述。这些解释以ConceptNet关系为基础,支持图模型和文本模型的训练,从而提升模型在复杂推理任务中的表现。
实际应用
在实际应用中,COPA-SSE数据集可用于开发智能助手和教育工具,帮助用户理解复杂决策背后的逻辑。例如,在智能客服系统中,该数据集可以用于生成用户查询的详细解释,提高用户满意度。此外,它还可应用于教育领域,为学生提供更直观的因果关系解释,增强学习效果。
衍生相关工作
基于COPA-SSE数据集,研究者们开发了多种图模型和文本生成模型,用于处理复杂的常识推理任务。例如,一些工作利用该数据集训练的模型在解释生成任务中取得了显著进展,推动了可解释人工智能的发展。此外,该数据集还激发了关于如何有效利用半结构化数据进行模型训练和评估的新研究方向。
以上内容由遇见数据集搜集并总结生成


