traintogpb/aihub-kozh-translation-integrated-small-100k
收藏Hugging Face2024-05-30 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/traintogpb/aihub-kozh-translation-integrated-small-100k
下载链接
链接失效反馈官方服务:
资源简介:
AI Hub Ko-Zh翻译数据集(整合版)整合了10个与韩中翻译相关的数据集,总数据量为5,934,596条。数据集分为large-5.9m、base-1m和small-100k三个规模,分别使用全部数据、1百万条数据和10万条数据。此外,数据集还包含了10,000条验证集和2,000条测试集,这些验证集和测试集在所有规模的数据集中都相同使用。
AI Hub Ko-Zh翻译数据集(整合版)整合了10个与韩中翻译相关的数据集,总数据量为5,934,596条。数据集分为large-5.9m、base-1m和small-100k三个规模,分别使用全部数据、1百万条数据和10万条数据。此外,数据集还包含了10,000条验证集和2,000条测试集,这些验证集和测试集在所有规模的数据集中都相同使用。
提供机构:
traintogpb
原始信息汇总
AI Hub Ko-Zh Translation Dataset (Integrated)
概述
- 数据集来源:AI Hub
- 数据集类型:翻译数据集
- 语言:韩语(ko)、中文(zh)
- 许可证:MIT
数据集组成
- 总数据量:5,934,596条
- 训练集划分:
- large-5.9m (train): 5,922,596条
- base-1m (train): 1,000,000条
- small-100k (train): 100,000条
- 验证集与测试集:
- 验证集(validation set):10,000条
- 测试集(test set):2,000条
子集详情
| 名称 | 总大小 | 中文大小 | 数据集键(AIHub) |
|---|---|---|---|
| 한국어-중국어 번역 말뭉치(기술과학) | 1,170,000 | 1,170,000 | 128 |
| 한국어-중국어 번역 말뭉치(사회과학) | 1,170,000 | 1,170,000 | 129 |
| 일상생활 및 구어체 한-중, 한-일 번역 병렬 말뭉치 데이터 | 2,700,000 | 1,349,470 | 546 |
| 전문분야 영-한, 중-한 번역 말뭉치(식품) | 1,350,000 | 1,326,837 | 71262 |
| 방송 콘텐츠 한-중, 한-일 번역 병렬 말뭉치 데이터 | 1,487,088 | 367,921 | 71263 |
| 발화유형(문어, 구어, 채팅) 별 기계번역 병렬 말뭉치 | 82,002 | 26,989 | 71411 |
| 한국어-다국어 번역 말뭉치(기술과학) | 270,459 | 146,317 | 71493 |
| 한국어-다국어 번역 말뭉치(기초과학) | 270,317 | 84,419 | 71496 |
| 한국어-다국어 번역 말뭉치(인문학) | 271,721 | 80,375 | 71498 |
| 방송콘텐츠 한국어-아시아어 번역 말뭉치 | 820,387 | 112,978 | 71591 |
| AI 허브 데이터 활용을 위한 기계 번역말뭉치 | 2,653,948 | 212,268 | 71593 |
搜集汇总
数据集介绍
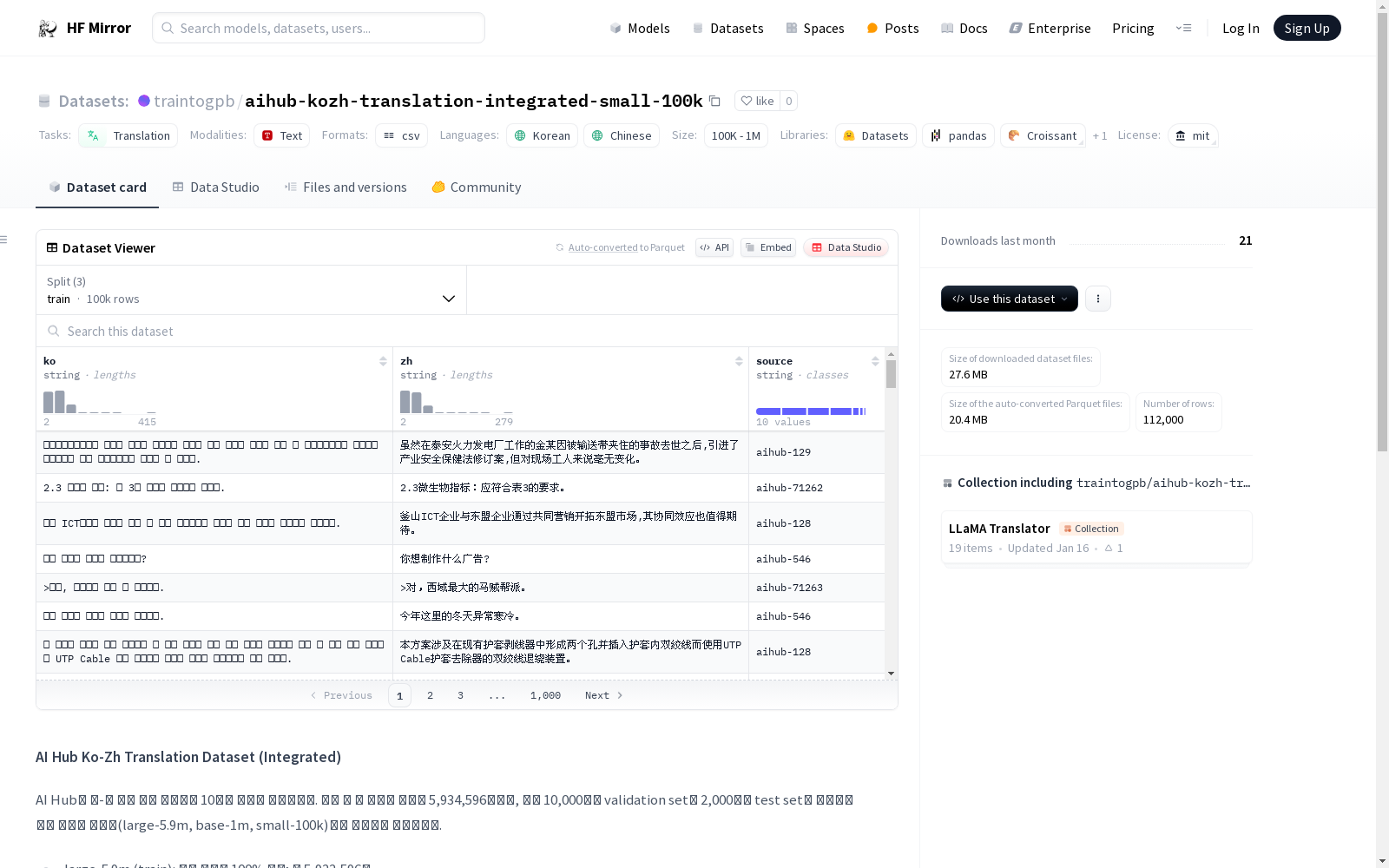
构建方式
该数据集是对AI Hub的韩中翻译相关数据集10个进行整合的结果。整合后的数据集包含5,934,596条数据,其中经过筛选,分别划分出10,000条作为验证集,2,000条作为测试集。数据集分为large-5.9m、base-1m、small-100k三种规模,分别对应使用整合数据的100%、1M条、100K条,以适应不同规模的需求。
特点
本数据集的特点在于其多元化和综合性。它不仅包含了技术科学、社会科学等多个领域的翻译数据,还涵盖了日常生活中的口语和书面语等多种语言表达形式。此外,数据集的规模灵活,能够满足不同研究需求的场景。
使用方法
使用该数据集时,用户可以根据需要选择不同规模的数据集进行训练、验证和测试。数据集以MIT许可证发布,用户可以在遵守许可协议的前提下,自由地使用和修改数据集。具体使用时,可通过AI Hub提供的URL链接访问各个子集的数据。
背景与挑战
背景概述
AI Hub Ko-Zh Translation Dataset (Integrated)은 인공지능 번역 연구의 중요한 자원으로서,2010년대 중반에 AI Hub에 의해 개발되었다. 이 데이터셋은 한-중 번역 관련 데이터셋 10개를 통합하여 구성되었으며,총 5,934,596개의 데이터를 포함하고 있다. 그 중 10,000개의 검증 세트와 2,000개의 테스트 세트가 분리되어 사용되며,대규모(large-5.9m),기본(base-1m),소규모(small-100k) 세 가지 데이터 사이즈로 제공된다. 이 데이터셋은 자연어 처리 분야에서 널리 사용되며,한-중 번역 모델의 효과적인 학습과 평가에 중요한 역할을 한다.
当前挑战
이 데이터셋이 직면한 주요 도전은 다음과 같다. 첫째,데이터의 품질과 일관성을 보장하기 위해 데이터 전처리와 정리 작업이 필요하다. 둘째,다양한 분야와 언어 스타일을 포함한 데이터셋을 통합하는 과정에서 데이터의 균형을 유지하는 것이 어렵다. 셋째,데이터셋의 규모가 커서,효율적인 데이터 관리와 처리 방법이 필요하다. 마지막으로,이 데이터셋을 사용한 번역 모델의 성능을 공정하게 평가하기 위해서는 표준화된 평가 방법이 필요하다.
常用场景
经典使用场景
在自然语言处理领域,traintogpb/aihub-kozh-translation-integrated-small-100k数据集的典型应用场景是作为机器翻译模型的训练集。该数据集集合了多种领域的韩语-中文翻译数据,使得模型能在不同语境下准确地进行语言转换,从而提高翻译质量和效率。
衍生相关工作
基于该数据集,研究者们衍生出了一系列相关工作,如翻译质量评估、跨语言信息检索、语言模型改进等。这些工作进一步拓宽了机器翻译技术的应用范围,为多语言信息处理提供了新的视角和方法。
数据集最近研究
最新研究方向
在自然语言处理领域,尤其是机器翻译方向,近期研究聚焦于提升小规模数据集的翻译质量和效率。traintogpb/aihub-kozh-translation-integrated-small-100k数据集,作为AI Hub韩中翻译数据集的子集,包含10万个训练样本,为研究者提供了在有限数据资源下优化翻译模型的宝贵资源。当前,该数据集正被广泛应用于开发能够适应不同语言环境和专业领域的翻译模型,特别是在技术科学、社会科学以及日常对话等领域的应用研究,对提升机器翻译的准确性和实用性具有重要意义。
以上内容由遇见数据集搜集并总结生成


