stocks
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/matthewyn/stocks
下载链接
链接失效反馈官方服务:
资源简介:
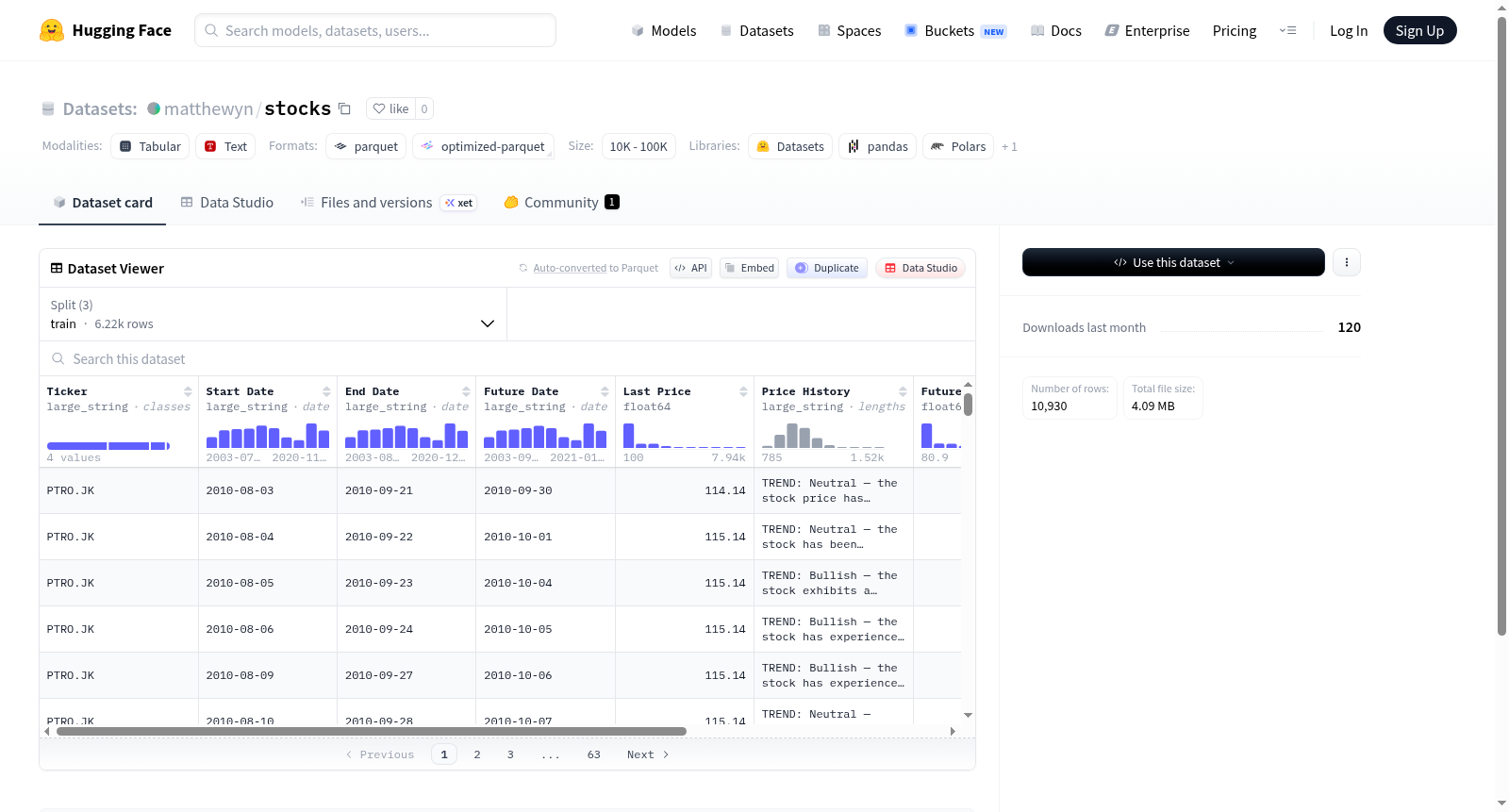
该数据集包含金融领域的股票价格历史及未来价格信息,主要特征包括股票代码(Ticker)、起始日期(Start Date)、结束日期(End Date)、未来日期(Future Date)、最后价格(Last Price)、价格历史(Price History)、未来价格(Future Price)和回报率(Return %)。数据集分为训练集(6,215个样本)、验证集(1,124个样本)和测试集(3,591个样本)三个部分,总大小约12.26MB。数据以结构化格式存储,适用于股票价格预测、时间序列分析等金融分析任务。
创建时间:
2026-04-25
原始信息汇总
数据集概述:matthewyn/stocks
该数据集是一个面向股票市场分析的数据集,旨在提供股票历史价格及相关信息,用于训练和评估预测模型。
核心特征
- 股票代码 (Ticker):字符串类型,标识具体的股票。
- 时间范围:
- Start Date:字符串类型,记录价格历史的开始日期。
- End Date:字符串类型,记录价格历史的结束日期。
- Future Date:字符串类型,用于预测的未来日期。
- 价格数据:
- Last Price:浮点数类型,当前或最近的价格。
- Price History:字符串类型,历史价格序列(可能是文本形式)。
- Future Price:浮点数类型,未来某时间点的价格,用于训练预测目标。
- 收益率 (Return %):浮点数类型,基于历史与未来价格计算的收益率。
此外,数据集还包含一个索引字段 index_level_0(整数类型),用于数据管理。
数据规模与分割
- 总大小:12,262,634 字节(约 12.3 MB),下载大小约 4.1 MB。
- 数据分割:
- 训练集 (train):6,215 个样本,占主要部分。
- 验证集 (validation):1,124 个样本,用于模型调优。
- 测试集 (test):3,591 个样本,用于最终评估。
配置文件与文件结构
数据集提供默认配置 default,数据文件按分割存储在 data/ 目录下,命名模式如下:
- 训练数据:
data/train-* - 验证数据:
data/validation-* - 测试数据:
data/test-*
用途建议
该数据集适用于构建股票价格预测或收益率预测模型,利用历史价格特征(如 Price History)和当前价格(Last Price)来预测未来价格(Future Price)或收益率(Return %)。
搜集汇总
数据集介绍
构建方式
该数据集以股票市场为核心,聚焦于个股历史价格数据的结构化整理。其构建过程首先从公开金融数据源中提取特定股票代码(Ticker)的时间序列信息,涵盖起止日期与每日收盘价,形成完整的价格历史记录。随后,基于历史序列计算未来某一时点的价格及其相对于当前收盘价的回报率(Return%),从而为预测任务提供标注。数据最终被划分为训练集(6215例)、验证集(1124例)与测试集(3591例),以支持模型开发与评估。
特点
数据集在特征设计上兼具时间序列分析与回归预测的双重属性。核心字段包括‘Price History’(历史价格文本序列)与‘Last Price’(最新收盘价),而‘Future Price’与‘Return%’则构成目标变量,可直接用于监督学习。此外,‘Future Date’字段明确了预测时间窗口,增强了时间对齐的严谨性。整体结构简洁,适合作为金融时间序列预测的基准测试资源。
使用方法
该数据集适用于基于历史价格预测未来收益率的回归任务,或用于训练证券组合回报率的金融模型。用户可通过HuggingFace Datasets库加载数据,默认配置下三份分割(train/validation/test)可直接用于模型迭代。实践中,建议对‘Price History’字段进行序列化编码(如LSTM输入格式),并结合‘Ticker’进行截面分析,以捕捉不同股票的异质性动态模式。
背景与挑战
背景概述
该数据集名为stocks,专注于金融时间序列分析,旨在为股票价格预测提供标准化的基准数据。创建于近年,由数据科学和量化金融领域的研究人员构建,核心研究问题在于利用历史价格数据预测未来走势,评估不同模型的预测能力。其影响力体现在为股票收益率预测、金融机器学习等领域提供了公开可复现的数据资源,促进了序列建模方法的比较与验证,推动了量化投资研究的严谨性。
当前挑战
该数据集面临的挑战包括领域问题层面和构建层面。领域问题方面,股票价格预测本身具有高度非平稳性和噪声干扰,历史价格数据难以完全捕捉市场情绪、宏观经济事件等复杂因素,导致模型泛化困难。构建过程中,数据清洗需处理不同时间跨度下的缺失值、股票分拆等事件,且特征工程中仅依赖价格历史难以刻画完整市场动态,未来价格标签的时效性要求数据更新频繁以维持实用性。
常用场景
经典使用场景
在金融时序分析领域,stocks数据集以其精细的结构化特征,成为研究股票价格预测与趋势建模的核心资源。该数据集涵盖了股票代码、历史价格序列、未来价格及收益率等关键变量,为探索资产价格动态演化规律提供了标准化训练样本。研究者常利用其历史价格时间序列,结合技术指标或深度学习模型,挖掘价格波动中的隐含模式,进而构建回归或分类框架以预测短期未来价格变动方向。该数据集在量化策略回测、风险管理模型验证以及市场微观结构分析中扮演重要角色,尤其适合于长短期记忆网络、时序Transformer等前沿神经网络架构的性能评估与对比研究。
解决学术问题
stocks数据集有效解决了金融预测研究中常见的小样本过拟合与市场噪声干扰问题。通过提供跨股票的多期价格记录及明确的训练、验证、测试划分,它使得研究者能够系统性地评估不同模型在收益率预测任务上的泛化能力。该数据集推动了传统统计模型(如ARIMA、GARCH)与机器学习方法(如XGBoost、随机森林)在非平稳金融时间序列建模中的比较研究,为探索价格序列的统计特征、收益率分布偏态以及波动率聚类现象提供了可复现的实验基准。其贡献在于促进了金融时间序列建模从经验分析向数据驱动型的范式转变,强化了学术领域对市场有效性假说检验的量化工具。
衍生相关工作
该数据集衍生出的经典工作包括基于Transformer架构的股票价格预测模型,这类模型利用自注意力机制捕捉长期价格依赖关系,显著提升了预测准确率。另一类代表性工作是融合情感分析的混合预测框架,即联合使用该数据集的数字特征与社交媒体文本数据,通过多模态学习增强对市场突发事件的响应能力。此外,部分研究将其用于强化学习中的交易环境模拟,将历史价格序列转换为状态空间,训练智能体学习最优仓位管理策略。这些衍生工作进一步拓展了时序预测、自然语言处理与决策优化等领域的交叉学科边界,为金融科技的发展提供了坚实的实验基础。
以上内容由遇见数据集搜集并总结生成


