decorrelated-chess-3.8m
收藏Hugging Face2026-05-15 更新2026-05-16 收录
下载链接:
https://huggingface.co/datasets/gRa1ne/decorrelated-chess-3.8m
下载链接
链接失效反馈官方服务:
资源简介:
Minimal Policy + Value Net Chess Dataset 是一个专为国际象棋人工智能模型训练设计的紧凑型数据集。该数据集源自lichess精英数据库,包含380万条非相关的国际象棋局面,每条数据均来自独立的游戏对局,确保了样本的多样性。每条数据记录包含三个核心部分:8步历史局面的FEN编码序列(最后一步表示当前最新局面)、与历史局面对应的8步UCI格式下一步走法、以及游戏结果分类标签(0代表黑方获胜,1代表白方获胜,2代表平局)。该数据集旨在以高效的空间占用,为中小型国际象棋深度学习模型(如策略网络和价值网络)提供训练数据,适用于国际象棋局面评估、走法预测等任务。
The Minimal Policy + Value Net Chess Dataset is a compact dataset designed for training artificial intelligence models in chess. It is derived from the lichess elite database and contains 3.8 million non-redundant chess positions, each from an independent game, ensuring sample diversity. Each data record consists of three core components: an FEN encoding sequence of 8 historical positions (with the last step representing the current latest position), 8 corresponding UCI-format next moves for the historical positions, and a game outcome classification label (0 for black win, 1 for white win, 2 for draw). The dataset aims to provide training data for small to medium-sized chess deep learning models (such as policy and value networks) with efficient space usage, suitable for tasks like chess position evaluation and move prediction.
创建时间:
2026-05-15
原始信息汇总
数据集概述:Minimal Policy + Value Net Chess Dataset
基本信息
- 数据集名称:Minimal Policy + Value Net Chess Dataset
- 许可证:MIT
- 标签:国际象棋
- 数据集大小:380万条记录
数据来源
- 源自 lichess 精英数据库(lichess elite database)
数据特点
- 包含 380万个不相关的国际象棋局面(每个局面来自不同的对局,确保无相关性)
数据字段
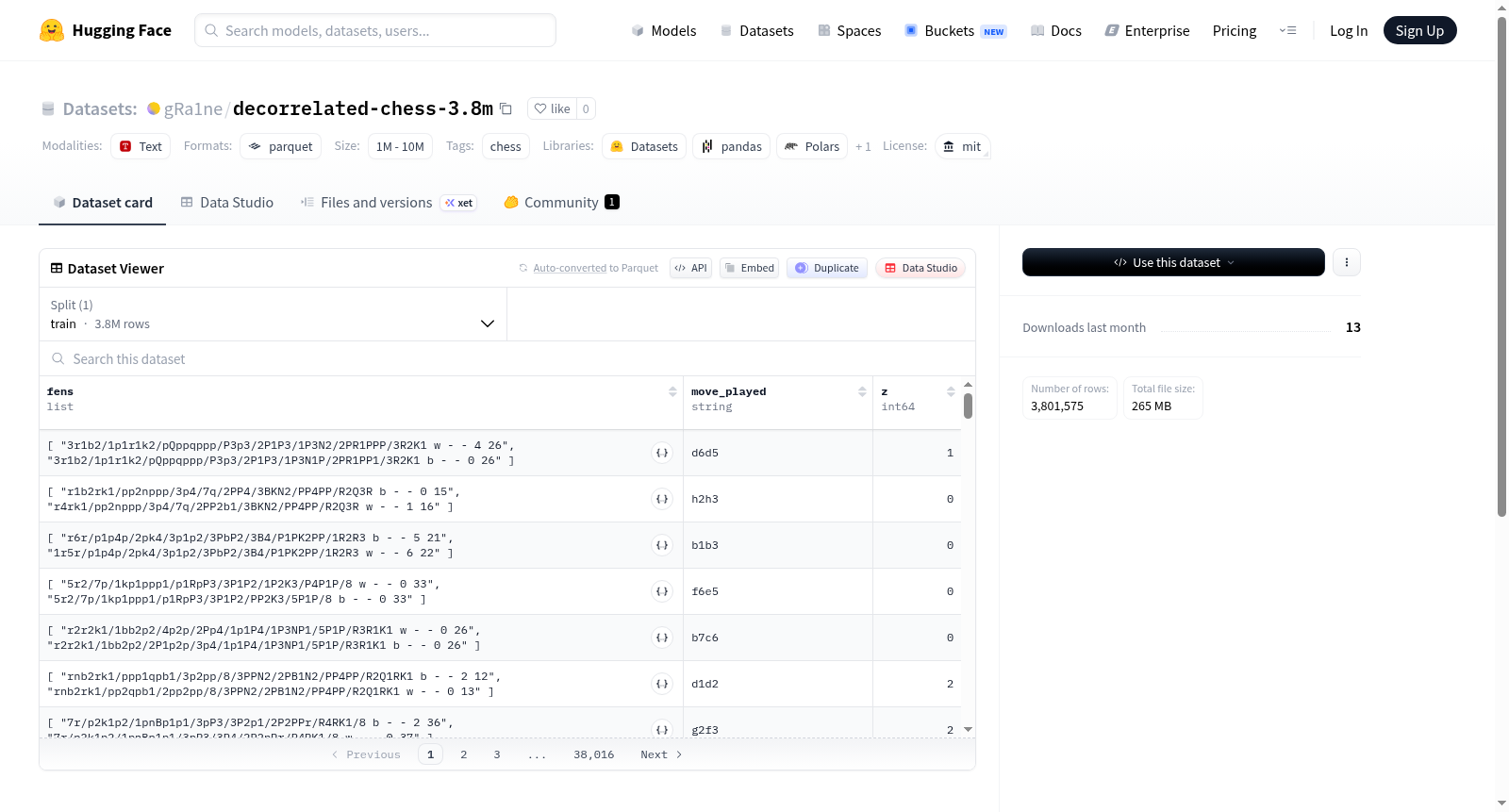
每条记录包含以下信息:
- 当前局面 FEN:当前棋局位置的 FEN 表示
- 上一局面 FEN:上一棋局位置的 FEN 表示
- 已走棋步(UCI 格式):在当前位置下的一步棋,以 UCI 标准格式记录
- 对局结果分类:
0= 黑方胜1= 白方胜2= 和棋
设计用途
- 作为训练中、小型国际象棋模型的 策略/价值网络 的高效数据集
- 适用于简单的深度学习策略与价值网络训练
搜集汇总
数据集介绍
构建方式
该数据集源自Lichess精英数据库,通过筛选3.8百万个国际象棋对局中的独立局面构建而成,确保每个局面均来自不同的对局,从而消除位置之间的相关性。每条记录包含当前局面的FEN编码与前一局面的FEN编码、以UCI格式记录的走法,以及游戏结局的分类标签(0代表黑方胜利,1代表白方胜利,2代表和棋)。这种设计旨在提供紧凑且无冗余的数据结构,便于高效存储与处理。
特点
数据集的核心特色在于其去相关化处理,每个局面均取自独立对局,避免了传统连续局面数据中存在的时序依赖,从而提升模型训练的泛化能力。同时包含三要素——局面编码、单步走法与结局标签,能够同时支持策略网络(policy network)与价值网络(value network)的监督学习任务。其规模适中(3.8M样本),契合中等规模国际象棋模型的轻量化训练需求。
使用方法
在应用层面,研究者可直接将FEN字符串作为输入特征,通过标准棋力编码(如位棋盘表示)转换成模型可处理的张量形式。UCI格式的走法可作为策略网络的监督目标,而结局分类标签则用于优化价值网络的回归或分类损失。建议采用随机抽样或批处理方式加载数据,避免因局面顺序引入偏差。数据集兼容常见深度学习框架(如PyTorch、TensorFlow),无需额外预处理即可进行模型训练。
背景与挑战
背景概述
在人工智能与棋类博弈的交叉领域中,国际象棋长期作为检验算法智能水平的基准平台。随着深度强化学习技术的演进,从AlphaZero等里程碑式工作起,策略-价值网络(Policy-Value Network)已成为实现高水平棋类智能的核心范式。然而,现有公开数据集多存在位置间高度相关或规模受限的问题,限制了模型泛化能力。decorrelated-chess-3.8m数据集于2023年由研究团队基于Lichess精英数据库构建,其核心创新在于从超过380万局独立对局中分别抽取一个位置,彻底打破样本间的时序关联,为中小型棋类模型的高效训练提供了去偏倚、低冗余的优质资源。该数据集以简洁的FEN与UCI格式存储,并标注胜负平结果,直接服务于策略输出与价值评估的双目标学习,对推动轻量化棋类AI的研究具有重要参考价值。
当前挑战
该数据集所解决的领域核心挑战在于,传统国际象棋数据集(如公开对局库)中连续位置高度自相关,导致策略-价值网络在训练时容易过拟合特定对局模式,无法习得普适的棋力评估与决策逻辑。此外,棋类状态空间呈指数级增长,如何从海量对局中高效筛选出具有代表性且互不依赖的样本以支撑模型泛化,是构建过程中的主要工程难题。具体挑战包括:1)从Lichess精英数据库数十亿对局中提取唯一位置时,需设计去重算法确保位置唯一性;2)平衡黑色胜、白色胜、和棋三类样本的比例,避免模型产生结果偏好;3)在3.8M级别规模下保持文件存储效率,适配GPU驱动的深度学习框架的数据加载管线和I/O性能,从而在有限计算资源下实现模型的有效收敛。
常用场景
经典使用场景
在国际象棋人工智能研究领域,decorrelated-chess-3.8m数据集凭借其精心设计的非相关性采样策略,成为训练小型至中型深度学习策略价值网络的标准基准资源。该数据集从Lichess精英数据库中提取380万个独立对局中的不相关局面,每个样本包含当前与上一棋局的FEN编码、UCI格式的落子及胜负平分类标签,为策略与价值网络的联合学习提供了高效且空间紧凑的训练语料。研究者常利用该数据集进行监督学习,训练模型在给定局面下预测最优走法并评估局面胜率,从而验证网络架构在有限参数量下的拟合能力与泛化性能。
衍生相关工作
该数据集衍生了若干经典工作,包括提出针对棋类策略网络的位置编码优化方法,以及对比不同残差网络结构在固定参数量下的学习效率。基于该数据集的训练范例被后续研究用于探索自蒸馏与知识迁移技术在棋类任务中的效果,例如将大型模型的知识压缩至满足该数据集设计要求的小型网络中。此外,部分工作借鉴其非相关采样理念,将类似的数据筛选策略扩展到围棋、将棋等复合规则游戏的数据集构建中,推动了领域内标准评估基准的统一与可比性。
数据集最近研究
最新研究方向
基于大量对局数据的解耦国际象棋数据集,为深度强化学习在小规模策略价值网络训练中提供了高效的数据支持,推动了智能博弈领域中离线学习方法的发展。该数据集从百万级精英对局中抽取独立局面,消除了序列相关性,使得模型能更专注于局部战术决策与全局胜负预测,进而提升了棋力评估的稳健性。当前研究趋势正利用此类解耦数据进行迁移学习与多任务建模,探索如何在有限算力下实现接近甚至超越人类冠军水平的对弈能力,对理解复杂博弈中的策略泛化具有深远意义。
以上内容由遇见数据集搜集并总结生成


