North-ML1/CodeBench-30
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/North-ML1/CodeBench-30
下载链接
链接失效反馈官方服务:
资源简介:
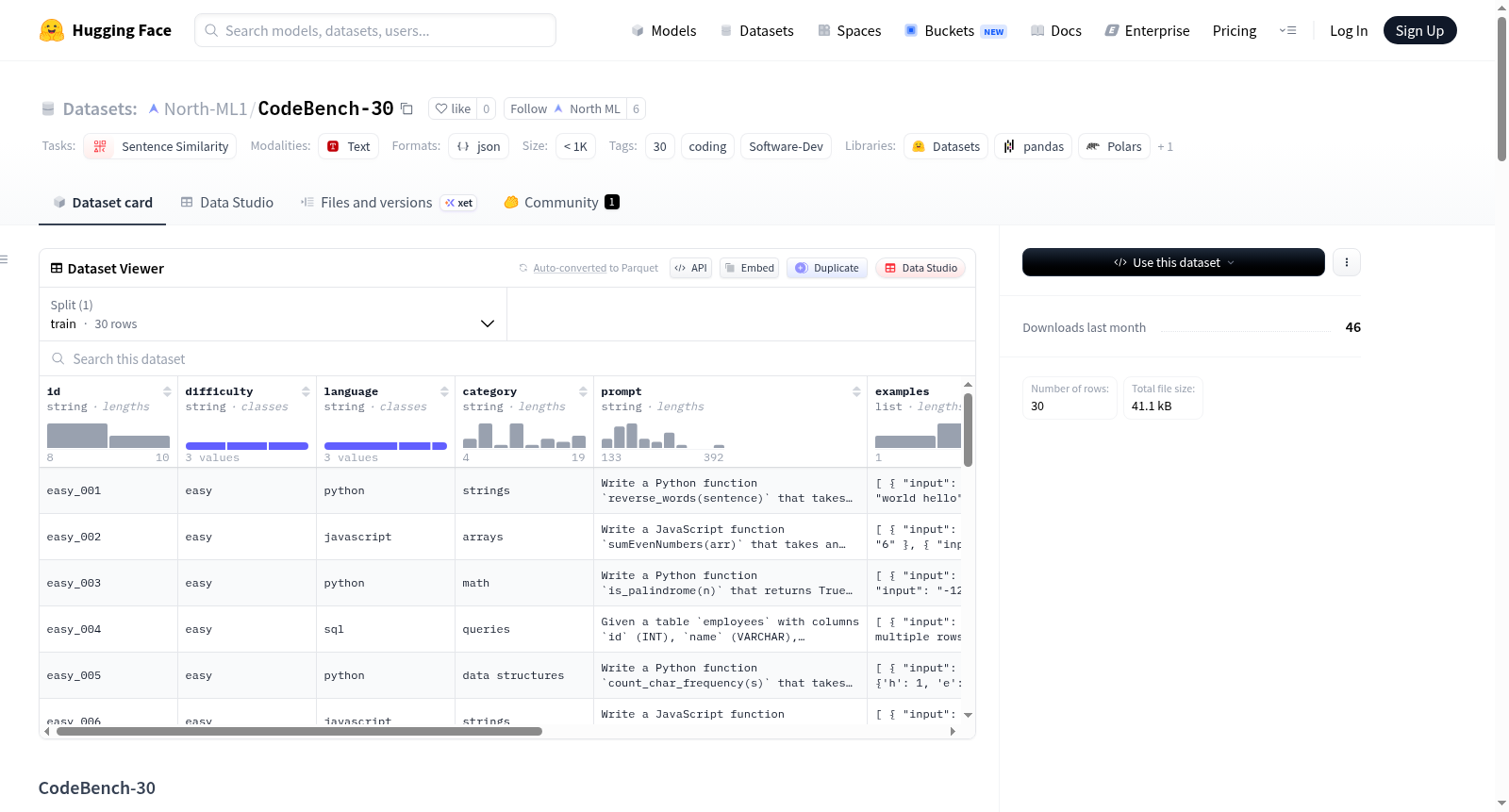
CodeBench-30是一个包含30个编程问题的基准数据集,旨在评估AI模型在不同语言、领域和难度级别上的编码能力。数据集包含10个简单、10个中等和10个困难的问题,支持Python、JavaScript和SQL语言。每个问题包含唯一标识符、难度级别、语言、类别标签、问题描述、示例输入输出、测试用例和参考解决方案。评估方法是通过比较模型生成的代码输出与预期输出。数据集还提供了按难度、语言和问题类别的详细分类,以及加载和使用数据集的示例代码。
CodeBench-30 is a benchmark dataset of 30 coding problems designed to evaluate AI model coding ability across languages, domains, and difficulty levels. The dataset includes 10 easy, 10 medium, and 10 hard problems, supporting Python, JavaScript, and SQL. Each problem contains a unique identifier, difficulty level, language, category tag, problem statement, example input/output pairs, test cases, and a reference solution. Evaluation is performed by comparing the models generated code output to the expected output. The dataset also provides detailed breakdowns by difficulty, language, and problem category, along with example code for loading and using the dataset.
提供机构:
North-ML1
搜集汇总
数据集介绍
构建方式
CodeBench-30数据集精心遴选了30道涵盖Python、JavaScript与SQL三种语言的编程问题,按照难度均匀划分为简单、中等、困难三个层级各10题。每道题目均包含唯一标识符、难度标签、编程语言、主题类别、问题陈述、示例输入输出对、用于评估的真值测试用例以及一份参考解决方案。数据集的构建借鉴了SWE-Bench的评估理念,强调基于真实问题情境,通过明确的预期输出结果进行模型能力的量化比较。
特点
该数据集的核心特色在于其多维度的评估视角。问题类型广泛覆盖算法、动态规划、数据结构、图论、字符串处理、SQL查询及窗口函数等多个领域,能够有效区分模型在不同技术栈与知识范畴上的表现。通过提供简单、中等、困难三级难度划分,以及按语言和类别进行细粒度评分,该数据集不仅能够衡量模型的整体编码能力,更能精准揭示其在特定领域(如滑动窗口、拓扑排序)或特定语言(如SQL窗口函数)中的优劣之处。
使用方法
使用CodeBench-30数据集评估模型时,需向模型呈现问题描述与可选示例,随后从其响应中提取生成的函数或查询代码。针对每道题目,逐一运行提供的测试用例,将模型输出与预期结果进行比对,计算通过测试用例的比例作为得分。建议采用Pass@1、Pass@k、总体准确率等多种指标,并按照难度、编程语言和问题类别分别进行统计,以形成全面且细致的模型编码能力评估报告。
背景与挑战
背景概述
CodeBench-30是一个于2025年发布的多语言代码生成基准数据集,由North-ML1团队构建,旨在系统评估AI模型在编程任务中的综合能力。不同于传统基准如HumanEval或MBPP,该数据集受SWE-Bench评估哲学启发,强调真实性问题、清晰预期输出与零歧义设计,覆盖Python、JavaScript和SQL三种编程语言,横跨基础操作、算法设计、数据结构与窗口函数等多个维度,为代码智能领域提供了更具挑战性与实用性的评估工具。其简洁而聚焦的30个问题设计,兼顾了评测效率与难度梯度,成为衡量大语言模型编码能力的有效标尺。
当前挑战
该数据集旨在解决当前AI代码生成评估中常见的三大挑战:一是多语言泛化能力不足,现有基准多集中于单一语言,难以全面反映模型在异构环境下的迁移表现;二是难度分层模糊,简单与困难任务混杂导致评分辨别力下降;三是评估指标单一,通常仅依赖Pass@1,缺乏对模型鲁棒性与覆盖率的细粒度刻画。在构建过程中,团队面临的挑战包括:如何精炼30个问题以覆盖核心编程范式而不失代表性;如何设计跨语言的一致性测试用例,避免语言特性引入评估偏差;以及如何在极小数据量下保持样本的挑战性与区分度,确保评测结果可信且可复现。
常用场景
经典使用场景
CodeBench-30作为评估人工智能模型编码能力的基准测试,其经典使用场景聚焦于对AI模型进行多维度、多层次的代码生成能力评测。具体而言,研究者将数据集中包含的30道编程题目作为标准化测试任务,涵盖Python、JavaScript和SQL三种编程语言,并细分为简单、中等、困难三个难度级别。每道题目均配备清晰的提示、示例输入输出对以及隐藏测试用例。模型需根据问题描述生成可执行的函数或查询代码,并通过与预期输出的精确比对来判定正确性,从而实现对模型编码流畅度与算法理解能力的系统性检验。
实际应用
在实际应用层面,CodeBench-30为技术企业筛选和优化AI辅助编程工具提供了便捷而可靠的试金石。开发团队可快速利用该基准对内部或第三方的代码生成模型进行性能摸底,识别其在特定语言(如SQL查询优化)或难度层级(如困难级算法)上的薄弱环节,从而指引模型微调方向。此外,教育科技平台也能借此设计自适应编程练习系统,依据模型在不同类别题目上的表现轨迹,为学习者推送个性化训练内容。该数据集的简洁规模与跨域覆盖特性,使其在持续集成管线中作为轻量级回归测试组件成为可能,保障模型迭代不牺牲编码能力。
衍生相关工作
CodeBench-30的发布孕育了多项富有启发性的衍生研究工作。一方面,它催生了针对细粒度编码能力分解的探索:研究者基于其按语言、难度和类别的标签结构,衍生出模型在特定范式(如动态规划、图遍历)上的失败模式分析,推动了可解释编码评估框架的构建。另一方面,该基准的紧凑格式激励了元学习与少样本提示策略的研究,例如利用30道题目的异步负载来设计自适应示例选择算法。此外,与其对标的同时代工作SWE-Bench形成互补——后者关注真实软件仓库修复,而CodeBench-30则聚焦于原子级算法能力,二者共同勾勒出从基础编码到工程化修复的全景评估图谱。
以上内容由遇见数据集搜集并总结生成


