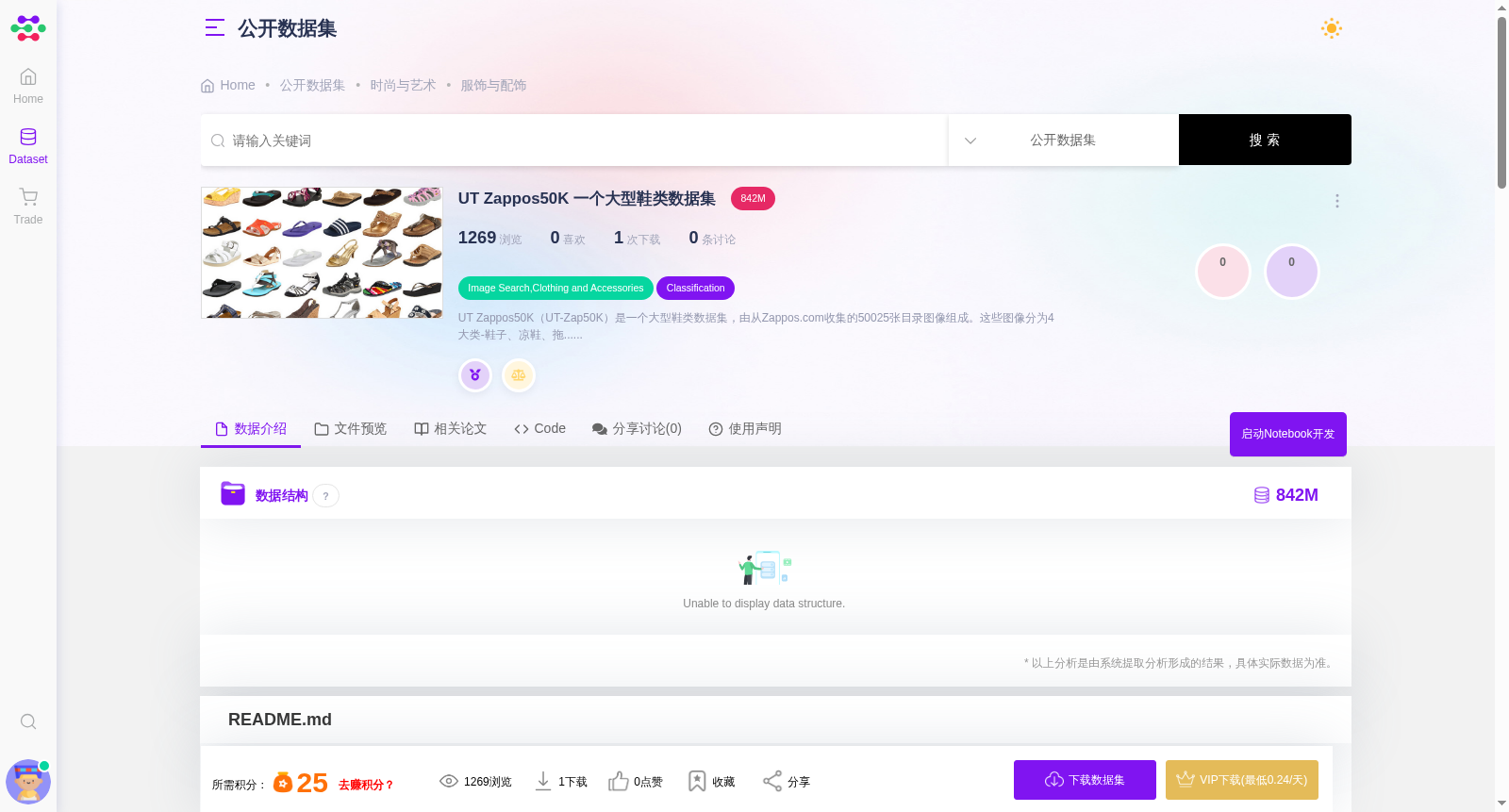
UT Zappos50K 一个大型鞋类数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-26611.html
下载链接
链接失效反馈官方服务:
资源简介:
UT Zappos50K(UT-Zap50K)是一个大型鞋类数据集,由从Zappos.com收集的50025张目录图像组成。这些图像分为4大类-鞋子、凉鞋、拖鞋和靴子,然后是功能类型和单个品牌。鞋子以白色背景为中心,并以相同的方向拍摄,以便于分析。 该数据集是在在线购物任务的上下文中创建的,用户特别关注细粒度的视觉差异。例如,购物者更有可能在两双类似的男士跑鞋之间做出选择,而不是在女士高跟鞋和男士拖鞋之间做出选择。提供GIST和LAB颜色特征。此外,每个图像都有8个相关的元数据(性别、材料等)标签,用于在Zappos.com上过滤鞋子。 我们在成对比较任务的上下文中引入了这个数据集,其中的目标是预测两个图像中的哪一个更强烈地表现出视觉属性。当给定一个新的图像对时,我们想回答这样一个问题:“图像a是否比图像B包含更多或更少的属性?”训练和评估都是使用成对标签进行的。 然而,这个数据集的有用性超出了我们所演示的比较任务。元数据标签和数据集的大尺寸也使其适用于其他任务,例如: 1、类别/品牌分类 2、基于理性的细粒度属性学习 3、特定性别的风格搭配 4、零样本学习 Annotations 使用Mechanical Turk,我们收集了4个相对属性的实例级别†比较标签:开放、尖尖、运动和舒适。我们从可能的50K²对中抽取了3000对图像,对类别内和性别内图像有强烈的偏见。我们要求5名工人评估每对属性(更多细节)。在剔除置信度或一致性较低的对之后,人类注释的示例由6751个有序对和4612个“相等”对组成。这被称为UT-Zap50K-1。 虽然“equal”标签可以表示属性中没有可检测的差异,但我们也怀疑这是一种简单的回退响应,适用于需要稍微思考的情况,即显示细粒度差异的情况。因此,我们将这些“相等”的对交给了一组新的工人,但这次没有“相等”选项。我们要求工人仔细挑选,并给出一句话的理由。修剪后,有4334个细粒度对。这被称为UT-Zap50K-2。 两组样本标签如下所示。66%的Zap50K-1和63%的Zap50 K-2员工至少有四分之五的员工对同一标签有高度的信心,确保了一致性和可靠性。 †UT-Zap50K包含迄今为止最大的实例级别(单个图像)比较标签。现有数据集中包含的比较标签是在类别级别(图像组)收集的。 Benchmarks 我们提供了本文中用于基准测试的列车测试分割。我们还提供了一个演示脚本,以帮助进行相对属性预测的实验设置。UT-Zap50K-1当前基准的ROC曲线如下所示。图例中的数字表示平均排名精度。 Fine-Grained Lexicon 此外,我们还收集了另一组为细粒度比较任务定制的数据。这样的学习任务需要强调图像对之间微妙之处的训练数据。为此,我们(1)使用众包挖掘明确细粒度的属性词典,(2)为词典中的每个属性收集了更多的实例级比较标签。 给出一对图片,我们让工人用一个单词完成句子“Shoe a比Shoe B多一点他们被指示识别图像之间的细微差异,并提供简短的理由。目标是找出人们如何区分鞋子图像之间的细微差别。超过1000名工作人员参与了这项研究,在观看的4000对图片中,共产生了350+个不同的单词建议。 上面的单词cloud表示原始结果,然后我们根据基本原理和同义词的合并对其进行后期处理。最后,最常见的10个词构成了我们新的细粒度相对属性词典:舒适、休闲、简单、运动、多彩、耐用、支持、大胆、时尚和开放。我们为每个属性收集了4000个有序对的人类注释。
UT Zappos50K (UT-Zap50K) is a large-scale footwear dataset consisting of 50,025 catalog images collected from Zappos.com. The images are categorized into four major categories—shoes, sandals, slippers, and boots—with further divisions by functional type and individual brand. All footwear images are centered on a white background and captured in a consistent orientation to facilitate analysis. This dataset was developed in the context of online shopping tasks, where users pay particular attention to fine-grained visual differences. For example, shoppers are far more likely to make choices between two pairs of similar men’s running shoes than between women’s high heels and men’s slippers. GIST and LAB color features are provided for the dataset. Additionally, each image is paired with 8 relevant metadata labels (e.g., gender, material) used for filtering footwear on Zappos.com.
We introduced this dataset in the context of pairwise comparison tasks, where the goal is to predict which of two images exhibits a given visual attribute more strongly. Given a new image pair, we aim to answer the question: "Does image A contain more or less of the attribute than image B?" Both training and evaluation are conducted using pairwise labels. However, the utility of this dataset extends beyond the comparison tasks we demonstrate. The metadata labels and the large scale of the dataset also make it applicable to other tasks, such as:
1. Category/brand classification
2. Rationality-based fine-grained attribute learning
3. Gender-specific style matching
4. Zero-shot learning
### Annotations
Using Mechanical Turk, we collected instance-level comparative labels for four relative attributes: open, pointed, sporty, and comfortable. We sampled 3,000 image pairs from the 50K² possible pairs, with a strong bias towards intra-category and intra-gender images. We required 5 workers to evaluate each pair for a given attribute (for more details). After filtering out pairs with low confidence or consistency, the human-annotated samples consist of 6,751 ordered pairs and 4,612 "equal" pairs. This subset is referred to as UT-Zap50K-1. While the "equal" label can indicate no detectable difference in the attribute, we also suspect it serves as a simplistic fallback response for cases that require more nuanced judgment, i.e., those with fine-grained differences between images. Therefore, we had a new set of workers re-annotate these "equal" pairs, this time without the "equal" option. We instructed workers to choose carefully and provide a one-sentence justification. After pruning, there are 4,334 fine-grained pairs. This subset is referred to as UT-Zap50K-2.
The label agreement for both subsets is as follows. 66% of the UT-Zap50K-1 samples and 63% of the UT-Zap50K-2 samples have at least four out of five workers agreeing strongly on the same label, ensuring annotation consistency and reliability. † UT-Zap50K contains the largest instance-level (single-image) comparative labels to date. Comparative labels included in existing datasets are typically collected at the category level (image groups).
### Benchmarks
We provide the train-test splits used for benchmarking in this paper. We also provide a demo script to assist with experimental setup for relative attribute prediction. The ROC curves for the current UT-Zap50K-1 benchmark are shown below. The numbers in the legend indicate mean ranking accuracy.
### Fine-Grained Lexicon
In addition, we collected another dataset tailored for fine-grained comparison tasks. Such learning tasks require training data that emphasizes the subtle differences between image pairs. To this end, we (1) mined explicit fine-grained attribute lexicons via crowdsourcing, and (2) collected additional instance-level comparative labels for each attribute in the lexicon. Given a pair of images, we asked workers to complete the sentence "Shoe A is more [X] than Shoe B," where they were instructed to identify subtle differences between the images and provide a brief justification. The goal was to uncover how people distinguish subtle differences between footwear images. Over 1,000 workers participated in this study, yielding more than 350 distinct word suggestions from the 4,000 image pairs viewed. We first normalized the raw results using the root word cloud, then performed post-processing by merging base terms and synonyms. Finally, the 10 most common terms form our new fine-grained relative attribute lexicon: comfortable, casual, simple, sporty, colorful, durable, supportive, bold, stylish, and open. We collected 4,000 human-annotated ordered pairs for each attribute.
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
UT Zappos50K是一个包含50025张鞋类图像的大型数据集,分为鞋子、凉鞋、拖鞋和靴子四大类,适用于细粒度视觉比较、分类和零样本学习等任务。数据集还提供了丰富的元数据标签和人类注释的比较标签,支持多种计算机视觉研究。
以上内容由遇见数据集搜集并总结生成


