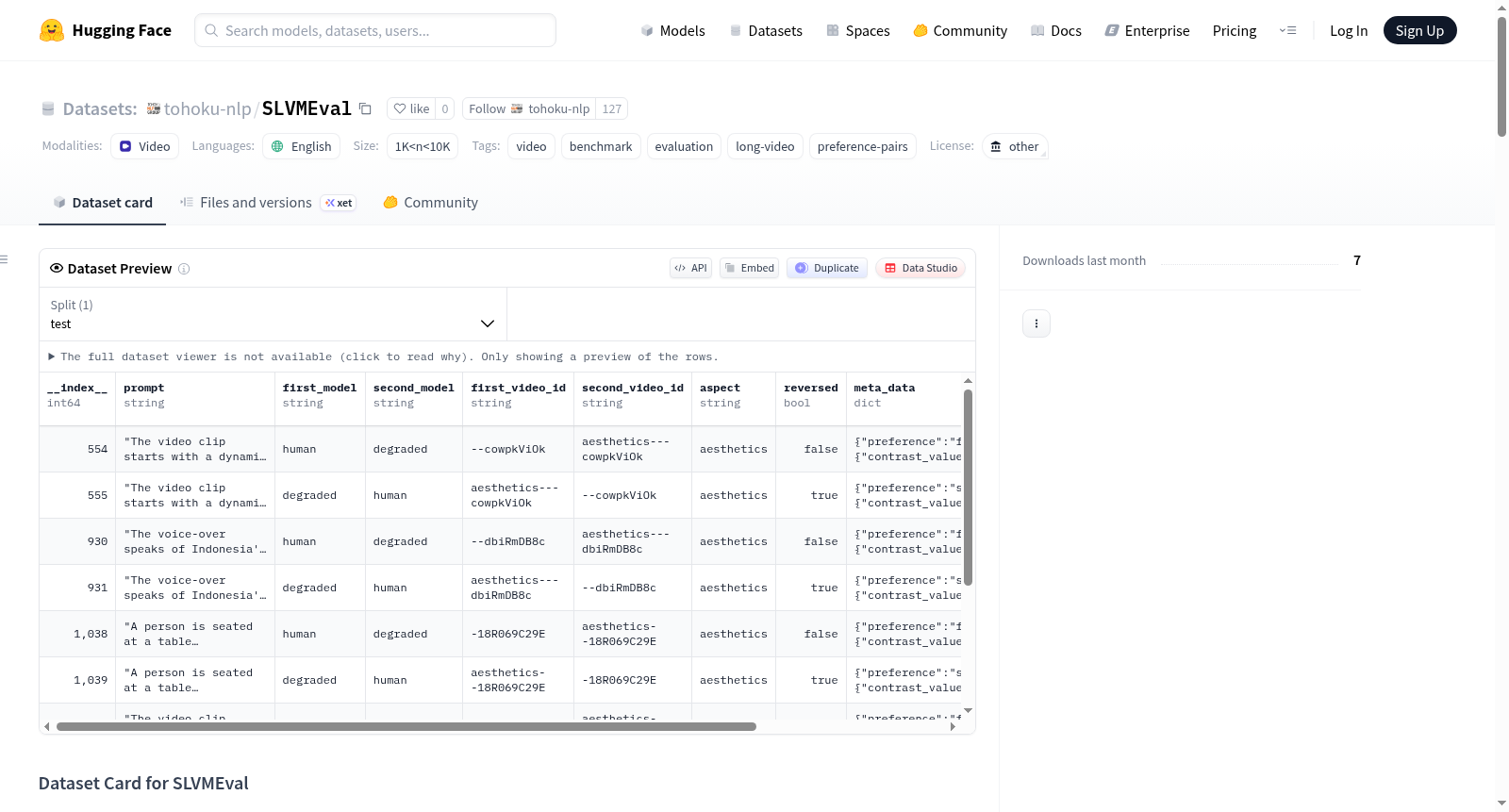
SLVMEval
收藏SLVMEval 数据集概述
数据集简介
SLVMEval(Synthetic Long-Video Meta-Evaluation Benchmark)是一个用于元评估文本到长视频(T2LV)生成任务的自动评估系统的基准。该基准采用基于成对比较的设置,通过对源视频应用特定方面的合成退化,构建受控的高质量与低质量长视频对。最终基准数据通过保留人类已验证的、退化清晰可辨的视频对来构建。
数据内容与结构
本次发布的基准数据位于 SLVMEval/degraded/degrade_5clip/ 目录下,包含以下10个方面的评估数据:
- 美学(Aesthetics)
- 技术质量(Technical Quality)
- 外观风格(Appearance Style)
- 背景一致性(Background Consistency)
- 时间流(Temporal Flow)
- 全面性(Comprehensiveness)
- 对象完整性(Object Integrity)
- 空间关系(Spatial Relationship)
- 动态程度(Dynamics Degree)
- 颜色(Color)
每个方面(aspect)的子目录中包含以下文件:
cleaned_sampled_test.jsonldegraded_video_data.jsonlvideos.zipframes.zip
解压后,每个方面的目录结构如下:
<aspect>/ ├── cleaned_sampled_test.jsonl ├── degraded_video_data.jsonl ├── videos/ │ └── <video_id>.mp4 └── frames/ └── <video_id>/ ├── 000001.jpg └── ...
数据字段说明
cleaned_sampled_test.jsonl
每一行对应一个成对评估样本,主要字段包括:
__index__promptfirst_model,second_modelfirst_video_id,second_video_idaspectreversedmeta_data.preference
degraded_video_data.jsonl
包含 cleaned_sampled_test.jsonl 中引用的视频元数据记录,主要字段包括:
video_idpathfpsframe_pathspredicted_clips(包含span,clip_id,path等信息)meta_data
数据统计
| 方面 | 清理后样本行数 | 退化视频行数 | 视频文件数 | 帧目录数 |
|---|---|---|---|---|
| 美学(aesthetics) | 564 | 282 | 282 | 282 |
| 背景一致性(background_consistency) | 708 | 354 | 354 | 354 |
| 颜色(color) | 408 | 204 | 204 | 204 |
| 动态程度(dynamics_degree) | 666 | 333 | 333 | 333 |
| 时间流(move_scene) | 570 | 285 | 285 | 285 |
| 对象完整性(object_removal) | 200 | 100 | 100 | 100 |
| 全面性(scene) | 470 | 235 | 235 | 235 |
| 空间关系(spatial_relationship) | 472 | 236 | 236 | 236 |
| 外观风格(style) | 624 | 312 | 312 | 312 |
| 技术质量(technical_quality) | 260 | 130 | 130 | 130 |
| 总计 | 4942 | 2471 | 2471 | 2471 |
使用许可与限制
- 本数据集仅供学术和非商业研究使用。
- 未经许可,禁止重新分发或重新上传。
- 上游源数据(包括Vript和原始视频平台)仍受其原始条款约束。
- 本次发布不重新分发完整的上游源数据集本身。
- 如果上游源条款更严格,则以上游条款为准。
引用
如需使用此数据集,请引用以下论文:
@inproceedings{matsuda2026slvmeval, title = {SLVMEval: Synthetic Meta Evaluation Benchmark for Text-to-Long Video Generation}, author = {Ryosuke Matsuda and Keito Kudo and Haruto Yoshida and Nobuyuki Shimizu and Jun Suzuki}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2026} }