African Language Parallel Sentences Collection
收藏github2025-04-03 更新2025-04-18 收录
下载链接:
https://github.com/michsethowusu/African-Language-Parallel-Sentences-Collection
下载链接
链接失效反馈官方服务:
资源简介:
该数据集集合包括非洲语言的句子对及其相似度分数,可用于机器翻译、句子对齐或其他自然语言处理任务。
This dataset collection includes sentence pairs in African languages and their corresponding similarity scores, which can be applied to machine translation, sentence alignment, and other natural language processing tasks.
创建时间:
2025-03-30
原始信息汇总
African Language Parallel Sentences Collection 数据集概述
数据集简介
- 该数据集包含非洲语言之间的平行句子对及相似度评分。
- 适用于机器翻译、句子对齐等自然语言处理任务。
- 基于Meta主导的开源项目NLLBv1数据集构建。
数据来源
- 原始数据发布平台:OPUS - NLLB-v1 (https://opus.nlpl.eu/legacy/NLLB-v1.php)
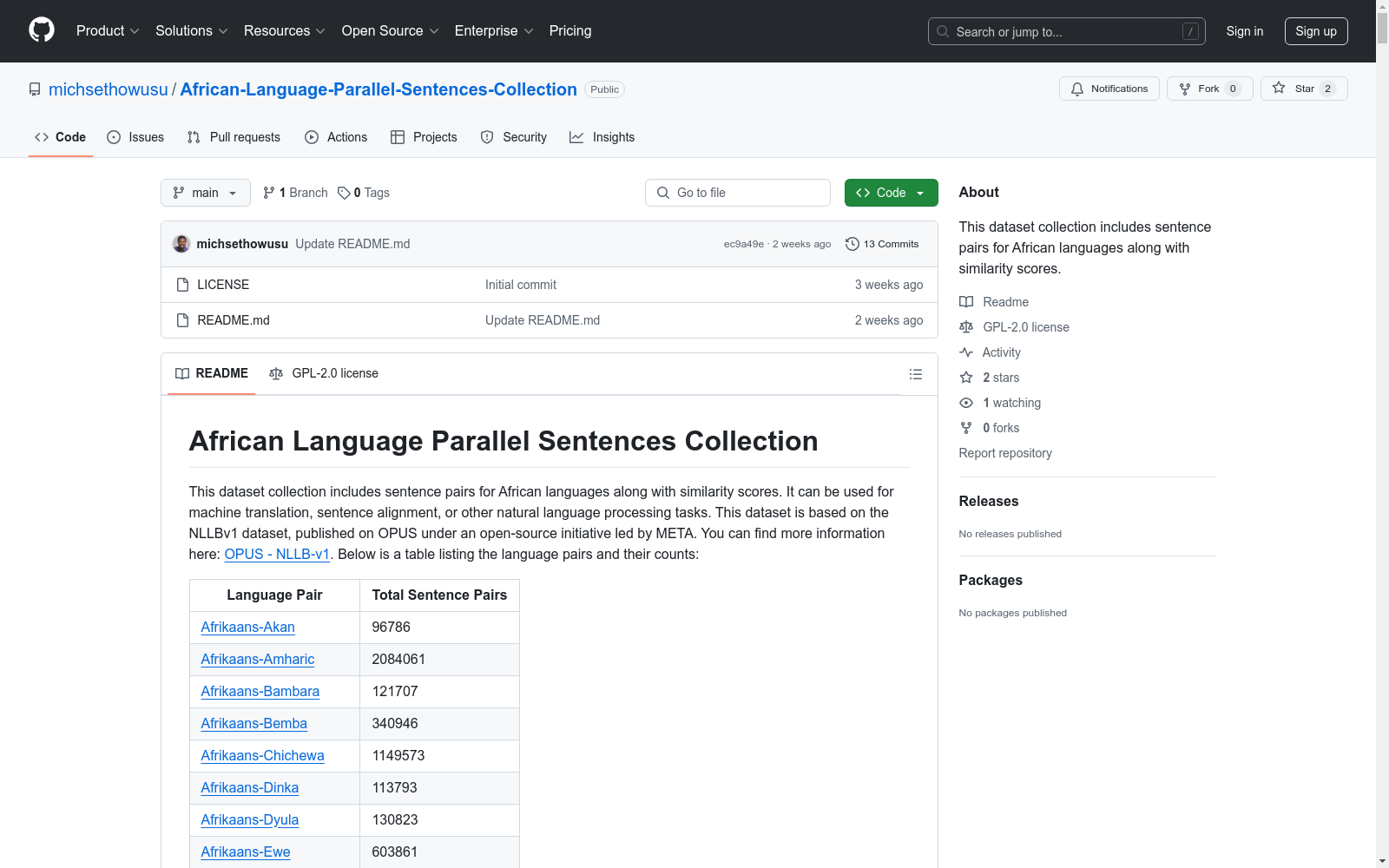
语言对统计
- 包含超过100种非洲语言组合的平行句对
- 主要语言对示例及数量:
| 语言对 | 句子对数量 |
|---|---|
| Afrikaans-Akan | 96,786 |
| Afrikaans-Amharic | 2,084,061 |
| Afrikaans-Bambara | 121,707 |
| Afrikaans-Bemba | 340,946 |
| Afrikaans-Chichewa | 1,149,573 |
| Afrikaans-Dinka | 113,793 |
| Afrikaans-Dyula | 130,823 |
| Afrikaans-Ewe | 603,861 |
| Afrikaans-Fon | 250,256 |
| Afrikaans-Fulah | 168,993 |
| Afrikaans-Ganda | 477,039 |
| Afrikaans-Hausa | 1,915,829 |
| Afrikaans-Igbo | 820,401 |
| Afrikaans-Kamba | 99,195 |
| Afrikaans-Kikuyu | 127,764 |
| Afrikaans-Kinyarwanda | 1,042,316 |
| Afrikaans-Kongo | 199,797 |
| Afrikaans-Lingala | 346,128 |
| Afrikaans-Nuer | 51,337 |
| Afrikaans-Oromo | 471,696 |
| Afrikaans-Pedi | 408,589 |
| Afrikaans-Rundi | 538,952 |
| Afrikaans-Shona | 1,293,875 |
| Afrikaans-Somali | 1,432,523 |
| Afrikaans-Swahili | 2,454,143 |
| Afrikaans-Swati | 184,251 |
| Afrikaans-Tigrinya | 454,330 |
| Afrikaans-Tsonga | 554,518 |
| Afrikaans-Tswana | 779,255 |
| Afrikaans-Tumbuka | 407,317 |
| Afrikaans-Twi | 567,621 |
| Afrikaans-Umbundu | 205,246 |
| Afrikaans-Wolof | 237,043 |
| Afrikaans-Xhosa | 1,361,566 |
| Afrikaans-Yoruba | 1,775,488 |
| Afrikaans-Zulu | 1,771,278 |
数据集特点
- 覆盖语言广泛:包含阿非利卡语、阿姆哈拉语、班巴拉语等非洲主要语言
- 数据规模大:多个语言对超过百万级平行句对
- 质量可靠:基于经过验证的NLLBv1数据集构建
典型应用场景
- 非洲语言机器翻译模型训练
- 跨语言信息检索
- 多语言自然语言处理研究
- 低资源语言处理技术开发
搜集汇总
数据集介绍
构建方式
African Language Parallel Sentences Collection数据集基于META主导的开源项目NLLBv1构建,通过OPUS平台发布。该数据集涵盖了多种非洲语言之间的平行句对,包括阿非利卡语、阿姆哈拉语、班巴拉语等,每种语言对的句子数量从数千到数百万不等。数据集的构建过程涉及大规模的多语言文本对齐和相似度评分,确保了句对的质量和可用性。
特点
该数据集以其广泛的非洲语言覆盖和丰富的平行句对数量著称。不仅包含了主流非洲语言,还涵盖了如迪尤拉语、丰语等较少见的语言变体。每个句对都经过相似度评分,为机器翻译、句子对齐等自然语言处理任务提供了高质量的训练数据。数据规模从数万到数百万不等,能满足不同研究需求。
使用方法
用户可通过Hugging Face平台直接访问各语言对的子数据集,每个子数据集均以标准化格式存储。数据集适用于机器翻译模型训练、跨语言信息检索等任务。研究人员可根据语言对编号调用特定数据,或利用相似度评分进行数据筛选。数据集的开放协议允许学术和商业用途,但需遵守META的原始授权条款。
背景与挑战
背景概述
African Language Parallel Sentences Collection数据集由META公司主导的开源项目NLLBv1衍生而来,发布于OPUS平台,旨在为非洲语言提供高质量的平行句对资源。该数据集涵盖了包括阿非利卡语、阿姆哈拉语、班巴拉语等在内的多种非洲语言,涉及数十种语言对的平行句对,规模从数万到数百万不等。其核心研究问题在于解决非洲语言在机器翻译、句子对齐等自然语言处理任务中数据稀缺的困境,为语言技术在这类低资源语言中的发展奠定基础。该数据集的创建标志着非洲语言计算研究迈入新阶段,对促进语言平等和数字包容具有深远意义。
当前挑战
该数据集面临的核心挑战体现在两个方面:领域问题层面,非洲语言普遍存在形态复杂、方言变体多、书写系统不统一等语言学特性,这对平行语料的质量控制与评估标准提出了特殊要求;构建过程层面,低资源语言的原始语料获取困难,多数语种缺乏专业标注人员,导致数据清洗和对齐工作面临严峻的人力资源挑战。同时,部分语言对的平行数据量级差异显著(如阿非利卡语-斯瓦希里语达245万句对,而阿坎语-努尔语仅8534句对),这种数据不平衡性可能影响多语言模型的训练效果。
常用场景
经典使用场景
在跨语言自然语言处理研究中,African Language Parallel Sentences Collection数据集为非洲语言之间的机器翻译任务提供了丰富的平行语料资源。该数据集包含数十种非洲语言的高质量句对,覆盖了从南非荷兰语到约鲁巴语等广泛语种,为低资源语言处理领域填补了重要空白。研究者可利用其开展多语言神经机器翻译模型的训练与评估,特别是在处理语言形态复杂、语序差异显著的非洲语言时展现出独特价值。
实际应用
在非洲数字化进程中,该数据集支撑了多语言教育平台、跨境商务沟通系统等实际应用的开发。基于该数据训练的翻译模型已应用于非洲联盟文件本地化、公共卫生信息多语言传播等场景。特别是在新冠疫情等紧急事态下,为医疗信息在斯瓦希里语、豪萨语等主要非洲语言间的快速转换提供了关键技术保障。
衍生相关工作
该数据集催生了包括AfriMT在内的系列重要研究,推动了《No Language Left Behind》等国际项目的进展。基于此开发的AfriBERTa模型在非洲语言理解任务中取得突破性表现,相关成果被ACL、EMNLP等顶会收录。后续工作进一步扩展了其在语音合成、跨语言信息检索等方向的应用边界。
以上内容由遇见数据集搜集并总结生成


