有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
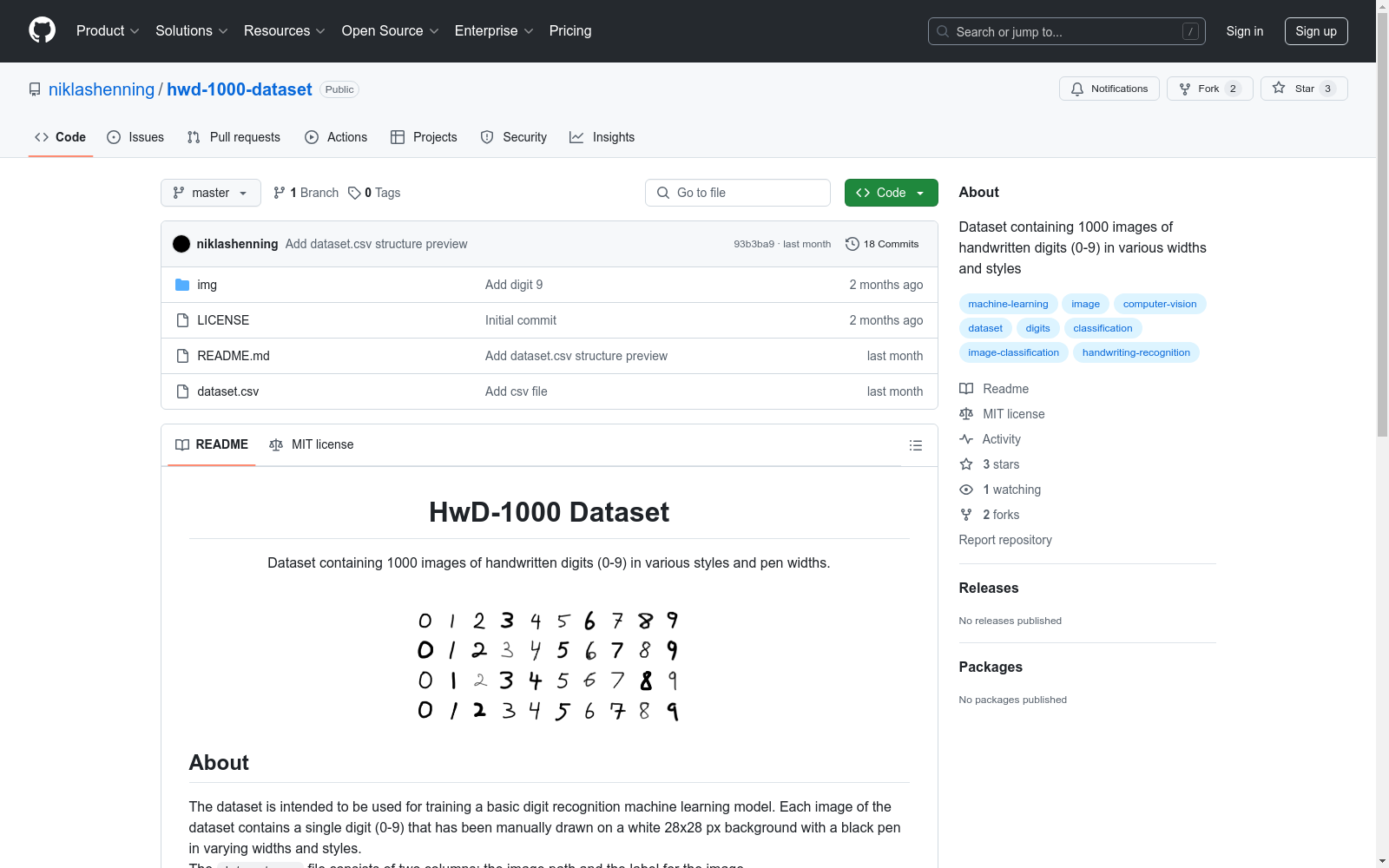
安装: 通过克隆仓库并复制dataset.csv文件和img文件夹到项目中。
bash
git clone https://github.com/niklashenning/hwd-1000-dataset
使用: dataset.csv文件包含两列:图像路径和图像标签。可以使用pandas的read_csv()方法创建数据框。
python
import pandas as pd
dataframe = pd.read_csv(dataset.csv)
Latest Website Checks for Flixtor.to
A list of the latest status checks for flixtor.to with up/down, ping time and http loading time.
doj.me 收录
CACD
跨年龄名人数据集是用于跨年龄人脸识别和检索的数据集。它包含 2,000 位名人的 163,446 张图像。该数据集于 2014 年由马里兰大学计算机科学系发表,论文名为 cross-age Reference Coding for Age-invariant Face Recognition and Retrieval。
OpenDataLab 收录
BaiJia
BaiJia是一个由中国北京邮电大学创建的大规模历史角色扮演数据集,旨在为大语言模型提供低资源的历史角色扮演数据。该数据集包含19281个中国历史人物的信息,涵盖了唐、宋、元、明、清五个朝代。数据集的内容包括人物的传记、文学作品、家庭关系、历史事件等,数据来源广泛,包括历史文献、古籍、艺术作品、民间传说和口述传统。数据集的创建过程包括从多个来源收集人物简历、生成对话以及构建评估问题。该数据集的应用领域主要是增强大语言模型在历史角色扮演任务中的表现,旨在解决历史文本碎片化和多模态数据整合的挑战。
arXiv 收录
CFBenchmark
CFBenchmark是一个专为评估大型语言模型在中文金融助理领域性能而设计的数据集。由同济大学和上海人工智能实验室联合创建,该数据集包含3917个金融文本,覆盖金融识别、分类和生成三大方面,共计八个任务。数据集内容丰富,包括金融新闻和研究报告,文本长度从50字到超过1800字不等,旨在全面测试模型在金融文本处理中的基本能力。创建过程中,专业研究人员对文本进行了严格的筛选和标注,确保数据质量。CFBenchmark的应用领域广泛,主要用于提升金融决策的自动化和智能化水平,解决金融文本处理中的关键问题。
arXiv 收录
FAOSTAT Agricultural Data
FAOSTAT Agricultural Data 是由联合国粮食及农业组织(FAO)提供的全球农业数据集。该数据集涵盖了农业生产、贸易、价格、土地利用、水资源、气候变化、人口统计等多个方面的详细信息。数据包括了全球各个国家和地区的农业统计数据,旨在为政策制定者、研究人员和公众提供全面的农业信息。
www.fao.org 收录