lastfm-1k
收藏Hugging Face2025-03-21 更新2025-03-22 收录
下载链接:
https://huggingface.co/datasets/matthewfranglen/lastfm-1k
下载链接
链接失效反馈官方服务:
资源简介:
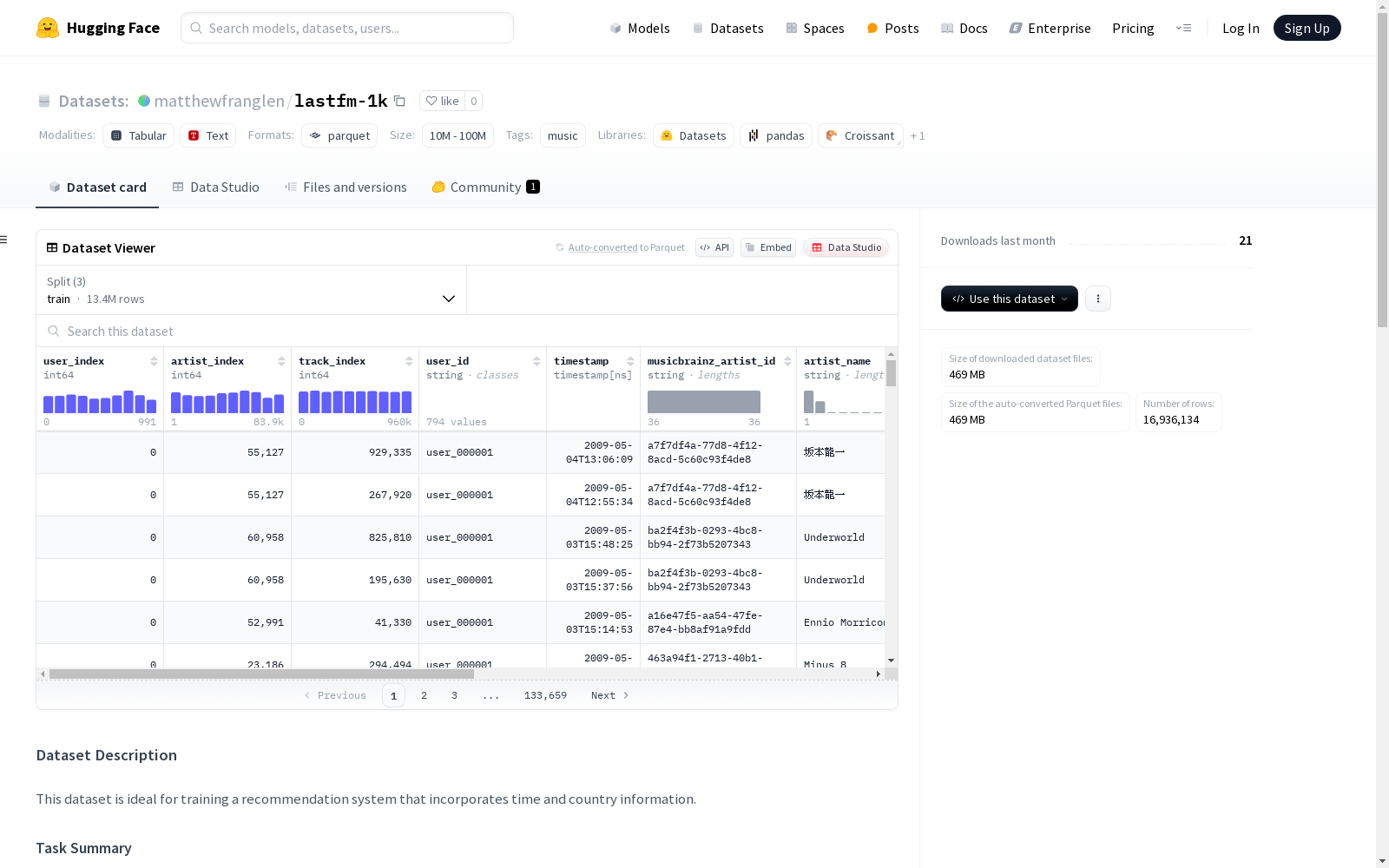
Last.fm用户艺术家歌曲数据集是一个适用于训练包含时间和国家信息的推荐系统的理想数据集。它包含了用户、时间戳、艺术家和歌曲记录,并可能包含用户的性别、年龄和位置等额外信息。这些额外信息是可选的且未经验证。数据集通过移除缺少音乐大脑兹标识符的行来提高可用性。训练、验证和测试集使用了不重叠的独立用户。为了便于训练,数据集添加了用户索引、艺术家索引和曲目索引这三个整数列,分别唯一标识每个用户、艺术家和曲目。
The Last.fm User-Artist-Song Dataset is an ideal dataset for training recommendation systems that incorporate temporal and regional information. It contains user, timestamp, artist, and song records, and may also include supplementary information such as the user's gender, age, and location. This supplementary information is optional and unverified. The dataset improves usability by removing rows that lack MusicBrainz identifiers. Non-overlapping and independent users are utilized for the training, validation, and test splits. To facilitate model training, the dataset adds three integer columns: user index, artist index, and track index, which uniquely identify each user, artist, and track respectively.
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
Last.fm-1k数据集构建于Last.fm平台的用户音乐收听记录,涵盖了用户、时间戳、艺术家和歌曲信息。数据集通过剔除缺少MusicBrainz标识符的记录,确保了数据的完整性和一致性。为了便于模型训练,数据集进一步引入了用户索引、艺术家索引和曲目索引,这些索引以整数的形式唯一标识每个用户、艺术家和曲目。数据集被划分为训练集、验证集和测试集,且各集合之间用户无重叠,确保了模型评估的独立性。
特点
Last.fm-1k数据集的特点在于其丰富的用户行为记录,包括用户的性别、年龄和地理位置等可选信息,尽管这些信息未经验证。数据集特别适用于推荐系统的训练,因为它不仅提供了用户与音乐之间的交互数据,还包含了时间和国家信息,这对于构建基于上下文感知的推荐系统至关重要。此外,数据集的规模适中,介于1000万到1亿条记录之间,适合进行大规模机器学习实验。
使用方法
Last.fm-1k数据集主要用于训练和评估音乐推荐系统。研究人员和开发者可以利用该数据集中的用户、艺术家和歌曲索引来构建和优化推荐算法。数据集的分割方式允许用户在不同的子集上进行模型的训练、验证和测试,从而全面评估模型的性能。此外,数据集中的时间和国家信息可以用于探索推荐系统的上下文敏感性,提高推荐的个性化和准确性。使用该数据集时,需遵守Last.fm的非商业使用许可,并在相关研究中引用Last.fm的原始数据来源。
背景与挑战
背景概述
Last.fm-1k数据集由Òscar Celma于2010年创建,旨在为音乐推荐系统的研究提供支持。该数据集包含了用户的听歌记录、时间戳、艺术家和歌曲信息,部分用户还提供了性别、年龄和地理位置等附加信息。这些数据来源于Last.fm的“scrobbling”服务,用户可以通过该服务记录在其他应用中的听歌行为。Last.fm-1k数据集在音乐推荐领域具有重要影响力,尤其是在基于用户行为的隐式反馈推荐系统研究中,为探索个性化音乐推荐算法提供了丰富的实验数据。
当前挑战
Last.fm-1k数据集在构建和应用中面临多重挑战。首先,推荐系统领域的一个核心问题是缺乏负样本,即用户未与某些歌曲或艺术家互动的记录,这使得模型训练难以捕捉用户的真实偏好。其次,数据集中存在部分未验证的用户信息,如性别和年龄,可能影响模型的泛化能力。此外,由于音乐标识符(如MusicBrainz ID)的缺失,部分记录可能存在歧义,增加了数据清洗和预处理的复杂性。最后,如何有效利用时间戳和地理位置等上下文信息,进一步提升推荐系统的性能,也是该数据集应用中的一大挑战。
常用场景
经典使用场景
Last.fm-1k数据集在音乐推荐系统领域具有广泛的应用。通过该数据集,研究人员可以训练模型以预测用户可能喜欢的音乐艺术家或歌曲。数据集中的时间戳和用户地理位置信息为推荐系统提供了额外的上下文,使得模型能够更好地理解用户的音乐偏好随时间的变化以及地域文化对音乐选择的影响。
实际应用
在实际应用中,Last.fm-1k数据集被广泛用于音乐流媒体平台的个性化推荐系统开发。通过分析用户的听歌历史和行为模式,平台可以为用户生成个性化的播放列表,提升用户体验。此外,该数据集还可用于音乐市场分析,帮助音乐公司了解不同地区用户的音乐偏好,从而优化音乐推广策略。
衍生相关工作
基于Last.fm-1k数据集,许多经典的研究工作得以展开。例如,Celma在其著作《Music Recommendation and Discovery in the Long Tail》中详细探讨了如何利用该数据集进行长尾音乐推荐。此外,该数据集还被用于研究基于时间序列的推荐算法、跨领域推荐系统以及用户行为建模等前沿课题,推动了推荐系统领域的发展。
以上内容由遇见数据集搜集并总结生成


