TEPE-TCI-370h
收藏arXiv2026-03-25 更新2026-03-27 收录
下载链接:
https://qingyonghu.github.io/Interaction2Eval/
下载链接
链接失效反馈官方服务:
资源简介:
TEPE-TCI-370h是由香港中文大学·深圳联合国防科技大学构建的首个中国幼儿园自然师生互动大规模数据集,包含105个班级370小时的课堂录音。数据通过专业设备采集,覆盖集体活动、自由游戏等多元场景,并采用ECQRS-EC和SSTEW标准进行专家标注,包含206个教学质量指标。该数据集专为AI辅助教育评估设计,通过解决儿童语音识别、普通话同音歧义等挑战,支持从音频中自动提取结构化质量指标,可显著提升学前教育质量监测效率,推动从年度人工评估向持续AI辅助监测的范式转变。
TEPE-TCI-370h is the first large-scale dataset of natural teacher-student interactions in Chinese kindergartens, jointly developed by The Chinese University of Hong Kong, Shenzhen and the National University of Defense Technology. It contains 370 hours of classroom audio recordings from 105 classes. The data was collected with professional-grade equipment, covering diverse scenarios including group activities and free play. It was expertly annotated in accordance with the ECQRS-EC and SSTEW standards, and includes 206 teaching quality indicators. This dataset is specifically designed for AI-assisted education assessment. By addressing challenges such as children's speech recognition and Mandarin homonym ambiguity, it supports the automatic extraction of structured quality indicators from audio. It can significantly improve the efficiency of preschool education quality monitoring, and promote the paradigm shift from annual manual assessment to continuous AI-assisted monitoring.
提供机构:
国防科技大学; 香港中文大学·深圳; 牛津大学
创建时间:
2026-03-25
原始信息汇总
数据集概述:TEPE-TCI-370h
数据集基本信息
- 数据集名称:TEPE-TCI-370h
- 所属研究:When AI Meets Early Childhood Education: Large Language Models as Assessment Teammates in Chinese Preschools
- 发表会议:27th International Conference on Artificial Intelligence in Education (AIED 2026)
- 数据集定位:首个中国学龄前自然情境下师幼互动的大规模语料库,带有专家级别的标准化标注。
数据集规模与构成
- 音频时长:370+ 小时
- 覆盖范围:来自中国41所公立幼儿园(涵盖区级、市级、省级不同质量等级)的105个教室。
- 儿童年龄:3–4岁。
- 采集场景:涵盖集体活动、自由游戏、户外活动和日常环节中的自然音频。
- 说话人数量:2550名独立说话人。
- 语音片段分布:
- 教师语音:73.85%
- 学生语音:26.15%
- 说话人身份分布:
- 教师:45.09%
- 学生:54.91%
数据标注
- 标注工具:专业评估员(评分者间信度 κ > 0.80)。
- 标注量表:
- ECQRS-EC量表:包含22个项目,覆盖4个领域(读写、数学、科学、多样性)。
- SSTEW量表:包含15个项目。
- 标注粒度:在总计206个指标上进行指标级别的二元编码。
相关方法与框架
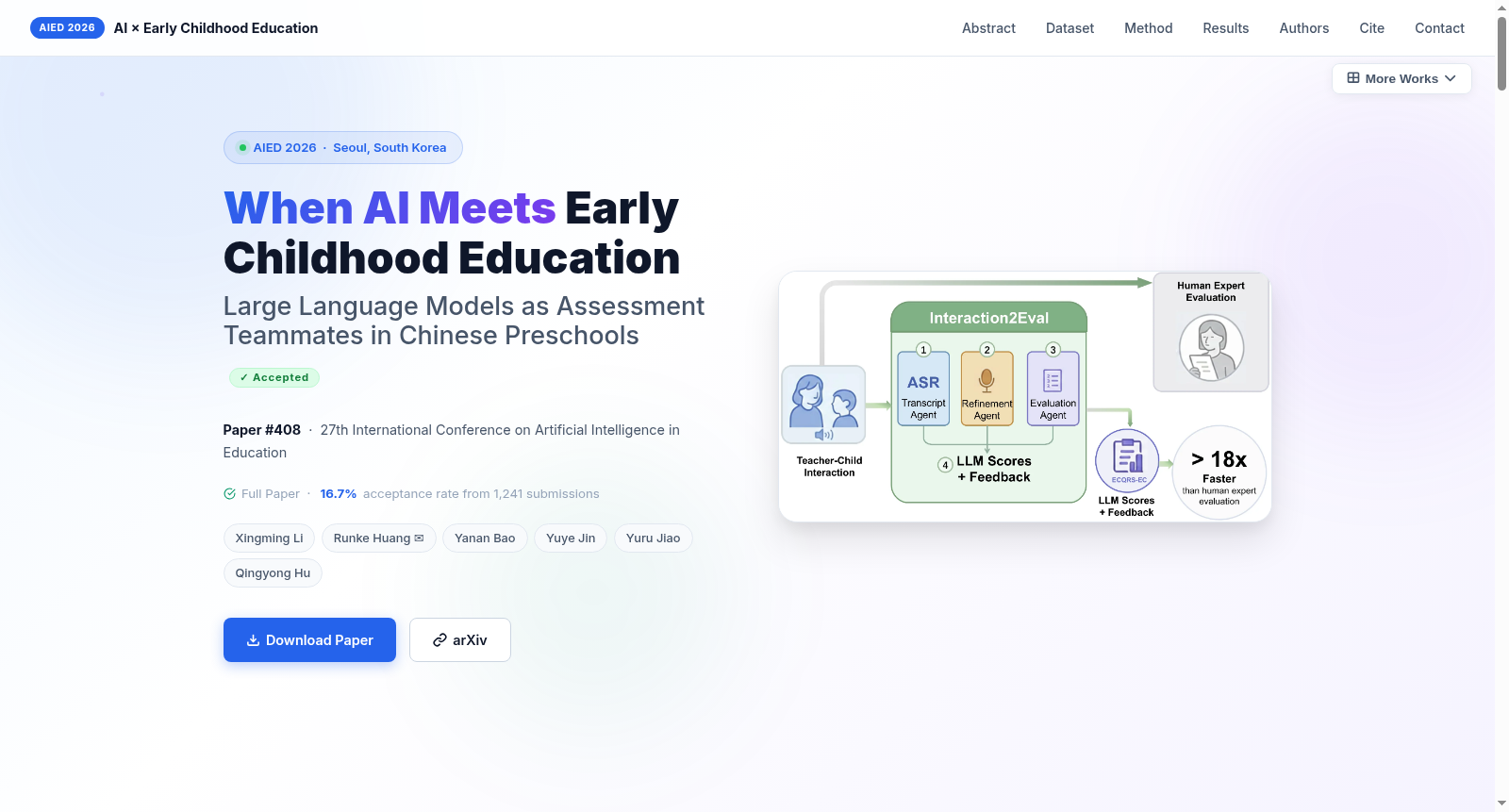
- 评估框架:Interaction2Eval
- 框架流程:一个基于大语言模型的三阶段流水线,将原始课堂音频转化为专家级别的质量评估。
- 转录智能体:使用FunASR Paraformer进行说话人日志和标点恢复,自动区分教师和学生语音。
- 精炼智能体:利用Qwen3-Max进行领域感知的错误纠正,针对普通话同音字和学前教育特定词汇。
- 评估智能体:应用基于量表的提示(SSTEW & ECQRS-EC),采用证据优先的推理:定位话语 → 判断指标存在性 → 用转录证据证明 → 生成反馈。
- 处理效率:处理一节3小时的课堂录音,人工专家需380分钟,Interaction2Eval框架仅需21分钟,效率提升18倍。
实验验证与效果
- 专家一致性:Interaction2Eval框架与人类专家评估的一致性最高达到88%。
- ASR质量提升:在包含16,168个参考字符的5小时测试集上评估。
- FunASR Paraformer:原始字符错误率(CER)为9.9%,精炼后降至4.3%,绝对降低5.6%,相对改进56.6%。
- Whisper-large v3:原始CER为35.1%,精炼后降至23.2%。
- 错误类型分析(初始ASR输出):同音字错误占51.67%,额外词语占20.80%,说话人识别错误占13.72%,标点错误占7.75%,遗漏占6.06%。
实际部署与影响
- 试点研究:在深圳3所公立幼儿园的43个教室中进行了为期4周的初步部署验证。
- 处理会话数:127次
- 成功率:96.8%
- 参与教师:77名
- 系统级影响:Interaction2Eval将每100个教室每月的专家工作量从633专家小时减少到35专家小时,使得从年度抽查审计转变为在人工定向监督下的、持续的月度AI辅助监测成为可能。
搜集汇总
数据集介绍
构建方式
在学前教育质量评估领域,TEPE-TCI-370h数据集的构建遵循了严谨的科研伦理与标准化流程。研究团队在中国41所公立幼儿园的105个班级中,使用专业录音设备采集了超过370小时的自然主义师幼互动音频,覆盖集体活动、自由游戏和户外活动等多种场景。所有录音均获得了教师与监护人的知情同意,并经由大学伦理委员会批准。数据标注由经过严格培训的评估专家完成,他们依据ECQRS-EC和SSTEW两大国际通用评估量表,对互动质量进行指标级二进制编码,并通过一致性检验确保标注可靠性,最终形成了首个兼具大规模真实课堂录音与标准化质量标注的中文学前教育交互数据集。
使用方法
该数据集主要服务于基于人工智能的教育质量评估研究与应用。研究者可利用其音频与标注数据,开发自动语音识别与自然语言处理模型,特别是针对儿童语音识别、普通话同音词消歧等领域特定挑战。数据集的结构化质量指标为训练和验证大型语言模型提供了基准,使模型能够学习将课堂对话映射到标准化评估量表的推理过程。在实际部署中,集成该数据集的系统可实现从课堂录音到质量报告的自动化流水线,将传统长达数小时的人工评估压缩至二十分钟左右,从而支持从年度审计向持续监测的范式转变,为教育管理者提供及时、可操作的质量改进洞察。
背景与挑战
背景概述
TEPE-TCI-370h数据集由国防科技大学、香港中文大学(深圳)及牛津大学的研究团队于2025年共同创建,旨在应对中国学前教育中师幼互动质量评估的规模化挑战。该数据集收录了来自105个幼儿园班级、总计370小时的自然情境师幼互动音频,并依据ECQRS-EC和SSTEW两大国际标准化评估量表进行了专家标注。作为首个面向中文学前教育场景的大规模互动质量评估数据集,其构建填补了该领域在自然课堂语音数据与结构化质量标注结合方面的空白,为利用人工智能技术实现持续、可扩展的教育质量监测奠定了关键数据基础,对推动早期教育评估从依赖人工的间断式审计向智能化、常态化模式转型具有重要影响力。
当前挑战
该数据集致力于解决师幼互动质量自动化评估这一核心领域问题,其面临的主要挑战在于如何从嘈杂、多说话者的课堂音频中准确识别并映射到复杂的教育评估量规指标。具体构建挑战包括:在数据层面,中文学前教育场景缺乏公开可用的自然课堂语音与质量标注资源;在语音处理层面,需克服儿童发音不标准、多人语音重叠、高背景噪声以及普通话同音词歧义和教育领域术语带来的识别困难;在评估层面,要求系统不仅实现语音转写,还需具备对教学行为模式进行细粒度识别、跨时段推理以及结合教育学知识进行语境化判断的能力,以达成与人类专家评估的高一致性。
常用场景
经典使用场景
在学前教育质量评估领域,TEPE-TCI-370h数据集为研究者提供了首个大规模、自然情境下的师幼互动音频资源。该数据集的核心应用场景在于训练和验证基于人工智能的自动化评估系统,特别是针对ECQRS-EC和SSTEW等标准化评估量表的指标识别。通过370小时的真实课堂录音与专家标注,研究者能够开发专门的语言模型框架,以应对儿童语音识别、普通话同音词消歧等独特挑战,从而实现从嘈杂课堂音频中提取结构化质量指标,并与人类专家评估结果进行对齐验证。
解决学术问题
该数据集有效解决了学前教育研究中师幼互动质量评估的可扩展性难题。传统依赖专家现场观察的方法成本高昂、效率低下,难以在拥有超过25万所幼儿园的中国大规模教育体系中实现持续监测。TEPE-TCI-370h通过提供带有多维度专业标注的自然课堂数据,使得基于音频的自动化评估成为可能,从而支持对语言可及性互动维度(如对话质量、提问策略)进行规模化、客观化的分析。这不仅为探索人工智能如何作为评估伙伴提供了实证基础,也推动了教育测量与计算语言学的交叉研究。
实际应用
在实际教育场景中,该数据集支撑的评估框架能够显著提升幼儿园质量监测的效率与频率。通过部署集成自动语音识别与大语言模型的系统,教师仅需佩戴便携录音设备进行日常教学,即可在短时间内获得基于标准化量表的评估反馈。试点部署表明,该系统将单次课堂评估流程从传统所需的380分钟缩短至21分钟,实现了18倍的效率提升。这使得月度甚至更频繁的质量监测成为可能,帮助教育管理者从年度抽查转向持续跟踪,并为教师提供基于具体对话证据的专业发展建议。
数据集最近研究
最新研究方向
在学前教育质量评估领域,TEPE-TCI-370h数据集的推出标志着人工智能与早期教育深度融合的前沿探索。该数据集聚焦于自然情境下的师幼互动音频,并首次结合ECQRS-EC和SSTEW等标准化评估标注,为基于大语言模型的自动化评估系统提供了关键基准。当前研究热点集中于克服领域特有挑战,如儿童语音识别、普通话同音词消歧及基于评估量表的推理,旨在实现与人类专家评估的高一致性。这一方向不仅推动了教育语音处理与自然语言处理技术的交叉创新,更通过实际部署验证了AI辅助评估在提升教育监测效率、实现从年度审计转向持续质量改进方面的巨大潜力,为全球大规模学前教育系统的科学化、精细化治理提供了新的技术范式。
相关研究论文
- 1When AI Meets Early Childhood Education: Large Language Models as Assessment Teammates in Chinese Preschools国防科技大学; 香港中文大学·深圳; 牛津大学 · 2026年
以上内容由遇见数据集搜集并总结生成


