S2L
收藏arXiv2025-08-05 更新2025-08-07 收录
下载链接:
https://hf.co/datasets/marsianin500/Speech2Latex
下载链接
链接失效反馈官方服务:
资源简介:
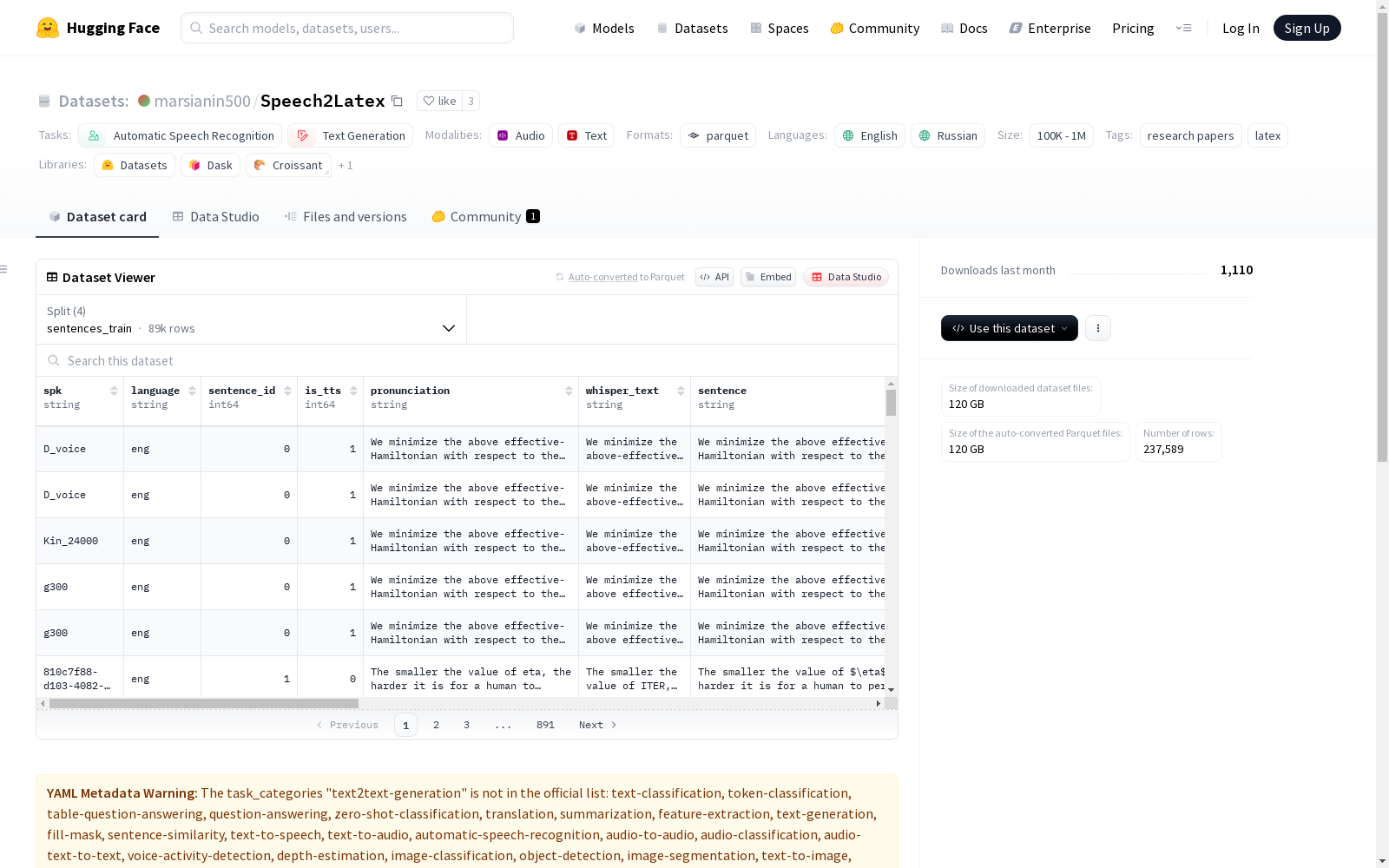
S2L数据集是一个大规模的开源数据集,包含超过66,000个人工标注的英文和俄语文本数学方程式和句子音频样本。数据集由两部分组成:S2L-sentences和S2L-equations,分别包含大约12,000个唯一的数学句子和10.7k个独立的方程。数据集收集了来自多个来源的数学方程式和句子,以及相应的参考发音,并进行了人工和人工生成的音频标注。数据集旨在解决将口头数学表达式和句子转换为LaTeX格式的问题,适用于教育和研究领域,如讲座转录或笔记创建。
The S2L dataset is a large-scale open-source dataset containing over 66,000 manually annotated English and Russian textual mathematical equation and sentence audio samples. The dataset consists of two subsets: S2L-sentences and S2L-equations, which contain approximately 12,000 unique mathematical sentences and 10.7k standalone equations respectively. The dataset collects mathematical equations and sentences from multiple sources along with their corresponding reference pronunciations, and has been annotated with both manual and machine-generated audio annotations. It aims to address the problem of converting spoken mathematical expressions and sentences into LaTeX format, and is applicable to educational and research fields such as lecture transcription or note creation.
提供机构:
俄罗斯
创建时间:
2025-08-05
搜集汇总
数据集介绍
构建方式
S2L数据集通过结合人工标注和合成数据构建,涵盖了数学表达式和句子的语音转LaTeX任务。数据来源包括MathBridge、TextTeller和Proof-Pile等公开数据集,经过严格的清洗和标准化处理。每个样本由多名标注者录制,以确保发音多样性,并辅以TTS生成的大规模合成数据增强。数据按语言(英语和俄语)和格式(孤立方程和上下文句子)分类,最终形成包含66,000个人工标注和571,000个合成样本的多模态数据集。
特点
S2L数据集以其规模化和多样性著称,覆盖了广泛的数学符号和结构,包括希腊字母、分式、根式等复杂表达式。数据集中每个方程或句子均提供多种发音变体,反映了真实场景中的语音歧义性。特别设计的S2L-sentences子集包含嵌套在自然语言中的数学表达式,极大增强了任务的实用性。数据集还通过严格的LaTeX标准化流程,减少了因语法变体导致的评估偏差。
使用方法
该数据集支持多种技术路线的研究,包括ASR后校正和端到端多模态建模。使用时可选择特定子集进行模型训练,如仅用英语方程或混合语言句子。评估时建议采用字符错误率(CER)和TeXBLEU等专用指标,并注意区分对数学表达式和自然文本的单独评估。对于跨语言研究,数据集的英俄双语特性支持迁移学习实验。所有音频数据已统一为16kHz采样率,可直接用于主流语音模型的输入。
背景与挑战
背景概述
S2L(Speech-to-LaTeX)数据集由Dmitrii Korzh等研究人员于2025年发布,旨在解决语音数学表达式转换为结构化LaTeX符号的挑战。该数据集包含超过66,000个人工标注的英语和俄语数学方程及句子音频样本,覆盖多个科学领域。其核心研究问题在于克服语音识别模型在处理复杂数学表达式时的局限性,特别是在学术和教育场景中,如讲座转录和科学笔记。S2L数据集的推出填补了该领域大规模开源数据的空白,为多模态AI在数学内容处理方面的研究奠定了基础。
当前挑战
S2L数据集面临的挑战主要包括两方面:领域问题方面,数学表达式具有严格的符号结构和多样的发音歧义(如“kappa”可能对应\kappa或\varkappa),导致语音到LaTeX转换的准确率受限;构建过程方面,需处理数据源的噪声(如MathBridge中的低质量条目),协调多语言发音差异,以及平衡人工标注与合成数据的质量。此外,嵌套表达式识别、上下文数学句子的处理,以及跨语言模型的泛化能力都是亟待解决的难题。
常用场景
经典使用场景
在数学教育和科研领域,S2L数据集为语音到LaTeX的转换提供了丰富的资源。该数据集通过收集大量数学表达式和句子的语音样本,并结合人工标注和合成音频,为语音识别和自然语言处理模型提供了训练和测试的基础。特别是在自动讲座转录和科学笔记生成等场景中,S2L数据集的应用显著提升了数学内容的结构化表示能力。
解决学术问题
S2L数据集解决了数学语音识别中的多个关键问题,包括数学表达式的结构化转录、多语言支持以及语音与符号表示的精确对齐。通过提供大规模、多样化的语音样本,该数据集填补了现有研究中缺乏高质量训练数据的空白,为语音到LaTeX转换任务建立了可靠的基准。此外,其开源特性进一步促进了学术界的协作与创新。
衍生相关工作
S2L数据集推动了多个相关领域的研究进展,衍生出多项经典工作。例如,基于该数据集的ASR后校正模型和音频语言模型在数学语音识别任务中表现出色。此外,MathSpeech和MathBridge等研究通过利用S2L数据集,进一步优化了语音到LaTeX的转换流程,为多模态AI的发展提供了重要参考。
以上内容由遇见数据集搜集并总结生成


