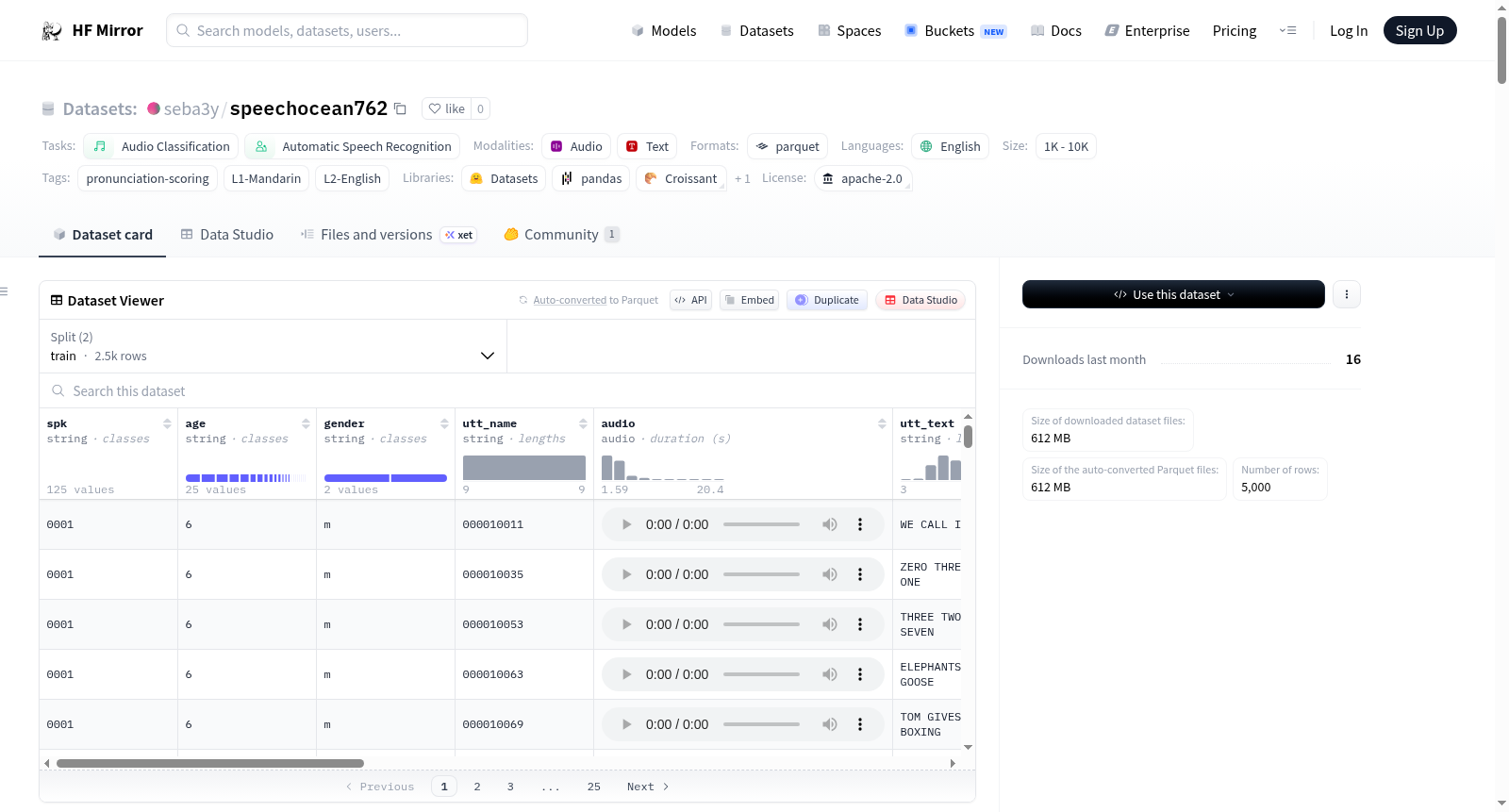
seba3y/speechocean762
收藏数据集概述
基本信息
- 语言: 英语
- 许可证: Apache 2.0
- 数据量: 1K < n < 10K
- 任务类别: 音频分类、自动语音识别
- 标签: 发音评分、L1-普通话、L2-英语
数据集结构
特征
- 人口统计特征:
spk: 说话者ID (字符串)age: 年龄 (字符串)gender: 性别 (字符串)utt_name: 话语名称 (字符串)
- 句子级特征:
audio: 音频数据 (采样率: 16000)utt_text: 话语文本 (字符串)utt_accuracy: 话语准确性 (整数)utt_completeness: 话语完整性 (浮点数)utt_fluency: 话语流利度 (整数)utt_prosodic: 话语韵律 (整数)utt_total: 话语总分 (整数)
- 单词级特征:
words: 单词序列 (字符串)words_accuracy: 单词准确性 (整数序列)words_stress: 单词重音 (整数序列)words_total: 单词总分 (整数序列)
- 音素级特征:
phones: 音素序列 (字符串序列)phones_godness: 音素准确性 (浮点数序列)
数据分割
- 训练集:
- 字节数: 333075617.5
- 样本数: 2500
- 测试集:
- 字节数: 311790040.5
- 样本数: 2500
数据大小
- 下载大小: 611757634
- 数据集大小: 644865658.0
配置
- 默认配置:
- 训练数据路径:
data/train-* - 测试数据路径:
data/test-*
- 训练数据路径:
数据集描述
该数据集旨在为发音评分任务提供一个免费公开的数据集。主要特点包括:
- 可免费下载用于商业和非商业目的。
- 说话者涵盖儿童和成人。
- 手动标注包括句子级、单词级和音素级的多个方面。
数据集包含5000个英语句子,所有说话者均为非母语者,母语为普通话。一半说话者为儿童,另一半为成人。提供了年龄和性别信息。五位专家独立评分以避免主观偏差。
评分标准
专家在三个级别上评分:音素级、单词级和句子级。
音素级
评分每个单词内音素的发音准确性。
- 评分范围: 0-2
- 2: 发音正确
- 1: 发音正确但有重音
- 0: 发音错误或缺失
单词级
评分每个单词的发音准确性和重音。
- 准确性:
- 评分范围: 0 - 10
- 10: 单词发音完美
- 7-9: 大部分音素发音正确但有口音
- 4-6: 少于30%的音素发音错误
- 2-3: 超过30%的音素发音错误或单词被误读为其他单词
- 1: 发音难以辨别
- 0: 无声音
- 重音:
- 评分范围: {5, 10}
- 10: 重音正确或单音节单词
- 5: 重音错误
句子级
评分句子级的准确性、流利度、完整性和韵律。
- 准确性:
- 评分范围: 0 - 10
- 9-10: 句子整体发音优秀,无明显发音错误
- 7-8: 句子整体发音良好,有少量发音错误
- 5-6: 句子整体发音可理解,有较多发音错误和口音
- 3-4: 句子整体发音差,发音生硬
- 0-2: 发音极差,仅能识别一两个单词
- 完整性:
- 评分范围: 0.0 - 1.0
- 发音良好的单词百分比
- 流利度:
- 评分范围: 0 - 10
- 8-10: 流利,无明显停顿或结巴
- 6-7: 总体流利,有少量停顿、重复和结巴
- 4-5: 发音有些不流利,有较多停顿、重复和结巴
- 0-3: 断断续续,非常不流利
- 韵律:
- 评分范围: 0 - 10
- 9-10: 正确语调,稳定语速,有节奏感
- 7-8: 接近正确语调,稳定语速,基本流畅
- 5-6: 语速不稳定,有较多结巴和停顿
- 3-4: 语速不稳定,说话过快或过慢
- 0-2: 语调差,结巴和停顿多
数据结构
数据集包含两个子集:train 和 test,均采用Kaldi数据目录风格。评分存储在scores.json中,示例如下:
json { "000010011": { "text": "WE CALL IT BEAR", "accuracy": 8, "completeness": 10.0, "fluency": 9, "prosodic": 9, "total": 8, "words": [ { "accuracy": 10, "stress": 10, "total": 10, "text": "WE", "phones": "W IY0", "phones-accuracy": [2.0, 2.0] }, ... ] }, ... }
scores-detail.json包含五位专家的原始评分,而scores.json中的评分是平均或中位数评分。
引用
如需引用该数据集,请使用以下格式:
bibtex @inproceedings{zhang2021speechocean762, title={speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment}, author={Zhang, Junbo and Zhang, Zhiwen and Wang, Yongqing and Yan, Zhiyong and Song, Qiong and Huang, Yukai and Li, Ke and Povey, Daniel and Wang, Yujun}, booktitle={Proc. Interspeech 2021}, year={2021} }