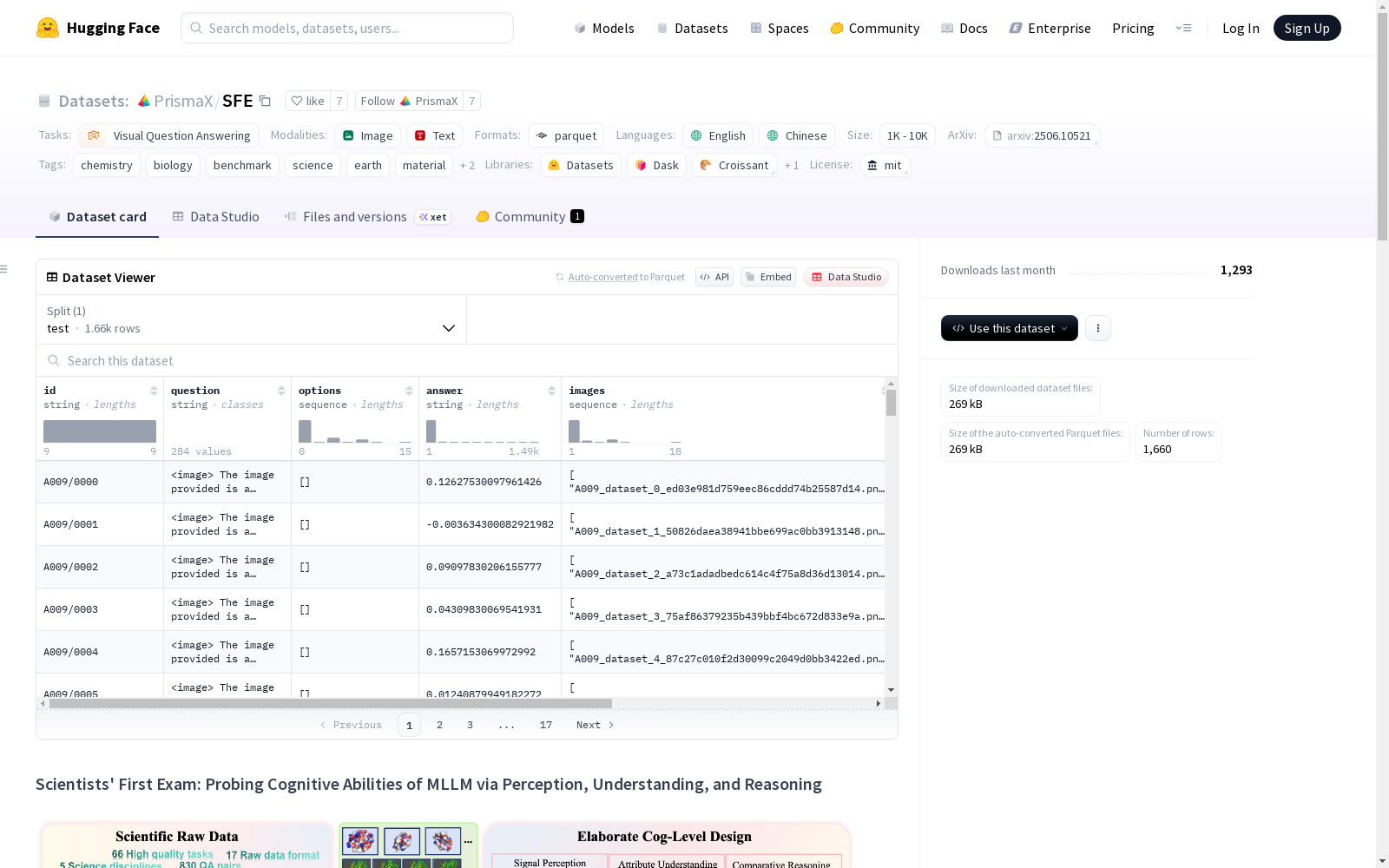
SFE
收藏SFE数据集概述
基本信息
- 许可证: MIT
- 任务类别: 视觉问答 (Visual Question Answering)
- 支持语言: 英语 (en)、中文 (zh)
- 标签: 化学、生物学、基准测试、科学、地球、材料、生命、天文学
- 数据集名称: SFE (Scientists First Exam)
- 数据规模: <1K
数据集简介
SFE (Scientists First Exam) 是一个用于评估多模态大语言模型 (MLLMs) 科学认知能力的基准测试,通过三个认知层次进行测评:
- 科学信号感知: 识别科学原始数据可视化中的关键组成部分。
- 科学属性理解: 解释领域专家知识的能力。
- 科学比较推理: 通过结构化比较多个科学视觉源得出现象学见解的能力。
数据集内容
- 学科范围: 天文学、化学、地球科学、生命科学、材料科学
- 任务数量: 66个专家策划的高价值多模态任务
- 问题类型: 830个专家验证的视觉问答 (VQA) 对
- 语言支持: 双语 (英语和中文)
数据集下载
bash git lfs install git clone https://huggingface.co/datasets/PrismaX/SFE # 克隆所有文件,包括原始数据 GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/PrismaX/SFE # 仅克隆文件指针,不包括大文件
评估方法
使用 lmms-eval 进行评估。
参考文献
bibtex @misc{zhou2025scientistsexamprobingcognitive, title={Scientists First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning}, author={Yuhao Zhou and Yiheng Wang and Xuming He and Ruoyao Xiao and Zhiwei Li and Qiantai Feng and Zijie Guo and Yuejin Yang and Hao Wu and Wenxuan Huang and Jiaqi Wei and Dan Si and Xiuqi Yao and Jia Bu and Haiwen Huang and Tianfan Fu and Shixiang Tang and Ben Fei and Dongzhan Zhou and Fenghua Ling and Yan Lu and Siqi Sun and Chenhui Li and Guanjie Zheng and Jiancheng Lv and Wenlong Zhang and Lei Bai}, year={2025}, eprint={2506.10521}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2506.10521}, }