AAdonis/multilingual_audio_alignments
收藏Hugging Face2026-05-01 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/AAdonis/multilingual_audio_alignments
下载链接
链接失效反馈官方服务:
资源简介:
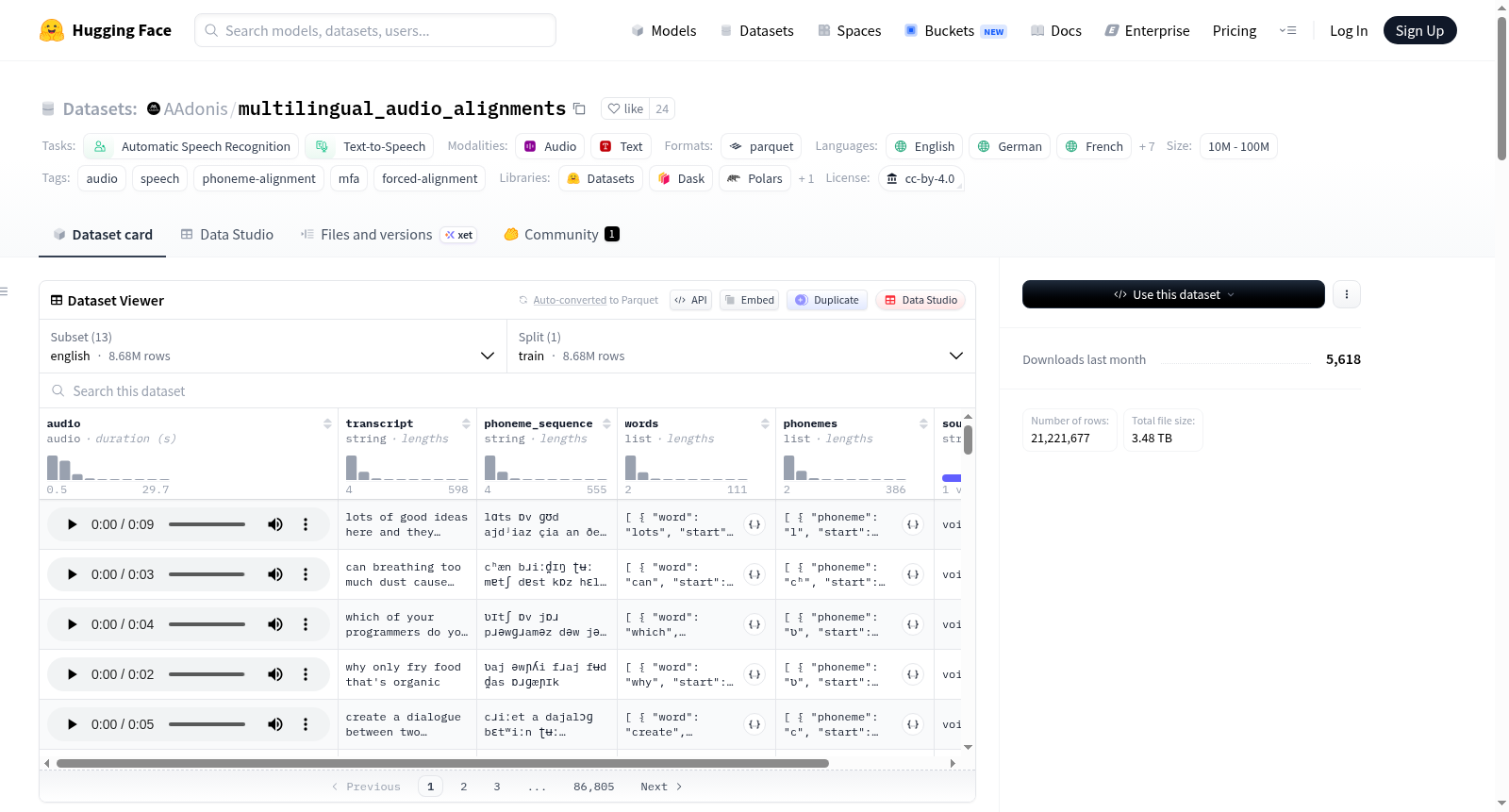
这是一个大规模的多语言语音数据集,使用蒙特利尔强制对齐器(MFA)提供了精确的单词级别和音素级别的对齐信息。数据集整合了多种语言的语音语料库,每个样本包括原始音频、转录文本以及单词和音素的详细时间信息。数据集支持多种语言,包括英语、德语、法语、西班牙语、俄语、日语、韩语、葡萄牙语、土耳其语和泰语等。总时长估计超过20,000小时。数据集的主要特征包括音频波形、文本转录、音素序列、单词和音素的对齐信息以及数据来源。
A large-scale multilingual speech dataset with word-level and phoneme-level alignments produced using the Montreal Forced Aligner (MFA). This dataset consolidates multiple speech corpora across various languages, all processed through MFA to provide precise phoneme and word alignments. Each sample includes the original audio, transcript, and detailed timing information for both words and phonemes. The dataset supports multiple languages including English, German, French, Spanish, Russian, Japanese, Korean, Portuguese, Turkish, and Thai, with an estimated total duration of over 20,000 hours. Key features include audio waveforms, text transcripts, phoneme sequences, word and phoneme alignments, and data sources.
提供机构:
AAdonis
搜集汇总
数据集介绍
构建方式
本数据集以多语种语音处理需求为背景,融合了来自Common Voice、VoxPopuli、Multilingual LibriSpeech等多个公开语音语料库的音频资源。所有样本均经由蒙特利尔强制对齐工具(MFA)进行精细处理,利用语言特定的声学模型与发音词典,在词级与音素级层面生成精准的时间对齐信息。构建过程中,针对包含未知词或噪声标记的样本在边界处进行合理切分,同时依据时长和单词数量等阈值进行质量过滤,最终形成一套大规模、高质量的多语种对齐语音数据集。
特点
该数据集涵盖了英语、德语、法语、西班牙语、俄语、日语、韩语、葡萄牙语、土耳其语、泰语等十余种语言,预估总时长超过20,000小时。每条样本除16kHz的原始音频波形与文本转录外,还额外提供了音素序列以及结构化词级与音素级对齐列表,详细记录了每个语音单元的开始与结束时间。数据来源的多样性为多语言场景下的泛化能力提供了保障,而统一的MFA处理标准则确保了跨语言对齐信息的一致性与可靠性。
使用方法
用户可通过HuggingFace Datasets库便捷加载指定语言的子集,例如使用`load_dataset('AAdonis/multilingual_audio_alignments', 'english', split='train')`即可获取英语部分。访问样本后,可分别提取音频数组、文本转录、音素序列以及词级或音素级的对齐信息,便于下游模型训练或分析。此外,用户还能通过`filter`方法依据`source`字段筛选来自特定原始语料库的样本,从而灵活适配自动语音识别、文本转语音或语音编辑等不同研究任务的需求。
背景与挑战
背景概述
在语音识别与文本转语音领域,音素级与词级的精确对齐是提升模型性能的关键瓶颈。现有开源数据集多局限于单语言或缺乏细粒度时间标注,难以支撑跨语言语音编辑与多模态生成研究。2026年,由Antonis Asonitis、Luca A. Lanzendörfer等研究者构建的Multilingual MFA-Aligned Speech Dataset(简称MMFA)应运而生,其核心创新在于利用蒙特利尔强制对齐工具(MFA)对超过20,000小时的语音数据进行了统一的音素与词汇级别对齐处理。该数据集整合了Common Voice、VoxPopuli、Multilingual LibriSpeech等十余个公开语料库,覆盖英语、德语、法语、日语等13种语言,为多语言语音编辑、跨语种合成及细粒度语音分析提供了标准化基准,显著推动了多语言语音处理领域的进步。
当前挑战
该数据集所解决的领域核心挑战在于,多语言场景下缺乏兼具大规模、高质量且统一标注的语音对齐资源,以往单一语种或粗粒度时间戳的数据难以支撑端到端模型对音素边界与词边界的精确学习。在构建过程中,研究者面临多重技术挑战:首先,不同语料库的采样率、编码格式与背景噪声差异极大,需统一重采样至16kHz并进行一致性清洗;其次,MFA强制对齐依赖语种专属的声学模型与发音词典,非官方支持的语言(如泰语)需定制化训练,对齐精度因语种而异;此外,数据内包含未知词(<unk>)与口语噪声标记(spn),需通过启发式规则在不可靠边界处拆分样本,同时平衡时长与词数过滤阈值,避免过度裁剪导致语义断裂。
常用场景
经典使用场景
在语音与语言处理领域,精确的音素级与词级时间对齐信息是构建高质量语音识别与合成系统的基础。该数据集通过蒙特利尔强制对齐工具对二十余种语言的语音语料库进行细致处理,为每一段音频提供了从波形到音素序列的完整时间戳映射。经典使用场景包括训练端到端的自动语音识别模型,其中对齐信息可辅助注意力机制更精准地学习音频与文本的对应关系,尤其在低资源语言场景下,这些预对齐数据能够显著提升模型的收敛速度与识别精度。同时,在多说话人文本转语音任务中,对齐结果可用于提取韵律特征与发音时长分布,进而合成更自然流畅的语音。
实际应用
在实际应用层面,该数据集赋能了多项面向大众的语音技术产品。在智能教育领域,精确的音素对齐可用于发音评测系统,逐字逐音地诊断外语学习者的发音偏差并提供针对性反馈。在内容创作方面,语音编辑工具可借助对齐信息实现自然的语音拼接与替换,例如在播客或视频制作中精准修正读音错误而不影响语流连贯性。此外,面向视障人群的无障碍阅读软件,利用对齐结果可实现对有声文字的音节级强调与导航,提升交互体验与信息获取效率。
衍生相关工作
基于该数据集,已有多项具有影响力的研究工作相继展开。其原始论文《多语言语音编辑》系统性地展示了如何利用对齐信息实现跨语言的语音内容替换与风格迁移,为语音编辑领域设立了新的基准。后续工作包括结合预训练语音模型(如Wav2Vec 2.0)进行对齐微调,从而在噪声环境下保持高精度时间定位。此外,有研究者利用该数据集训练了统一的音素识别器,在不依赖语言特定模型的情况下实现了多语言音素解码,显著简化了多语言语音系统的构建流程,并催生了面向高资源语言的发音自动标注工具链。
以上内容由遇见数据集搜集并总结生成


