Deep Evaluation of Audio Representations (DEAR)
收藏arXiv2025-02-11 更新2025-02-12 收录
下载链接:
https://dear-dataset.github.io
下载链接
链接失效反馈官方服务:
资源简介:
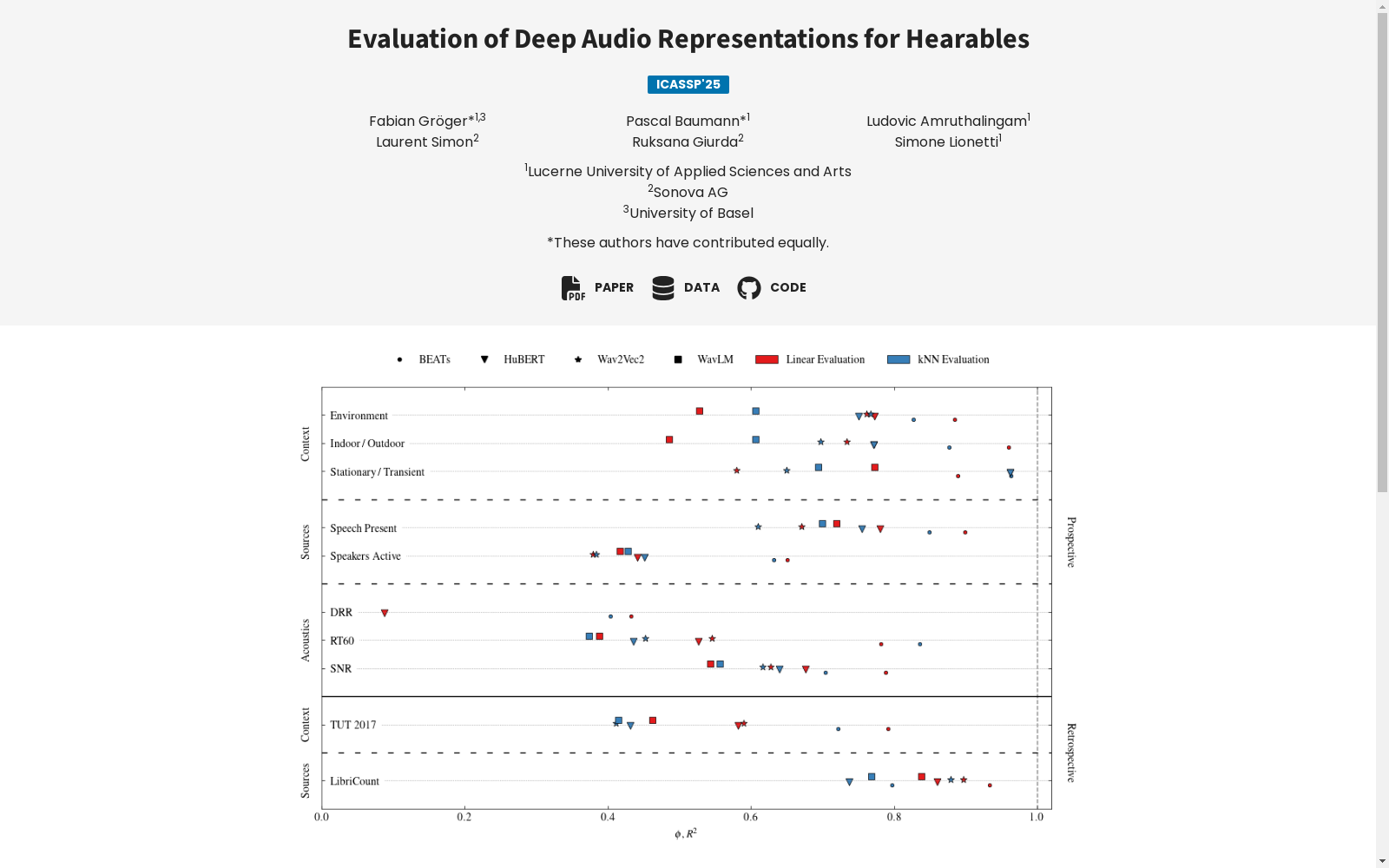
DEAR数据集由卢塞恩应用科学大学等机构发布,包含1158个各为30秒的音频轨道,通过将专有独白与商业高质量日常声学场景录音混合制作而成。该数据集旨在评估音频表示基础模型在捕捉助听器所需的关键声学属性方面的性能,包含八个评估任务,涵盖了一般背景、语音来源和技术声学特性。数据集应用于助听器和助听设备领域,旨在解决声学场景分析中的挑战。
The DEAR Dataset was released by Lucerne University of Applied Sciences and Arts and other institutions. It comprises 1,158 30-second audio tracks generated by mixing proprietary monologues with commercial high-quality recordings of daily acoustic scenes. This dataset is designed to evaluate the performance of audio representation foundation models in capturing the critical acoustic properties required for hearing aids, and it includes eight evaluation tasks covering general acoustic backgrounds, speech sources, and technical acoustic characteristics. The dataset is applied in the field of hearing aids and assistive listening devices, aiming to address the challenges in acoustic scene analysis.
提供机构:
卢塞恩应用科学大学
创建时间:
2025-02-11
搜集汇总
数据集介绍
构建方式
DEAR数据集的构建方式是通过将专有的单声道独白与日常声学场景的高质量商业录音进行空间混合,从而创造出能够模拟真实环境中声音场景的音频片段。每个音频片段长度为30秒,总共包含了1,158个音频轨道。这些音频轨道被设计为具有不同的声学特性,如混响时间和信号噪声比,以便能够评估基础模型在捕捉这些声学特性方面的能力。数据集的构建过程还确保了音频片段的多样性和复杂性,以反映现实世界中的声学环境。
使用方法
DEAR数据集的使用方法是通过在模型上进行预训练,然后使用这些预训练的模型来执行一系列评估任务。评估任务包括对音频场景上下文的分类、对声源的存在和数量的检测以及对声学特性的技术属性的回归。这些任务旨在测试模型对声学场景的理解能力。此外,DEAR数据集还可以用于开发新的音频处理算法,这些算法可以用于可听设备的信号处理,以提高用户的听觉体验。
背景与挑战
背景概述
随着人工智能在音频分析领域的不断深入,对于可穿戴设备(hearables)的研究也日益重要。这些设备需要能够理解用户周围的声音环境,从而提供如主动降噪和语音增强等功能。为了评估深度音频表示模型在捕捉可穿戴设备所需的基本声学特性方面的有效性,Gr¨oger等人创建了Deep Evaluation of Audio Representations (DEAR)数据集。DEAR数据集包括1,158个音频轨道,每个轨道30秒长,通过将专有的独白与日常声学场景的高质量商业录音进行空间混合而创建。该数据集的主要研究人员来自卢塞恩应用科学艺术大学和索诺瓦AG公司,他们致力于推动音频分析领域的创新。DEAR数据集的创建填补了现有音频分析模型在可穿戴设备应用中的空白,对相关领域的研究和开发具有重要意义。
当前挑战
DEAR数据集的创建和评估面临诸多挑战。首先,数据集需要能够模拟复杂的声学环境,同时保持录音的真实性和多样性。其次,数据集的设计需要考虑可穿戴设备的实际应用场景,例如噪声环境下的语音识别和声源定位。此外,对于音频表示模型的评估,需要建立一套全面和准确的评估指标,以衡量模型在捕捉声学特性方面的能力。DEAR数据集通过引入八个评估任务,包括环境上下文、语音源和技术声学特性,为这些挑战提供了有效的解决方案。然而,对于如何设计通用的音频模型以适应可穿戴设备的需求,以及如何进一步提高模型在声学特性评估中的性能,仍然是该领域需要进一步探索的问题。
常用场景
经典使用场景
在智能听力设备(hearables)领域,Deep Evaluation of Audio Representations (DEAR) 数据集被广泛应用于评估深度学习模型在捕捉和编码声音场景中的关键声学属性的能力。该数据集通过模拟真实世界的声音环境,为研究人员提供了评估模型性能的标准,帮助开发出更精确的声学处理算法,从而改善听力设备的用户体验。
解决学术问题
DEAR 数据集解决了在智能听力设备中,如何准确评估深度学习模型对声学环境属性编码能力的学术研究问题。通过提供包含各种声学属性的音频数据,DEAR 数据集使得研究人员能够全面评估模型在处理不同声学环境时的表现,从而推动了听力设备声学处理技术的发展。
实际应用
DEAR 数据集在实际应用中,被用于智能听力设备(hearables)的开发和优化。通过对模型在 DEAR 数据集上的性能评估,开发者可以了解模型的声学处理能力,从而为听力设备的设计和优化提供依据。此外,DEAR 数据集还可以用于评估和改进语音识别、声源定位等声音分析任务,进一步提升听力设备的智能化水平。
数据集最近研究
最新研究方向
随着人工智能在听力设备和可穿戴设备领域的深入应用,音频表示模型的研究已成为一个前沿课题。DEAR数据集的推出,旨在评估深度学习模型在捕捉可穿戴设备所需音频特征方面的有效性。该数据集包含了1,158个音频片段,每个片段长30秒,通过将独白与日常声景的高质量录音混合而成。DEAR基准测试包括八项任务,用于评估音频场景的一般背景、语音来源和技术音频属性。通过对比四种通用音频表示模型,研究发现BEATs模型在捕捉技术音频属性方面显著优于其他模型。这一发现强调了在多样音频数据集上训练模型的优越性,并为其在广泛听觉任务中的应用提供了有力证据。DEAR数据集的发布,为可穿戴设备领域的研究人员提供了一个宝贵的工具,有助于推动该领域的技术进步。
相关研究论文
- 1Evaluation of Deep Audio Representations for Hearables卢塞恩应用科学大学 · 2025年
以上内容由遇见数据集搜集并总结生成


