doc_split
收藏Hugging Face2026-02-05 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/amazon/doc_split
下载链接
链接失效反馈官方服务:
资源简介:
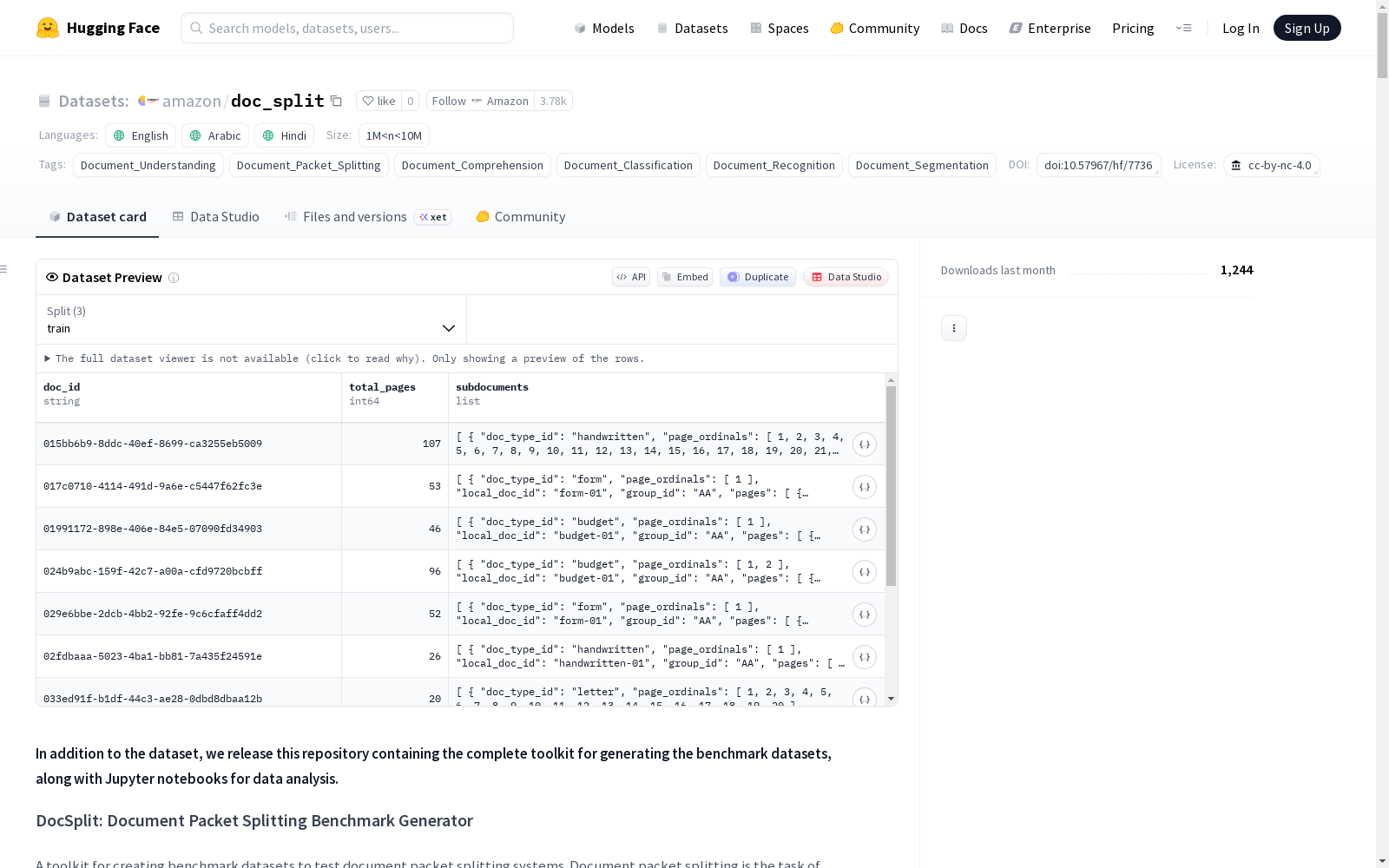
DocSplit Benchmark 是一个专注于文档处理领域的综合基准数据集,主要用于文档包识别与分割任务的研究与评估。该数据集由亚马逊于2026年2月发布,包含100万至1000万量级的样本数据,支持英语、阿拉伯语和印地语三种语言。数据集适用于文档理解、文档包分割、文档分类、文档识别和文档分割等多种文档处理任务。根据标签信息显示,该数据集特别适合开发和研究文档包自动识别与分割技术。数据集采用cc-by-nc-4.0知识共享许可协议。
提供机构:
Amazon Web Services
创建时间:
2026-02-05
搜集汇总
数据集介绍
构建方式
在文档智能领域,DocSplit数据集的构建体现了系统化的工程思维。该数据集以RVL-CDIP-N-MP多页文档集合为原始素材,通过两阶段流水线生成基准测试集。第一阶段将原始PDF文档转化为结构化资产,运用AWS Textract与DeepSeek OCR混合技术提取每页图像与文本内容;第二阶段采用五种精心设计的拼接策略,从单一类别顺序拼接至多类别页面随机化,模拟现实场景中不同复杂度的文档包拆分挑战。整个过程通过可复现的代码工具链实现,确保了数据生成的科学性与一致性。
特点
该数据集的核心特征在于其层次化的难度设计与多维度的评估体系。五个基准测试集构成渐进式复杂度谱系,从保持页面顺序的单类别拼接,到完全随机化的多类别混合,系统覆盖了边界检测、页面排序重建与文档类型分类三大核心任务。数据集同时提供小型与大型两种规模配置,分别对应5-20页与20-500页的文档包,满足不同计算环境下的评估需求。其结构化输出格式不仅包含拼接文档的完整元数据,还提供了详尽的统计指标,为模型性能的细粒度分析奠定了坚实基础。
使用方法
研究人员可通过多种技术路径获取并使用该数据集。最推荐的方式是通过Git LFS克隆完整仓库,或利用Hugging Face CLI工具进行下载。使用前需安装指定依赖并配置相应环境,特别是处理多语言文档时需要GPU资源支持DeepSeek OCR引擎。数据集的使用遵循清晰的流程:首先运行资产创建脚本将PDF转化为图像与文本资产,随后选择特定拼接策略生成基准测试集。配套的Jupyter笔记本提供了从数据处理到结果分析的全流程示例,使得用户能够快速开展文档包拆分算法的评估与比较工作。
背景与挑战
背景概述
在文档智能领域,高效处理拼接的多页文档包是提升自动化工作流的关键。DocSplit数据集由亚马逊的研究团队于2026年创建,旨在为文档包分割任务提供一个系统化的基准测试工具。该数据集基于RVL-CDIP-N-MP文档集合构建,核心研究聚焦于如何准确检测文档边界、分类文档类型并重建正确的页面顺序。通过生成五种不同复杂度的基准数据集,DocSplit推动了文档理解模型在真实场景下的评估与优化,对金融、医疗和法律等行业的文档处理自动化产生了显著影响。
当前挑战
DocSplit数据集旨在解决文档包分割这一核心领域问题,其挑战在于模型需在页面序列中精准识别文档边界,尤其是在页面随机排列或跨类别交错时维持高准确率。构建过程中的挑战则体现在多模态数据处理上,例如从原始PDF中提取高分辨率图像并执行光学字符识别,其中涉及多语言文本的准确解析,以及在不同OCR引擎(如AWS Textract与DeepSeek)间的协同集成,以确保生成资产的完整性与一致性。
常用场景
经典使用场景
在文档智能处理领域,DocSplit数据集为文档包分割任务提供了系统化的评估基准。该数据集通过五种复杂度递增的拼接策略,模拟了现实世界中多页文档被错误合并的场景,例如医疗理赔处理中各类票据与报告的混杂,或法律合同管理中同类型文件的批量扫描。研究者利用这些精心构建的基准,能够全面测试模型在文档边界检测、页面顺序重建及文档类型分类等核心任务上的性能,从而推动文档理解技术向更精细的层次发展。
解决学术问题
该数据集有效解决了文档智能研究中的若干关键挑战。传统文档处理模型往往假设输入为独立、有序的文档,而现实中大量文档以无序、混合的“文档包”形式存在。DocSplit通过定义清晰的评估任务与分层基准,为学术界提供了衡量模型鲁棒性与泛化能力的统一标准。它促使研究焦点从单一文档理解转向复杂文档流的解析,推动了文档边界检测、跨页语义连贯性分析以及异构文档分类等子领域的方法创新,为构建更接近实际应用场景的文档处理系统奠定了理论基础。
衍生相关工作
围绕DocSplit基准,已衍生出多个方向的研究工作。在模型架构方面,催生了结合视觉与文本模态、专门用于文档包分割的端到端神经网络。在方法学上,研究者提出了基于图神经网络建模页面间关系、或利用自监督学习从大量未标注文档包中预训练的新范式。此外,该基准也被用于系统评估和对比不同文档理解大模型(如LayoutLMv3、DocLLM)在复杂分割任务上的迁移能力与局限性,推动了通用文档模型在特定下游任务上的适配与优化研究。
以上内容由遇见数据集搜集并总结生成


