swimmiing/VGGSynth2
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/swimmiing/VGGSynth2
下载链接
链接失效反馈官方服务:
资源简介:
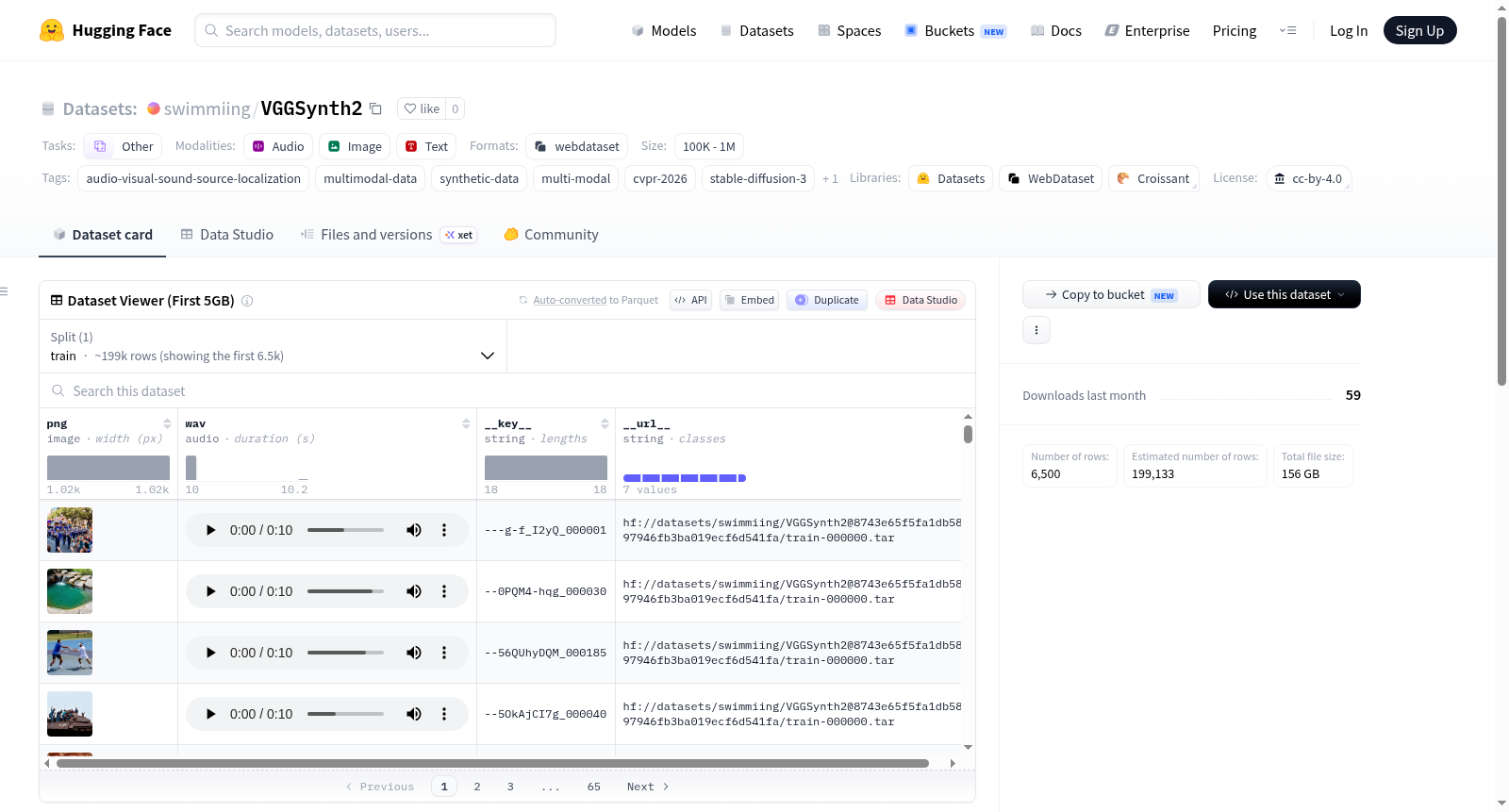
VGGSynth1是一个高保真的合成音频-视觉数据集,是VGGSynth2的一部分,使用最先进的生成模型构建。该数据集旨在探索合成数据在音频-视觉声源定位(SSL)模型训练中的边界和效用。视觉部分通过Stable Diffusion 3 (SD3)生成,音频部分通过Stable Audio生成。数据集是VGGSound数据集的合成克隆。
VGGSynth1 is a high-fidelity synthetic clone of the VGGSound dataset, built using state-of-the-art generative models. This dataset is designed to explore the boundaries and utility of synthetic data in training models for Audio-Visual Sound Source Localization (SSL). Visuals are generated via Stable Diffusion 3 (SD3), and audio is generated via Stable Audio.
提供机构:
swimmiing
搜集汇总
数据集介绍
构建方式
VGGSynth2是VGGSound数据集的高保真合成克隆版本,其构建过程完全依赖前沿生成模型。研究者采用了Stable Diffusion 3(SD3)模型生成视觉图像,同时利用Stable Audio模型生成对应的音频信号,确保了音视频数据在物理和语义层面上的高度一致性。所有样本均通过精心设计的提示词实现音视频内容的对齐生成,从而实现了对真实世界视听场景的逼真模拟。
使用方法
研究者可将VGGSynth2直接作为音频-视觉声音源定位模型的训练集,替代或扩充真实数据。使用时需注意音视频对已预先生成完毕,无需额外对齐步骤。数据加载可遵循标准的多模态数据流水线,分别处理视觉分支(如ResNet、ViT)和音频分支(如VGGish、CLAP)。推荐在模型训练中将合成数据作为预训练阶段的基础,再通过少量真实数据进行微调,以评估合成数据的泛化能力与领域迁移效果。
背景与挑战
背景概述
VGGSynth2数据集诞生于2026年,由阿达·塞诺卡克(Arda Senocak)、朴素英(Sooyoung Park)、吴泰铉(Tae-Hyun Oh)和郑俊善(Joon Son Chung)等研究者联合构建,作为CVPR 2026会议中的亮点工作。该数据集旨在探索合成数据在音视频声源定位(Audio-Visual Sound Source Localization, SSL)任务中的潜力。作为VGGSound数据集的合成克隆版,VGGSynth2利用Stable Diffusion 3生成高保真视觉内容,并通过Stable Audio合成音频,突破了传统真实数据采集的局限。其研究核心在于系统性地检验全合成流水线能否替代真实数据,推动多模态感知领域中数据驱动的模型训练范式革新,对无监督及少样本SSL任务具有重要示范意义。
当前挑战
VGGSynth2所解决的领域挑战包括:传统音视频声源定位依赖大量标注的真实场景数据,而真实数据采集成本高昂、场景多样性受限,且难以避免噪声与标注偏差。模型在跨环境或类别的泛化能力因此受到严重制约。构建过程中的挑战则集中于生成质量与模态对齐的平衡。尽管Stable Diffusion 3和Stable Audio能分别产出视觉与音频内容,但确保生成视频帧与同步音频之间拥有精确的时空语义一致性(如乐器发声位置与声波频谱的匹配)仍是技术难题。此外,合成数据中潜在的分布偏移和伪影可能误导模型学习非因果关联,从而影响SSL模型的鲁棒性与可信度。
常用场景
经典使用场景
在视听多模态感知研究领域,VGGSynth2数据集作为VGGSound的高保真合成克隆版本,其经典使用场景集中于音频-视觉声音源定位(SSL)任务的模型训练与评估。通过利用Stable Diffusion 3生成高质感视觉图像,结合Stable Audio合成逼真音频信号,该数据集为研究者提供了一个完全可控、标注精准的实验平台,尤其适用于探索合成数据在跨模态对齐与时空关联学习中的潜力。
解决学术问题
该数据集系统性地回应了真实数据采集成本高昂、隐私限制及场景多样性不足等长期困扰视听智能领域的核心困境。VGGSynth2通过生成式手段模拟了复杂声源环境下的音视频配对关系,使得在无监督或弱监督条件下研究声音源定位成为可能。其意义在于推动了合成数据与真实场景之间的泛化性验证,并为建立大规模、多标签的视听联合表征基准提供了全新路径,进而促进了多模态学习理论的纵深发展。
实际应用
在实际应用层面,VGGSynth2所支撑的合成数据训练范式可迁移至智能监控、无人驾驶环境感知及虚拟现实交互等广泛场景。例如,利用该数据集训练的模型能够在合成数据上习得稳健的声源定位能力,并有效迁移至真实世界中的视频会议噪声源辨识或无人机听觉导航任务。依赖其高保真特性,开发者可快速迭代验证多模态算法的鲁棒性,降低对稀缺真实标注数据的依赖,加速产品落地周期。
数据集最近研究
最新研究方向
基于VGGSynth2等高质量合成数据集,当前音频-视觉声源定位领域的前沿研究方向聚焦于探索生成式模型构建的虚拟数据能否替代真实数据训练鲁棒的定位模型。伴随Stable Diffusion 3与Stable Audio等生成技术的突破,研究者得以生成音画高度同步的合成样本,从而规避真实数据采集的高昂成本与隐私风险。该数据集于CVPR 2026作为亮点工作发表,标志着学术界对合成数据效用与泛化能力的系统性验证,推动了多模态学习从低成本仿真向真实场景迁移的范式跃迁,为自动驾驶、智能监控等任务中稀疏样本环境下的模型训练开辟了新路径。
以上内容由遇见数据集搜集并总结生成


