wildchat-filtered-prompts
收藏Hugging Face2025-12-25 更新2025-12-26 收录
下载链接:
https://huggingface.co/datasets/xlr8harder/wildchat-filtered-prompts
下载链接
链接失效反馈官方服务:
资源简介:
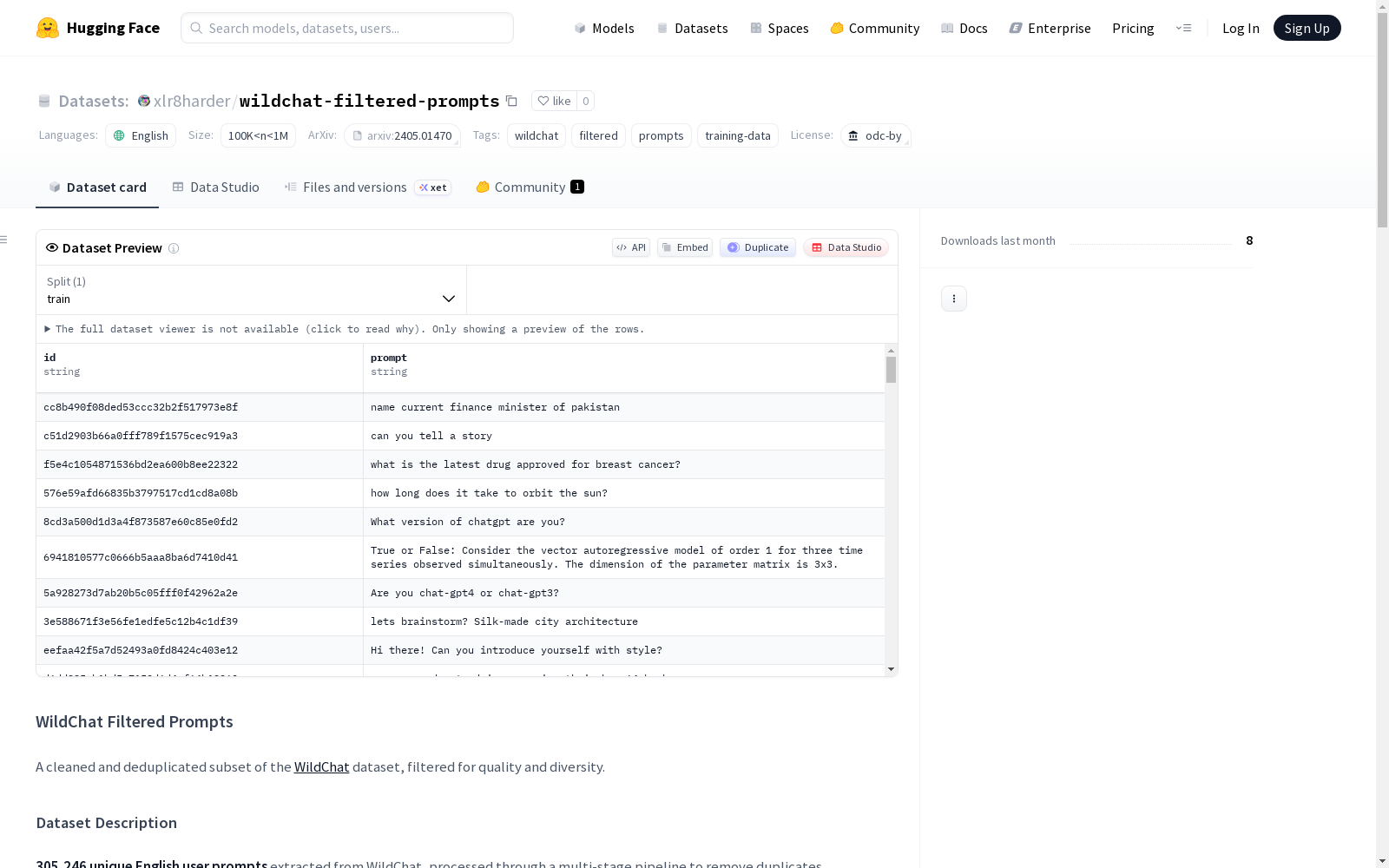
WildChat Filtered Prompts是一个经过清理和去重的WildChat数据集子集,旨在提高质量和多样性。它包含305,246个独特的英文用户提示,通过多阶段处理流程去除重复、垃圾信息、非英语内容和模板垃圾。数据集来源于WildChat,原始大小为3,185,010个对话轮次,经过处理后减少了90%。处理流程包括提取用户的首条消息、基本过滤、模糊去重、N-gram垃圾检测、聚类垃圾检测、非英语过滤和模板去重等步骤。数据集格式为JSONL,每行包含一个提示。
创建时间:
2025-12-18
原始信息汇总
WildChat Filtered Prompts 数据集概述
数据集基本信息
- 数据集名称: WildChat Filtered Prompts
- 许可证: ODC-BY
- 主要语言: 英语 (en)
- 标签: wildchat, filtered, prompts, training-data
- 数据规模: 100K < n < 1M
- 格式: JSONL (每行一个提示)
数据集描述
这是一个经过清洗和去重的 WildChat 数据集子集,经过质量和多样性筛选。包含 305,246 个唯一的英语用户提示,这些提示通过多阶段处理流程提取,以移除重复项、垃圾信息、非英语内容和模板垃圾信息。
数据来源与规模
- 原始数据集: allenai/WildChat (GPT-4/ChatGPT 用户对话)
- 原始规模: 3,185,010 次对话轮次
- 最终规模: 305,246 个提示 (减少 90%)
数据处理流程
数据处理共分为7个阶段,具体如下:
| 阶段 | 输出数量 | 处理方法 |
|---|---|---|
| 0. 原始 WildChat | 3,185,010 | Parquet 文件 |
| 1. 提取 | 2,379,985 | 仅提取第一条用户消息,SHA256 精确去重 |
| 2. 长度与语言过滤 | 961,882 | 保留 20-5000 字符,仅限英语 (使用 langdetect) |
| 3. 模糊去重 | 455,615 | MinHash LSH,Jaccard 相似度阈值 0.7 |
| 4. N-gram 垃圾信息过滤 | 350,970 | 三元组文档频率 >0.5% 视为模板垃圾信息 |
| 5. 聚类垃圾信息过滤 | 328,875 | TF-IDF + KMeans,移除紧密的近相同聚类 |
| 6. 非英语过滤 (2024年12月) | 313,226 | 移除包含 10 个以上非拉丁 Unicode 字符的提示 |
| 7. 模板去重 (2024年12月) | 305,246 | 基于前缀的模板检测,每个模板最多保留 2 个示例 |
关键处理步骤说明
- 阶段1: 仅从每次对话中提取第一条用户消息,以捕获用户原始意图,并通过 SHA256 哈希进行精确去重。
- 阶段2: 移除过短 (<20 字符) 和过长 (>5000 字符) 的提示,并使用 langdetect 库筛选英语内容。
- 阶段3: 使用 MinHash LSH 查找近似重复的提示,Jaccard 相似度阈值为 0.7。
- 阶段4: 构建三元组文档频率索引,出现频率超过 0.5% 的三元组被视为模板/垃圾信息模式。
- 阶段5: 使用 TF-IDF 向量化和 KMeans 聚类识别“紧密”聚类,这些聚类表明存在协同垃圾信息或机器人活动。
- 阶段6: 移除包含 10 个以上来自非拉丁 Unicode 范围(如西里尔文、中文、阿拉伯文等)字符的提示,以捕获 langdetect 可能漏掉的混合语言提示。
- 阶段7: 通过查找出现 10 次以上、具有相同 50 字符前缀的提示来识别模板模式。每个模板最多保留 2 个示例以保持多样性。被移除的典型模板包括特定对话生成、SEO 描述生成等。
数据格式
JSONL 格式,每行包含一个提示: json {"id": "sha256hash", "prompt": "user prompt text"}
衍生数据集
- xlr8harder/wildchat-filtered-rated-prompts:本数据集增加了开放性评分 (1-5 级)。
预期用途
- 语言模型的训练数据
- 用户提示与交互研究
- 提示多样性与模式研究
局限性
- 仅限英语(非英语提示已被过滤)
- 仅包含第一轮对话(未保留多轮上下文)
- 垃圾信息检测可能存在误报(合法提示可能被移除)
- 可能存在漏报(启发式方法未捕获的垃圾信息模式)
许可与引用
- 许可证: 本数据集继承自原始 WildChat 数据集的 ODC-BY 许可证。
- 引用: 如果使用本数据集,请引用原始 WildChat 论文: bibtex @article{zhao2024wildchat, title={WildChat: 1M ChatGPT Interaction Logs in the Wild}, author={Zhao, Wenting and Ren, Xiang and Hessel, Jack and Cardie, Claire and Choi, Yejin and Deng, Yuntian}, journal={arXiv preprint arXiv:2405.01470}, year={2024} }
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量的训练数据对模型性能至关重要。WildChat Filtered Prompts数据集源自大规模的WildChat原始对话记录,通过精心设计的七阶段流水线构建而成。初始阶段从三百余万条对话轮次中提取首条用户消息,并基于SHA256哈希进行精确去重。随后应用长度与语言过滤器,保留字符数在20至5000之间且经语言检测确认为英语的提示。为进一步提升数据质量,采用MinHash局部敏感哈希进行模糊去重,移除Jaccard相似度超过0.7的近似重复项。后续阶段通过n-gram频率分析、TF-IDF向量化结合K均值聚类等方法,系统性地识别并剔除模板化垃圾信息与协同作弊内容。最终步骤引入基于前缀的模板检测机制,将每种模板的实例数量限制为两个,从而在遏制垃圾信息的同时维持提示的多样性。
特点
该数据集的核心特征在于其经过严格净化与去重处理,最终包含三十万余条独特的英语用户提示,相较于原始数据规模缩减了百分之九十。数据内容聚焦于用户与GPT-4或ChatGPT交互时的初始意图表达,为研究真实场景下的用户查询模式提供了纯净样本。其格式简洁,每条记录均包含唯一的SHA256哈希标识符与原始提示文本,以JSONL格式存储便于程序化读取。此外,数据集衍生出带有开放性评分的版本,进一步拓展了其在模型对齐与偏好学习研究中的应用潜力。尽管数据集仅保留英语内容与单轮对话,且过滤机制可能存在少量误判,但其在去除噪声、保留语义多样性方面的努力,使其成为语言模型训练与用户交互分析的宝贵资源。
使用方法
该数据集主要服务于语言模型的训练与微调,研究人员可直接通过Hugging Face平台加载使用。在具体应用中,开发者可将提示文本作为输入数据,用于监督式微调或指令遵循任务的训练。其纯净的英语提示有助于提升模型在开放域对话生成中的准确性与多样性。对于学术研究而言,该数据集为分析大规模用户与AI交互模式、探究提示工程的常见范式以及识别网络对话中的垃圾信息模式提供了实证基础。使用时应遵循ODC-BY许可协议,并引用原始的WildChat研究论文以尊重其学术贡献。鉴于数据集已进行深度清洗,使用者可专注于模型架构与训练策略的探索,而无需在数据预处理上投入过多精力。
背景与挑战
背景概述
在自然语言处理领域,大规模、高质量的对话数据对于训练和评估语言模型至关重要。WildChat-filtered-prompts数据集由AllenAI等研究机构于2024年构建,其核心研究问题在于如何从海量、嘈杂的真实用户对话中提取出多样且优质的用户提示,以支持语言模型的训练与用户交互模式的研究。该数据集通过对原始WildChat数据实施多阶段清洗流程,显著提升了数据的纯净度与多样性,为对话生成、指令微调等研究方向提供了重要的数据基础,推动了开放域对话系统向更真实、更实用的方向发展。
当前挑战
该数据集旨在解决开放域对话系统中用户提示质量参差不齐、存在大量噪声与重复内容的核心挑战。具体而言,构建过程面临多重技术难题:首先,需从数百万轮原始对话中精准提取首轮用户意图,并处理多轮上下文缺失的问题;其次,设计高效的模糊去重与垃圾检测算法以应对近义重复、模板化垃圾信息及协同机器人活动,同时需平衡过滤的严格性与误删合法提示的风险;此外,语言检测与混合语言内容的识别也是一大难点,需确保数据集的纯英语特性。这些挑战共同指向了在大规模真实数据中实现自动化、高精度质量控制的复杂性。
常用场景
经典使用场景
在自然语言处理领域,WildChat Filtered Prompts数据集常被用作语言模型训练的高质量语料库。该数据集通过多阶段过滤流程,从海量用户对话中提取出独特且多样化的英文提示词,有效避免了重复、垃圾信息及非英语内容的干扰。研究人员利用这些经过净化的提示词,能够训练出更具鲁棒性和泛化能力的对话模型,尤其是在生成式人工智能的预训练与微调阶段,该数据集提供了贴近真实用户意图的输入样本,有助于提升模型对复杂查询的理解与响应质量。
解决学术问题
该数据集主要解决了大规模用户生成内容中存在的噪声过滤与数据质量提升问题。在学术研究中,原始对话数据往往包含大量重复、模板化或低质量的条目,这会影响模型训练的效率和效果。通过引入模糊去重、n-gram垃圾检测及聚类分析等先进技术,该数据集为研究者提供了干净、多样化的提示词集合,从而支持对用户行为模式、提示工程优化以及语言模型偏差分析等关键课题的深入探索。其意义在于为自然语言处理社区树立了数据清洗的标杆,推动了高质量语料库构建方法的发展。
衍生相关工作
该数据集衍生出了一系列经典研究工作,例如基于其构建的开放度评分数据集wildchat-filtered-rated-prompts,进一步扩展了提示词的质量评估维度。相关研究聚焦于用户交互行为的统计分析、提示词多样性度量以及语言模型对齐技术的改进。这些工作不仅深化了对大规模对话数据特性的理解,还为后续数据清洗流程的优化提供了实证基础,推动了整个领域向更高效、更可靠的数据处理范式演进。
以上内容由遇见数据集搜集并总结生成


