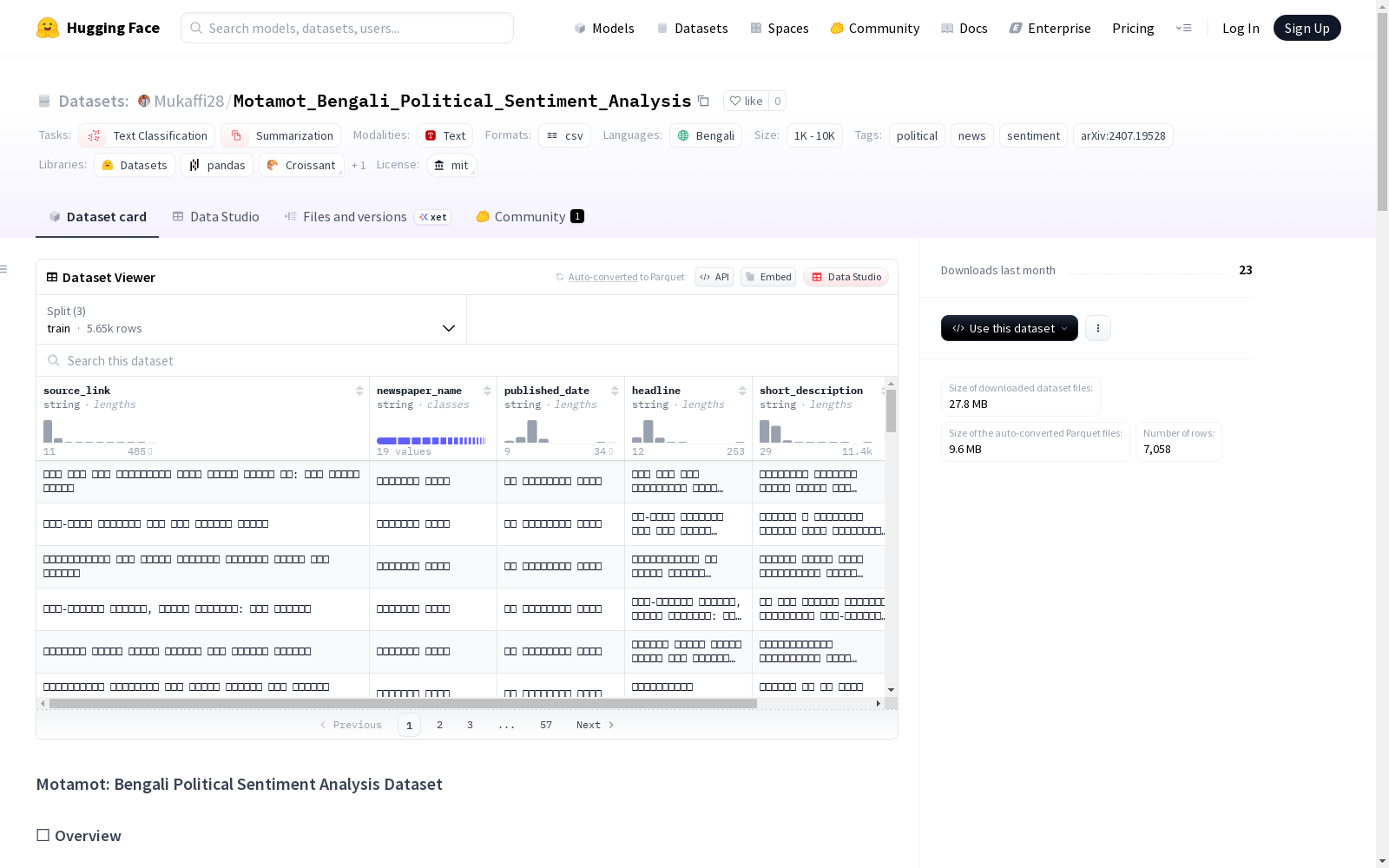
Motamot_Bengali_Political_Sentiment_Analysis
收藏Motamot: 孟加拉语政治情感分析数据集
概述
Motamot是一个孟加拉语政治情感分析数据集,包含7,058个标注数据点。每个条目都标注了积极或消极情感,专门用于分析孟加拉语的政治论述。
该数据集支持自然语言处理研究,应用于情感分类、政治观点挖掘以及为低资源语言预训练和大语言模型基准测试。
数据集统计
| 分割 | 总数 | 积极 | 消极 |
|---|---|---|---|
| 训练集 | 5,647 | 3,306 | 2,341 |
| 测试集 | 706 | 413 | 293 |
| 验证集 | 705 | 413 | 292 |
| 总计 | 7,058 | 4,132 | 2,926 |
数据集结构
数据集包含以下文件:
- train.csv:训练集(5,647个实例)
- test.csv:测试集(706个实例)
- validation.csv:验证集(705个实例)
每个文件包含:
- text:孟加拉语政治陈述
- label:情感类别(Positive或Negative)
基准结果
预训练语言模型比较分析
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| BanglaBERT | 0.8204 | 0.8222 | 0.8204 | 0.8203 |
| Bangla BERT Base | 0.6803 | 0.6907 | 0.6812 | 0.6833 |
| DistilBERT | 0.6320 | 0.6358 | 0.6320 | 0.6317 |
| mBERT | 0.6427 | 0.6496 | 0.6428 | 0.6153 |
| sahajBERT | 0.6708 | 0.6791 | 0.6709 | 0.6707 |
大语言模型比较分析(少样本和零样本)
| 模型(LLM) | 指标 | 零样本 | 5样本 | 10样本 | 15样本 |
|---|---|---|---|---|---|
| GPT 3.5 Turbo | 准确率 | 0.8500 | 0.8900 | 0.9133 | 0.9400 |
| 精确率 | 0.8467 | 0.8867 | 0.9200 | 0.9467 | |
| 召回率 | 0.8533 | 0.8926 | 0.9079 | 0.9342 | |
| F1分数 | 0.8495 | 0.8896 | 0.9139 | 0.9404 | |
| Gemini 1.5 Pro | 准确率 | 0.8608 | 0.8981 | 0.9200 | 0.9633 |
| 精确率 | 0.8931 | 0.8846 | 0.9333 | 0.9667 | |
| 召回率 | 0.8477 | 0.9205 | 0.9091 | 0.9603 | |
| F1分数 | 0.8698 | 0.9022 | 0.9211 | 0.9635 |
引用信息
如果使用此数据集,请引用以下论文:
bibtex @INPROCEEDINGS{10752197, author={Johora Faria, Fatema Tuj and Moin, Mukaffi Bin and Mumu, Rabeya Islam and Alam Abir, Md Mahabubul and Alfy, Abrar Nawar and Alam, Mohammad Shafiul}, booktitle={2024 IEEE Region 10 Symposium (TENSYMP)}, title={Motamot: A Dataset for Revealing the Supremacy of Large Language Models Over Transformer Models in Bengali Political Sentiment Analysis}, year={2024}, pages={1-8}, keywords={Sentiment analysis;Analytical models;Accuracy;Voting;Large language models;Transformers;Market research;Few shot learning;Portals;IEEE Regions;Political Sentiment Analysis;Pre-trained Language Models;Large Language Models;Gemini 1.5 Pro;GPT 3.5 Turbo;Zero-shot Learning;Fewshot Learning;Low-resource Language}, doi={10.1109/TENSYMP61132.2024.10752197} }
许可证
MIT许可证
语言
- bn(孟加拉语)
标签
- political(政治)
- news(新闻)
- sentiment(情感)
- arXiv:2407.19528
规模类别
1K<n<10K