ShareGPT-4o-Image
收藏Hugging Face2025-06-24 更新2025-06-25 收录
下载链接:
https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image
下载链接
链接失效反馈官方服务:
资源简介:
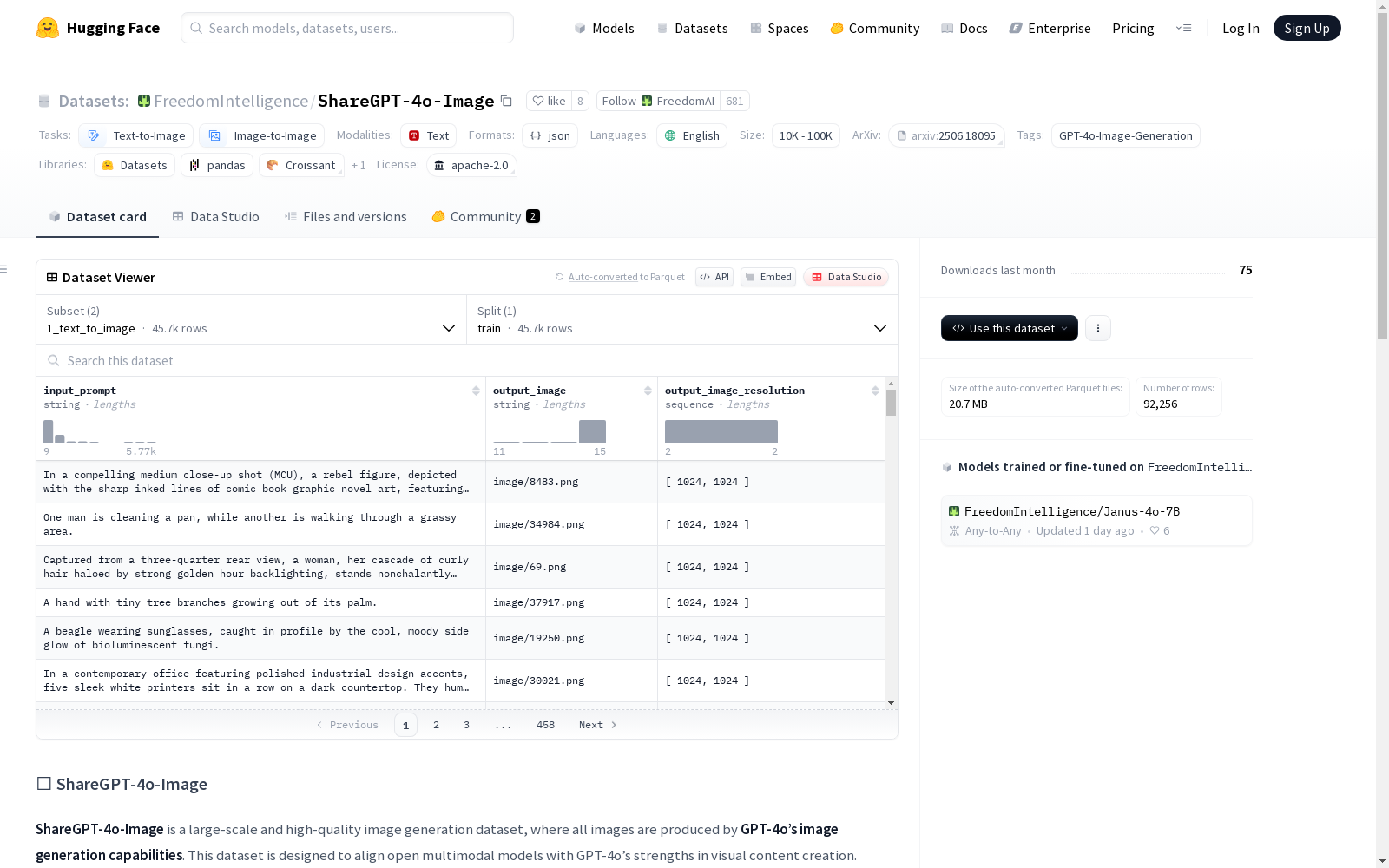
ShareGPT-4o-Image是一个包含由GPT-4o图像生成能力创建的45K个文本到图像和46K个文本和图像到图像样本的大型高质量图像生成数据集。它旨在使开放的多模态模型与GPT-4o在视觉内容创作方面的优势保持一致。
ShareGPT-4o-Image is a large high-quality image generation dataset containing 45K text-to-image and 46K text-and-image-to-image samples created via GPT-4o's image generation capabilities. It aims to align open multimodal models with the strengths of GPT-4o in visual content creation.
提供机构:
FreedomAI
创建时间:
2025-06-16
搜集汇总
数据集介绍
构建方式
在人工智能领域,高质量的图像生成数据集对于推动多模态模型的发展至关重要。ShareGPT-4o-Image数据集通过GPT-4o强大的图像生成能力构建而成,涵盖了45,717个文本到图像样本和46,539个文本与图像到图像样本,总计92,256个样本。数据集的构建过程充分利用了GPT-4o在视觉内容创作方面的优势,确保了生成图像的多样性和高质量。
使用方法
使用ShareGPT-4o-Image数据集时,用户可通过解压提供的.tar文件获取图像数据。数据集分为文本到图像和文本与图像到图像两部分,分别存储于不同的压缩包中。解压后,用户可根据任务需求选择相应的样本进行模型训练或评估。此外,数据集还提供了详细的文档和示例代码,帮助用户快速上手并充分利用其资源。
背景与挑战
背景概述
ShareGPT-4o-Image数据集是由FreedomIntelligence团队于2025年发布的大规模高质量图像生成数据集,旨在利用GPT-4o强大的图像生成能力,推动开放多模态模型在视觉内容创作领域的发展。该数据集包含45,717个文本到图像样本和46,539个文本与图像到图像样本,总计超过91,000个样本,为多模态模型在图像生成和编辑任务中的性能提升提供了重要资源。其核心研究问题聚焦于如何通过GPT-4o生成的图像数据,缩小开放多模态模型与专有模型在视觉内容生成质量上的差距。该数据集的发布为计算机视觉和生成式人工智能领域的研究者提供了新的基准和训练素材,显著促进了多模态模型对齐技术的研究进展。
当前挑战
ShareGPT-4o-Image数据集面临的挑战主要体现在两个方面。在领域问题层面,如何确保生成图像的多样性和真实性以覆盖复杂的现实场景,以及如何解决多模态对齐中存在的语义鸿沟问题,是该数据集试图攻克的关键技术难点。在构建过程层面,大规模高质量图像数据的采集与标注需要巨大的计算资源投入,同时保持生成内容与文本描述之间的高度一致性也对算法提出了严格要求。此外,数据集中可能存在的偏见和安全性问题需要通过精细的设计和过滤机制来缓解,这些因素共同构成了数据集构建过程中的主要挑战。
常用场景
经典使用场景
在计算机视觉与多模态学习领域,ShareGPT-4o-Image数据集以其由GPT-4o生成的大规模高质量图像样本,成为研究者验证文本到图像及图像到图像生成模型性能的基准工具。该数据集通过提供4.5万条文本到图像和4.6万条图文到图像的样本,为模型在创意设计、视觉内容合成等任务中的泛化能力评估提供了标准化测试平台。
解决学术问题
该数据集有效解决了多模态对齐研究中高质量标注数据稀缺的瓶颈问题,其GPT-4o生成的图像具备语义精确、风格多样的特性,为探究视觉语言模型在跨模态理解中的表征能力提供了理想实验材料。通过分析模型在该数据集上的表现,研究者能够深入挖掘文本描述与视觉内容之间的复杂映射关系,推动可控图像生成技术的理论突破。
实际应用
在工业应用层面,该数据集支撑了广告设计、游戏资产生成等场景的快速原型开发。电商平台利用其图文到图像样本训练定制化模型,实现商品场景的智能合成;影视制作领域则借助文本到图像数据批量生成概念图,显著缩短前期创作周期。数据集涵盖的多样化视觉风格为实际应用提供了丰富的可迁移知识。
数据集最近研究
最新研究方向
随着多模态大模型技术的迅猛发展,ShareGPT-4o-Image数据集因其由GPT-4o生成的9.1万高质量图像样本而备受关注。该数据集在文本到图像生成和基于文本与图像的编辑任务中展现出独特价值,为研究者提供了探索多模态对齐和视觉内容生成的新契机。当前研究热点聚焦于如何利用此类数据提升开源模型的图像生成质量,特别是在细节保真度、风格一致性和语义理解深度方面。近期相关论文显示,该数据集已被用于训练Janus-4o-7B等先进模型,在arXiv预印本中论证了其在缩小与商业系统差距方面的潜力。这类资源正推动着生成式AI在创意设计、教育素材合成等领域的应用边界扩展。
以上内容由遇见数据集搜集并总结生成


