jeremycochoy/gift-pretrain-small
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/jeremycochoy/gift-pretrain-small
下载链接
链接失效反馈官方服务:
资源简介:
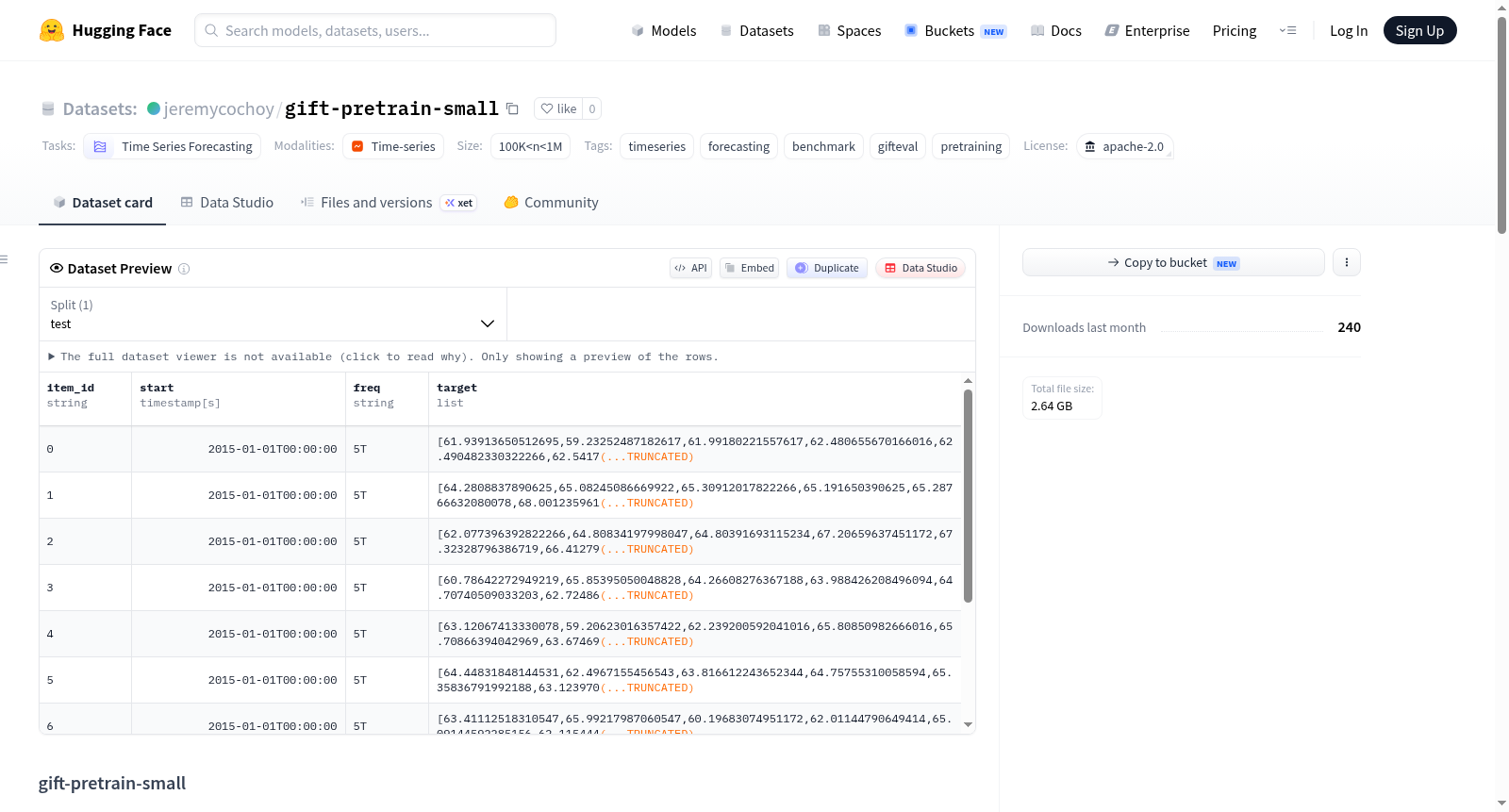
gift-pretrain-small是一个小型、单源的训练数据集,同时包含了GIFT-Eval评估集的镜像,方便使用。该数据集通过从Salesforce/GiftEvalPretrain的每个子数据集中均匀采样10个系列,然后将每个选定的系列裁剪成长度为1025的非重叠窗口,并进行全局混洗构建而成。数据集主要用于时间序列预测任务,包含训练和评估两部分。训练部分的数据存储在parquet文件中,评估部分是GIFT-Eval的镜像。
gift-pretrain-small is a small, single-source training bundle plus a mirror of the GIFT-Eval evaluation set, packaged together for convenience. It is built by uniformly sampling 10 series from every sub-dataset of Salesforce/GiftEvalPretrain, then cropping each selected series into non-overlapping windows of length 1025 and globally shuffling the result. The dataset is primarily used for time-series forecasting tasks and includes both training and evaluation parts. The training data is stored in parquet files, while the evaluation part is a mirror of GIFT-Eval.
提供机构:
jeremycochoy
搜集汇总
数据集介绍
构建方式
该数据集源自对大规模预训练语料库Salesforce/GiftEvalPretrain的精简采样。构建者从该语料库的每一个子数据集(约152个目录)中均匀抽取10条时序序列,选取每个子目录中最小的Arrow文件以确保下载效率。随后,将每条选中的序列裁剪为长度为1025的非重叠窗口,并在全局范围内通过两轮桶式随机打乱操作,以行粒度重新排列。最终产物包含训练分片(small_v1目录下的Parquet文件)和完整的GIFT-Eval评估集镜像,后者被原封不动地保留以便直接对接官方评估工具。整个流程通过专用构建脚本实现,支持并行处理以加速生成。
特点
本数据集以极小体量实现对整个预训练生态的全面覆盖,每一个子数据集均贡献10条序列,避免了字节加权抽样中因数据规模过小而遭丢弃的偏倚。所有系列窗口长度固定为1025,以zstd压缩格式存储于Parquet文件内,并附带元数据列记录原始item_id,便于溯源。评估集镜像严格保持与官方GIFT-Eval一致,无需额外转换即可直接用于测评。作为大规模预训练前的冒烟测试语料,它为验证训练管线正确性提供了轻量级保障,同时保持了跨领域时序预测任务的多样性。
使用方法
用户可直接从HuggingFace下载该数据集,其目录结构包含训练分片(small_v1/shard_*.parquet)和评估集镜像(eval/)。训练数据通过pandas或pyarrow读取Parquet文件,获取固定长度1025的时序窗口及对应source_id(恒为0)与元数据。评估时,将eval/目录路径直接传入官方gift-eval工具链,即可复现标准benchmark评测。若需复现构建过程,可运行项目源码中的训练数据准备脚本,指定输出路径与每子数据集采样数量,并利用分步上传命令将生成的分片与评估镜像推送至HuggingFace仓库。
背景与挑战
背景概述
在时间序列预测领域,大规模预训练数据集是推动通用预测模型发展的关键基石。GIFT-Pretrain-Small数据集由Salesforce研究团队于2024年创建,作为GIFT-Eval Pretrain(约975GB)的轻量级子集,专注于为时间序列预测任务提供快速验证与调试的基准。该数据集从GIFT-Eval Pretrain的152个子数据集中均匀采样,每个子集选取10条时序,并以1025为窗口长度进行非重叠切割,最终生成约百万级样本。其核心研究问题在于检验小规模预训练语料对下游预测任务的迁移能力,为后续扩展至全量预训练提供效果先验。作为GIFT-Eval评测生态的配套工具,该数据集在时间序列预训练社区中承担着模型快速原型验证与超参数调优的关键角色,有效降低了大规模数据处理的实验门槛。
当前挑战
该数据集构建过程中面临多重挑战。首先,领域层面挑战在于时间序列预测任务本身的数据异构性——不同子数据集(如M4日报、ETT能源序列)具有迥异的周期模式、尺度范围和统计分布,如何在采样中保持代表性而非引入偏差成为核心难题。其次,构建过程中需要应对极不均衡的子数据集体量:部分子集(如buildings_900k)包含数百个分片文件,而单文件采样策略可能损失跨分片多样性。此外,为规避字节加权采样中小数据集被丢弃的风险,构建者采用等量分配策略保证每个子集的参与权,但这又可能稀释大子集的频次权重。最后,压缩存储与全局混洗的工程实现需在百万级数据规模下兼顾效率与可复现性,最终通过二轮桶混洗算法平衡了随机性与计算开销。
常用场景
经典使用场景
时序预测领域的研究者常利用gift-pretrain-small作为预训练模型的快速验证与调试工具。该数据集通过对大规模预训练语料库GiftEvalPretrain进行均匀子采样,从每个子数据集中抽取10条时序序列并切割为固定长度1025的非重叠窗口,确保了小型化样本对原始多源分布的代表性。其经典使用场景包括:对比学习框架的快速迭代测试、多源时序表征学习算法的初步验证,以及作为大规模预训练前的健全性检查,帮助研究者以极低的计算成本排查数据流水线和模型架构的逻辑错误。
解决学术问题
该数据集核心解决了时序预训练研究中的两大难题:计算资源约束下的可复现性验证与样本覆盖偏差。在学术层面,它使得研究者能够在不依赖完整975GB语料库的前提下,对多源时序对比学习算法进行端到端验证,尤其适用于验证跨域迁移能力、均匀采样策略对模型泛化的影响。其设计的均匀子采样策略刻意规避了字节加权采样导致的低资源子数据集丢失问题,保障了罕见时序模式的可见性,为分析数据组成与预训练效果之间的因果关系提供了可控的实验基线。
衍生相关工作
基于gift-pretrain-small的数据构造理念,学术界衍生出一系列关于可控子采样的重要工作。研究者受其每个子数据集均等贡献思想的启发,提出了自适应重要性采样方法用于时序预训练语料库的构建,以及基于领域熵的取样策略来平衡多源数据分布。该数据集所依附的GIFT-Eval基准也推动了时序对比学习评估范式的标准化,催生了如跨域迁移评估协议、零样本预测能力度量等后续经典工作。其公开的构建流水线代码已被多个研究团队复用于创建其他领域的轻量级预训练测试包。
以上内容由遇见数据集搜集并总结生成


