SWE-build
收藏Hugging Face2025-11-17 更新2025-11-18 收录
下载链接:
https://huggingface.co/datasets/gwc000/SWE-build
下载链接
链接失效反馈官方服务:
资源简介:
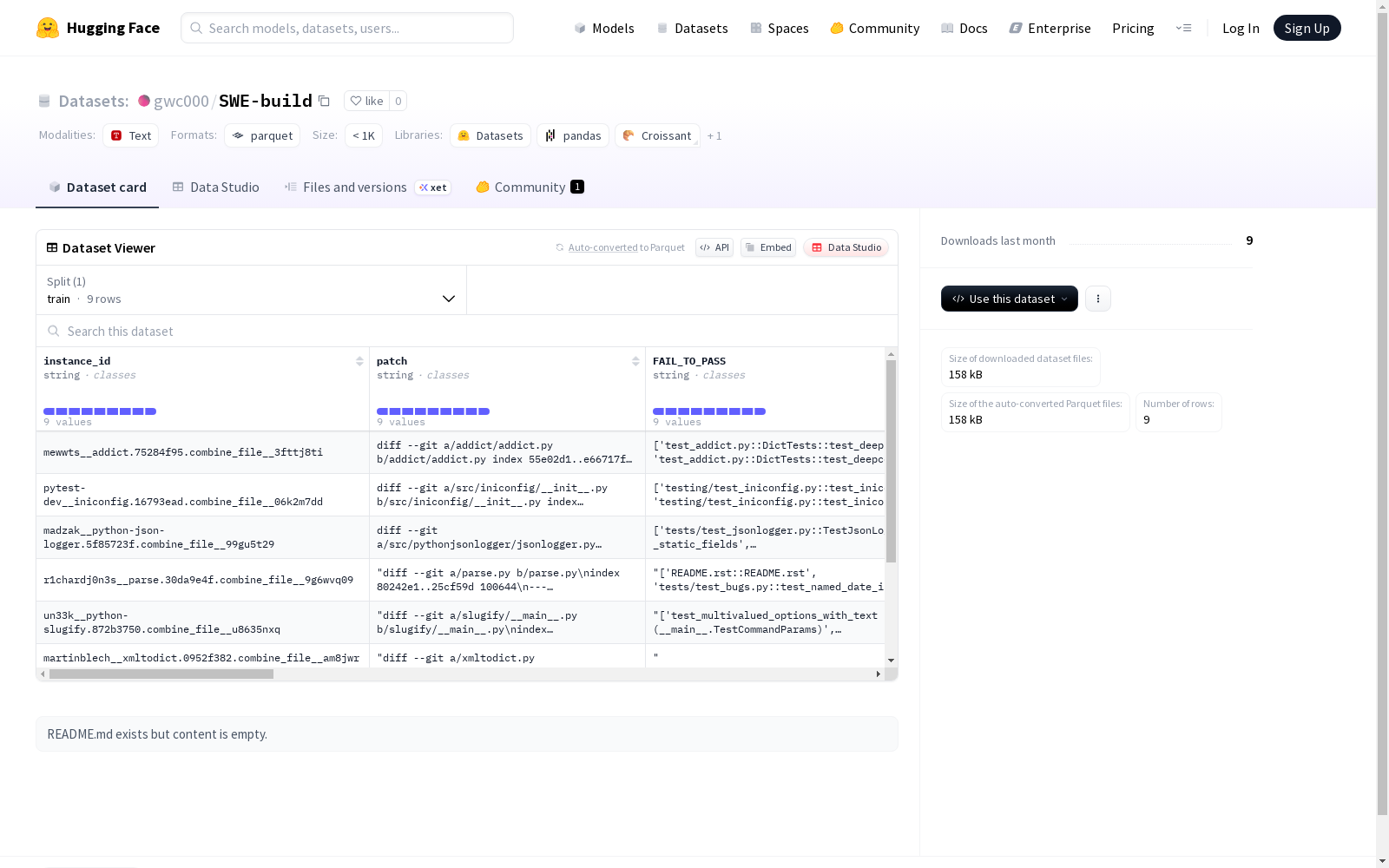
该数据集包含了代码补丁相关的信息,如补丁的ID、补丁内容、补丁状态的转换(失败到成功、成功到成功)、图片名称、代码仓库、问题陈述、GitHub链接、文件数量、编程语言以及创建、更新和推送的时间。数据集分为训练集,包含9个示例,大小为410160字节。
创建时间:
2025-11-15
原始信息汇总
SWE-build数据集概述
数据集基本信息
- 数据集名称:SWE-build
- 存储位置:https://huggingface.co/datasets/gwc000/SWE-build
- 数据量:410,160字节
- 下载大小:158,456字节
- 样本数量:9个训练样本
数据结构特征
数据字段
- instance_id:字符串类型,实例标识符
- patch:字符串类型,代码补丁
- FAIL_TO_PASS:字符串类型,失败到通过的转换
- PASS_TO_PASS:字符串类型,通过到通过的转换
- image_name:字符串类型,镜像名称
- repo:字符串类型,代码仓库
- problem_statement:字符串类型,问题描述
- github_url:字符串类型,GitHub链接
- file_count:int64类型,文件数量
- language:字符串类型,编程语言
- created_at:字符串类型,创建时间
- updated_at:字符串类型,更新时间
- pushed_at:字符串类型,推送时间
数据划分
- 训练集:包含9个样本,占用410,160字节
数据配置
- 配置名称:default
- 数据文件路径:data/train-*
搜集汇总
数据集介绍
构建方式
在软件工程领域,SWE-build数据集通过系统化方法收集真实世界代码库中的补丁实例,每个样本包含实例标识、补丁内容及测试状态转换信息。构建过程基于GitHub平台的开源项目,筛选具有明确问题描述和修复记录的代码变更,确保数据来源的可靠性和时效性。通过提取FAIL_TO_PASS和PASS_TO_PASS等关键字段,完整记录了代码修复前后的状态演变,为软件缺陷修复研究提供了结构化基础。
特点
该数据集以多维度特征见长,涵盖代码补丁、仓库元数据及问题描述等核心要素。其独特之处在于同时捕获测试失败到通过(FAIL_TO_PASS)与测试通过到通过(PASS_TO_PASS)的代码变更路径,完整呈现软件演化的不同场景。数据集还集成开发环境上下文,包括文件数量、编程语言和时间戳等信息,为分析代码修复模式提供了丰富的语义特征和时空维度。
使用方法
使用者可通过标准数据加载接口访问训练集分割,直接获取包含实例ID、补丁内容和测试状态的结构化数据。典型应用场景包括代码自动修复模型的训练与验证,通过对比FAIL_TO_PASS与PASS_TO_PASS样本可深入理解软件维护机制。研究人员还可结合GitHub链接追溯完整开发历史,利用多语言代码样本开展跨编程语言的软件工程实证研究。
背景与挑战
背景概述
随着软件工程领域对自动化代码修复技术的迫切需求,SWE-build数据集应运而生,聚焦于程序补丁生成与验证的核心研究问题。该数据集由前沿研究机构构建,通过收集真实GitHub仓库中的代码变更记录,系统化地呈现了从测试失败到测试通过的程序演化轨迹。其创新性地整合了多维度特征如问题描述、代码补丁和版本元数据,为智能编程辅助系统提供了关键训练资源,显著推动了自动化软件维护技术的研究进程。
当前挑战
在解决程序自动修复问题时,模型需精准理解复杂代码语义并生成符合测试要求的有效补丁,这要求同时克服语法正确性与功能等价性的双重约束。数据集构建过程中,研究人员面临真实场景代码变更稀疏性的挑战,需从海量提交记录中筛选具有完整测试状态转换的样本。此外,跨项目代码风格的差异性以及测试用例覆盖度的不均衡性,进一步增加了数据标准化与质量控制的难度。
常用场景
经典使用场景
在软件工程领域,SWE-build数据集为自动化程序修复研究提供了重要支持。该数据集通过收集真实GitHub仓库中的代码补丁,构建了从测试失败到测试通过的转换实例,成为评估代码修复模型性能的核心基准。研究者利用其结构化数据训练机器学习模型,模拟开发者在实际项目中识别和修正代码缺陷的过程,显著提升了自动化调试系统的准确性和泛化能力。
实际应用
在工业实践中,SWE-build数据集支撑的自动化修复技术已应用于持续集成流程。开发团队可借助基于该数据集训练的模型,快速定位构建失败的根本原因,并生成符合编码规范的修复建议。这种技术显著缩短了软件调试周期,在大型分布式系统维护中尤为突出,为GitHub等代码托管平台的智能辅助开发功能提供了核心技术支撑。
衍生相关工作
该数据集催生了多项具有影响力的衍生研究,包括基于深度学习的程序补丁生成框架和代码变更分析工具。研究者通过扩展其数据范式开发出支持多编程语言的修复系统,如结合抽象语法树分析的神经网络模型。这些工作不仅完善了自动化软件维护的理论体系,还推动了智能编程助手、代码审查自动化等实际应用的发展与落地。
以上内容由遇见数据集搜集并总结生成


