phreshphish
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/phreshphish/phreshphish
下载链接
链接失效反馈官方服务:
资源简介:
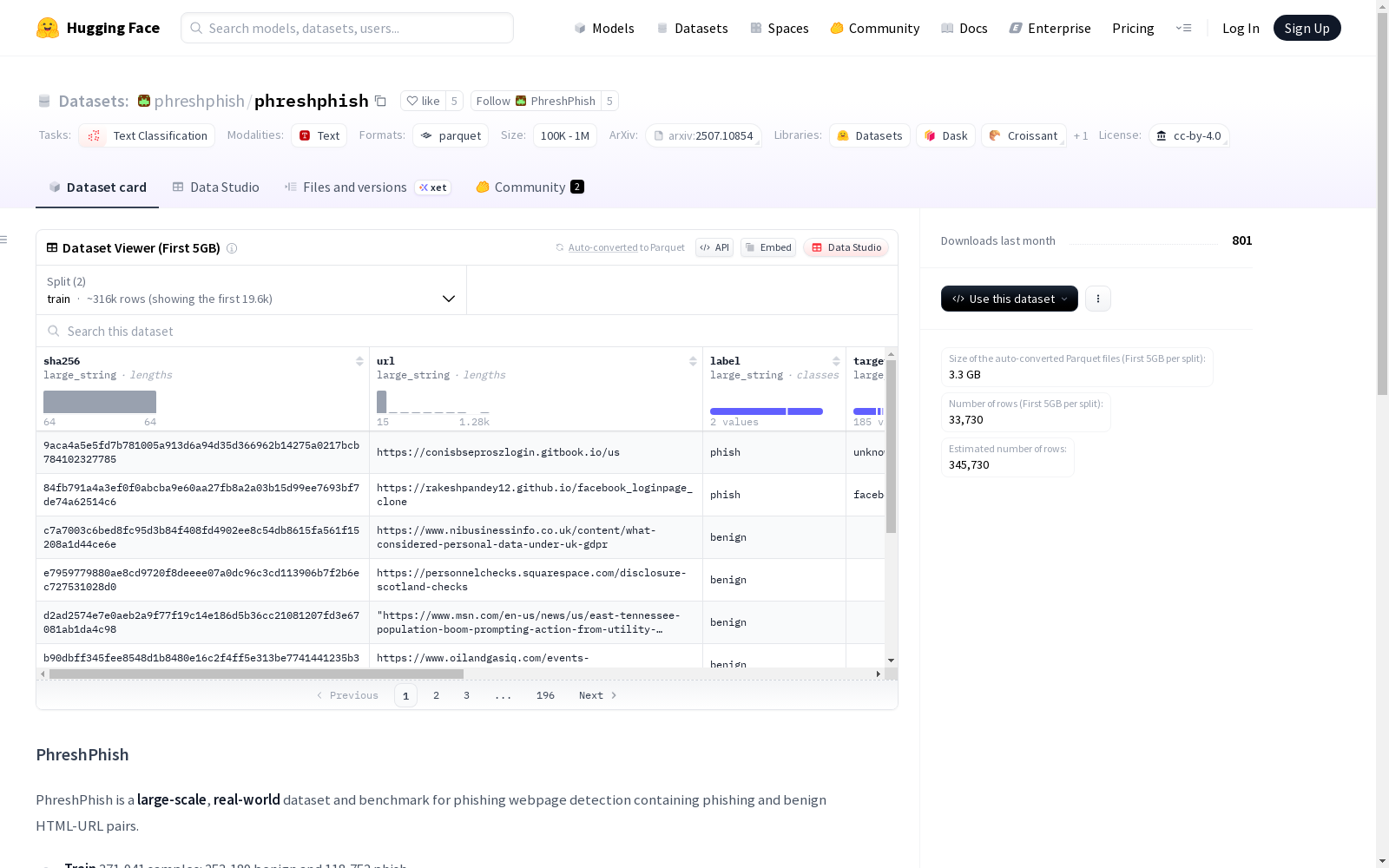
PhreshPhish是一个大规模真实世界的数据集和基准,用于钓鱼网页检测,包含了钓鱼网页和良性网页的HTML-URL对。训练集包含371,941个样本,其中253,189个是良性样本,118,752个是钓鱼样本。测试集包含36,787个样本,其中30,048个是良性样本,6,739个是钓鱼样本。此外,提供了404个基准,基准的基础比率范围从5e-4到5e-2。
PhreshPhish is a large-scale real-world dataset and benchmark for phishing webpage detection, which consists of HTML-URL pairs of phishing and benign webpages. The training set comprises 371,941 samples, including 253,189 benign samples and 118,752 phishing samples. The test set contains 36,787 samples, with 30,048 benign samples and 6,739 phishing samples. Additionally, 404 benchmarks are provided, with their base rates ranging from 5e-4 to 5e-2.
创建时间:
2025-05-14
搜集汇总
数据集介绍
构建方式
作为网络安全领域的重要资源,PhreshPhish数据集的构建过程体现了严谨的采集策略。该数据集通过整合真实网络环境中的网页数据,形成了包含371,941个训练样本和36,787个测试样本的大规模集合。其构建核心在于精确标注钓鱼网页与良性网页的HTML-URL配对,其中训练集包含253,189个良性样本与118,752个钓鱼样本,测试集则包含30,048个良性样本与6,739个钓鱼样本,确保了数据分布的多样性和现实代表性。
特点
该数据集最显著的特征在于其规模性与实用性并重。作为专门针对钓鱼网页检测任务设计的大规模基准数据集,它不仅覆盖了40个不同基准测试场景,还提供了从5e-4到5e-2的基准率范围。数据集中的每个样本都包含完整的HTML内容与对应URL信息,这种结构设计使得研究者能够深入分析网页内容特征与URL特征的关联性,为开发更精准的钓鱼检测模型提供了坚实基础。
使用方法
研究人员可通过HuggingFace平台便捷地获取并使用这一数据集。使用过程中只需调用datasets库的load_dataset函数,分别指定训练集和测试集分割即可载入数据。该数据集特别适用于文本分类任务,用户可基于HTML内容特征开发分类模型,但需注意其使用范围应严格限定于反钓鱼研究领域,且须遵循CC-BY-4.0许可协议的要求。
背景与挑战
背景概述
随着网络钓鱼攻击手段的日益复杂化,网络安全领域亟需高质量数据集支撑检测技术研发。PhreshPhish数据集由Thomas Dalton等研究人员于2025年创建,作为首个大规模真实场景下的钓鱼网页检测基准,其核心研究聚焦于通过HTML-URL配对数据构建精准分类模型。该数据集包含超过40万条经过严格标注的样本,通过多维度基准测试框架为网络安全研究提供了重要实证基础,显著推进了恶意网页识别技术的标准化进程。
当前挑战
钓鱼网页检测领域长期面临动态对抗与特征隐匿的双重困境,攻击者通过域名轮转、内容混淆等手段持续升级逃避技术。PhreshPhish在构建过程中需克服真实环境数据采集的完整性挑战,包括动态内容渲染验证、时效性样本筛选以及类别不平衡处理。面对网页结构异构性带来的特征提取难题,研究团队通过多源验证机制确保标注质量,同时设计分层抽样策略维持数据分布合理性,为模型泛化能力建立提供保障。
常用场景
经典使用场景
在网络安全领域,PhreshPhish数据集作为大规模真实钓鱼网页检测基准,其经典应用场景聚焦于机器学习模型的训练与评估。通过37万余条训练样本与3.6万条测试样本的HTML-URL配对数据,研究者能够构建精准的文本分类系统,利用网页源代码与URL特征识别潜在威胁。该数据集特别适用于监督学习场景,通过分层采样策略确保模型在不同基准率下的鲁棒性验证。
实际应用
实际部署中,基于PhreshPhish训练的检测模型可集成至浏览器扩展与网络安全网关。这些系统能实时扫描网页内容,对金融欺诈、身份窃取等网络攻击进行主动防御。企业安全团队可利用该数据集构建自适应威胁情报系统,通过持续学习机制应对不断演变的钓鱼技术,显著降低社会工程学攻击的成功率。
衍生相关工作
该数据集已催生多项经典研究,包括基于Transformer的混合特征提取架构与动态采样算法。相关工作通过融合视觉渲染特征与文本语义分析,突破了传统URL黑名单的局限。部分衍生研究进一步探索了半监督学习在稀缺标注场景的应用,为轻量级终端防护方案提供了理论支撑。
以上内容由遇见数据集搜集并总结生成


