scb10x/thai_exam
收藏Hugging Face2024-07-08 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/scb10x/thai_exam
下载链接
链接失效反馈官方服务:
资源简介:
ThaiExam是一个泰语知识基准测试数据集,包含来自泰国考试的多种选择题。该数据集最初是为评估Typhoon(泰语大语言模型)而开发的。数据集包含五个不同的考试类型:ONET、IC、TGAT、TPAT-1和A-Level,每个考试类型都有相应的训练和测试数据文件。数据集的使用包括5-shot评估,并且已经集成到HELM排行榜中。
ThaiExam是一个泰语知识基准测试数据集,包含来自泰国考试的多种选择题。该数据集最初是为评估Typhoon(泰语大语言模型)而开发的。数据集包含五个不同的考试类型:ONET、IC、TGAT、TPAT-1和A-Level,每个考试类型都有相应的训练和测试数据文件。数据集的使用包括5-shot评估,并且已经集成到HELM排行榜中。
提供机构:
scb10x
原始信息汇总
数据集概述
数据集名称
Thai_Exam
数据集描述
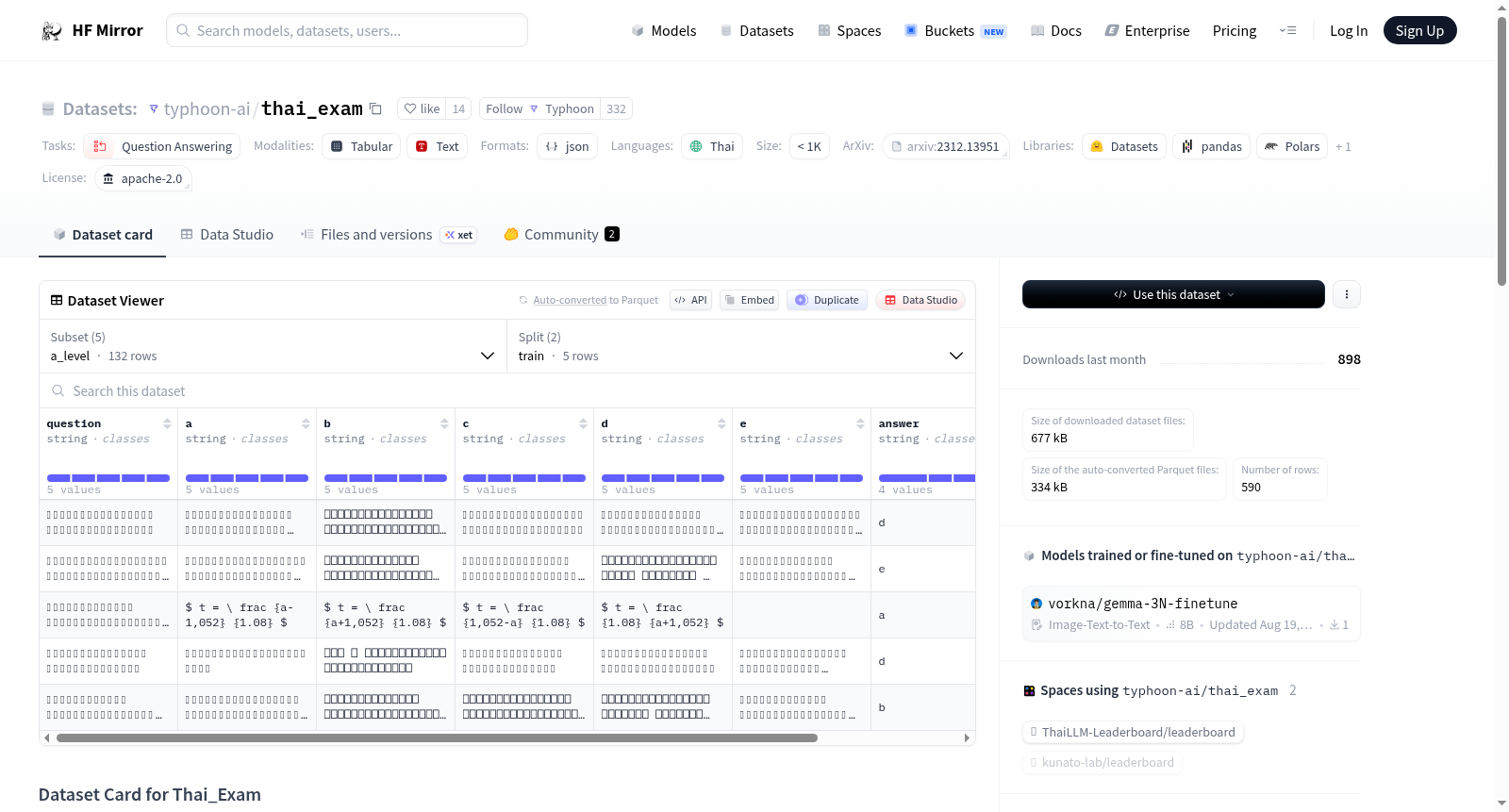
ThaiExam 是一个泰国知识基准测试数据集,包含泰国考试中的多项选择题。该数据集最初是为评估 Typhoon (Thai LLM) 而开发的。数据集包含 5 个拆分,对应 5 个不同的考试。
数据集拆分
-
ONET:
- 描述: 普通国家教育测试 (ONET),适用于泰国学生。基于 12 年级 ONET 考试,包含 4 个科目(泰语、数学、社会学和科学),每题有 5 个选项。
- 数据量: 167 个问题和选项。
-
IC:
- 描述: 投资顾问 (IC) 考试,泰国投资专业人员的执照考试。由泰国证券交易所 (SET) 开发,每题有 4 个选项。
- 数据量: 100 个问题和选项。
-
TGAT:
- 描述: 泰国普通能力测试 (TGAT),泰国国家高中考试,侧重于批判性和逻辑思维能力。
- 数据量: 70 个问题和答案,每题有 4 个选项。
-
TPAT-1:
- 描述: 泰国专业能力测试 1 (TPAT-1),泰国国家高中考试,评估学生在医学院的专业技能要求。包含推理和医学伦理。
- 数据量: 121 个问题和答案,每题有 5 个选项。
-
A-Level:
- 描述: A-Level 考试,学术知识评估考试 (应用知识水平),涵盖基础学科。内容与课程指南一致,强调知识的实际应用。
- 数据量: 132 个问题和答案。
数据集版本
v0.1: 根据 Typhoon 技术报告 和 Typhoon-1.5 博客 的结果报告。v1.0: 当前版本 (revision: d78aef04ea3cc5095545e6951cb39e17c64e26a1)。
数据集引用
@article{pipatanakul2023typhoon, title={Typhoon: Thai Large Language Models}, author={Pipatanakul, Kunat and Jirabovonvisut, Phatrasek and Manakul, Potsawee and Sripaisarnmongkol, Sittipong and Patomwong, Ruangsak and Chokchainant, Pathomporn and Tharnpipitchai, Kasima}, journal={arXiv preprint arXiv:2312.13951}, year={2023} }
搜集汇总
数据集介绍
构建方式
在泰语自然语言处理领域,构建高质量评估基准对于衡量模型性能至关重要。ThaiExam数据集通过系统整合泰国五项国家级及专业考试题目构建而成,涵盖普通国家教育测试(ONET)、投资顾问认证(IC)、泰国通用能力测试(TGAT)、泰国专业能力测试1(TPAT-1)以及应用知识水平考试(A-Level)。每个子集均从官方考试材料中提取标准化选择题,并按照训练集与测试集划分,以JSONL格式存储,确保数据结构的规范性与可扩展性。
特点
该数据集以多维度知识评估为核心特征,覆盖从基础教育到专业认证的广泛领域。各子集分别对应不同考试体系,题目设计融合学科知识、逻辑推理与伦理判断,选项数量呈现四至五项的差异化配置。数据规模精炼而具代表性,每个子集包含70至167道题目,整体遵循小样本评估范式,训练集均提供五条示例以支持上下文学习。
使用方法
研究者可借助该数据集开展泰语语言模型的系统化评估。每个考试子集均提供标准化分割,其中训练集包含五条标注样本,支持五样本上下文学习评估。用户可通过官方提供的评估脚本,在测试集上量化模型在多项选择题任务上的准确率。该数据集已集成至斯坦福大学HELM评估平台,支持与国际基准的横向比较。
背景与挑战
背景概述
在自然语言处理领域,针对特定语言的知识评估数据集对于推动语言模型的本土化发展至关重要。ThaiExam数据集由Typhoon团队于2023年创建,旨在为泰语大规模语言模型提供精准的知识基准测试工具。该数据集整合了泰国五项国家级或专业资格考试的多项选择题,包括普通国家教育测试、投资顾问考试、泰国通用能力测试、泰国专业能力测试1以及A级应用知识考试,覆盖了从基础教育到专业领域的广泛知识范畴。其核心研究问题在于如何系统评估模型对泰语语境下复杂知识和推理能力的掌握程度,该数据集的发布显著促进了泰语语言模型的研究与优化,并为跨语言人工智能的公平性评估提供了重要参考。
当前挑战
ThaiExam数据集所针对的领域问题是泰语知识问答与推理,其挑战在于如何设计能够全面衡量模型对泰语特定文化、教育体系及专业领域知识深度理解的评估任务。这些考试题目往往涉及细微的语境差异、逻辑推理以及跨学科知识整合,对模型的精确理解和推理能力提出了较高要求。在构建过程中,团队需克服多项挑战:原始考试材料的收集与标准化处理涉及版权与格式统一问题;不同考试之间的题型、选项数量及评分标准存在差异,需进行一致性协调;同时,确保数据标注的准确性与代表性,避免偏差,并构建适用于少样本评估的划分策略,亦是数据集构建的关键难点。
常用场景
经典使用场景
在泰语自然语言处理领域,ThaiExam数据集作为一项权威的知识基准测试工具,其经典使用场景聚焦于评估大型语言模型在泰语环境下的综合认知能力。该数据集通过整合泰国国家教育测试(ONET)、投资顾问认证考试(IC)以及大学入学能力测试(TGAT、TPAT-1、A-Level)等多个权威考试的标准化题目,构建了一个覆盖学科知识、逻辑推理与专业素养的多维度评估框架。研究者通常采用五样本上下文学习(5-shot evaluation)范式,将少量示例作为提示输入模型,进而系统衡量模型在复杂选择题解答中的准确性与泛化性能,为泰语语言智能的发展提供了严谨的量化标准。
解决学术问题
ThaiExam数据集有效应对了泰语自然语言处理研究中长期存在的评估体系缺失问题。该数据集通过结构化整合泰国本土化考试内容,为学术界提供了首个大规模、多领域的泰语知识评测基准,解决了以往泰语语言模型评估依赖翻译数据集或小规模任务的局限性。其意义在于建立了跨学科的知识表征评估框架,不仅推动了泰语语言模型在语义理解、逻辑推理等核心能力上的可解释性研究,还促进了多语言人工智能在低资源语言环境下的公平性比较,为泰语乃至东南亚语言的信息处理技术发展奠定了实证基础。
衍生相关工作
围绕ThaiExam数据集,一系列经典研究工作相继展开,显著推动了泰语大语言模型生态的发展。其最初作为Typhoon系列模型的核心评估基准,在技术报告中系统验证了模型在泰语知识任务上的突破性表现;后续研究进一步利用该数据集进行多语言对比分析,揭示了语言特性对模型推理能力的影响机制。此外,基于该数据集构建的HELM集成评测平台,促进了国际学术界对低资源语言模型的关注,衍生出跨语言迁移学习、考试题目自动生成等创新方向,为泰语自然语言处理研究提供了可持续的范式参考。
以上内容由遇见数据集搜集并总结生成


