class-numbers-real-quadratic
收藏Hugging Face2026-04-07 更新2026-04-08 收录
下载链接:
https://huggingface.co/datasets/cahlen/class-numbers-real-quadratic
下载链接
链接失效反馈官方服务:
资源简介:
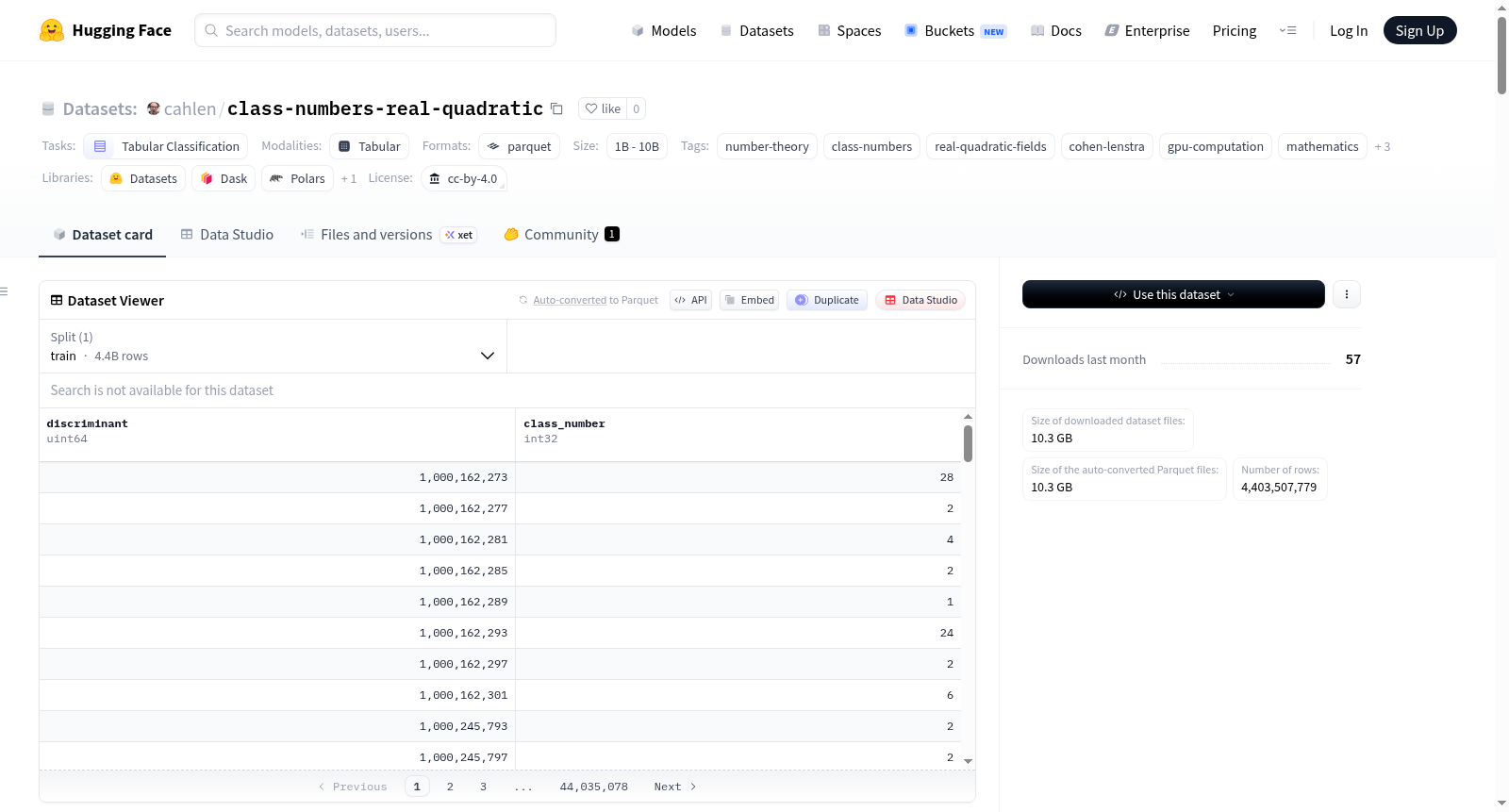
该数据集包含27.4亿个实二次域Q(√d)的类数计算结果,覆盖了所有基本判别式d在[10⁹, 10¹⁰)范围内的值。这是首个公开可用的、在此规模下按判别式分类的类数表,填补了先前研究未公开原始数据的空白。数据集采用Parquet格式存储,包含两个字段:'discriminant'(基本判别式d,uint64类型)和'class_number'(类数h(d),int32类型)。计算工作使用8×NVIDIA B200 DGX集群在30分钟内完成,吞吐量达到153万判别式/秒。数据集特别适用于研究Cohen-Lenstra猜想,展示了类数分布与渐近预测之间的显著差异(在d~10¹⁰时h=1的比例为16.7%,远低于预测的75.4%)。此外,数据集还包含详细的类数分布统计(h=1-16的计数及比例)和p-可分性分析(3、5、7等素数作为除数的观测频率)。计算过程采用GPU平方自由筛、连分数展开计算调节子、欧拉积计算L函数等方法,并通过与PARI/GP的交叉验证确保了结果准确性。
创建时间:
2026-03-31
原始信息汇总
数据集概述:实二次域类数(GPU计算)
数据集基本信息
- 数据集名称:Class Numbers of Real Quadratic Fields (GPU-Computed)
- 发布者:Cahlen Humphreys
- 发布日期:2026年3月
- 许可证:CC BY 4.0
- 任务类别:表格分类
- 标签:数论、类数、实二次域、Cohen-Lenstra、GPU计算、数学、计算数论、代数数论、连分数
- 数据规模:1B < n < 10B
- 配置名称:
1e9_to_1e10 - 数据文件:
data/1e9_to_1e10/*.parquet - 数据描述:包含所有在区间 [10^9, 10^10) 内的基本判别式 d。
数据结构
- 特征:
discriminant(uint64): 基本判别式 d > 0。class_number(int32): 实二次域 Q(√d) 的类数 h(d)。
- 数据划分:
train: 包含 2,735,671,820 个样本。
数据集内容
- 数据范围:基本判别式 d ∈ [10^9, 10^10)。
- 数据总量:2,735,671,820 个基本判别式及其类数。
- 核心内容:每个数据行包含一个基本判别式 d 及其对应的类数 h(d)。基本判别式定义为:d ≡ 1 (mod 4) 且无平方因子,或 d = 4m,其中 m ≡ 2 或 3 (mod 4) 且 m 无平方因子。类数 h(d) 衡量了 Q(√d) 整数环中唯一分解性的失效程度;当 h(d) = 1 时,该环具有唯一分解性。
关键统计信息
- 计算时间:30分钟。
- 硬件配置:8× NVIDIA B200 DGX(1.43 TB VRAM,NVLink 5)。
- 吞吐量:153万判别式/秒。
类数分布
| 类数 h | 数量 | 占比 |
|---|---|---|
| 1 | 456,984,420 | 16.70% |
| 2 | 606,415,562 | 22.17% |
| 3 | 73,409,125 | 2.68% |
| 4 | 540,733,202 | 19.77% |
| 5 | 22,715,143 | 0.83% |
| 6 | 96,852,027 | 3.54% |
| 7 | 10,849,013 | 0.40% |
| 8 | 298,291,861 | 10.90% |
| 9 | 9,027,194 | 0.33% |
| 10 | 30,106,984 | 1.10% |
| 12 | 85,877,392 | 3.14% |
| 16 | 123,589,441 | 4.52% |
Cohen-Lenstra p-可除性观测
| 除数 | 观测比例 | Cohen-Lenstra(渐近)预测 |
|---|---|---|
| 3 整除 h | 15.28% | ~43.99% |
| 5 整除 h | 4.89% | ~23.84% |
| 7 整除 h | 2.35% | ~16.33% |
主要发现:非单调收敛
Cohen 和 Lenstra (1984) 预测 h(d) = 1 的渐近概率约为 75.446%。本数据集显示,在此尺度上观测到的比例正在下降:
| 判别式范围 | h = 1 比例 |
|---|---|
| d < 10^4 | 42.1% |
| d ~ 10^6 | 25.7% |
| d ∈ [10^9, 10^10) | 16.7% |
| 渐近预测 | 75.4% |
该比例最终必须反转并增至 75.4%,但在 d ~ 10^10 时尚未出现转折。这是因为种理论(类群的 2-部分,由 d 的素因子个数决定)在中等判别式处占主导。仅 h = 2, 4, 8, 16 就占所有判别式的 57%。类群的奇数部分——Cohen-Lenstra 实际适用的部分——最终必须占主导,但收敛速度极慢。
计算方法
对于每个基本判别式 d,通过解析类数公式计算 h(d):
h(d) = round( sqrt(d) * L(1, χ_d) / (2 * R(d)) )
计算步骤包括:
- GPU 无平方因子筛法:每个 GPU 线程检查其位置是否被所有 p ≤ √d 的素数 p^2 整除。在设备上分类基本判别式并流压缩为打包数组。
- 计算调节子 R(d):通过连分数展开计算调节子 R(d) = log(ε_d),完全在对数空间中进行以避免 d > 10^9 时的整数溢出。
- 通过欧拉积计算 L-函数:
L(1, χ_d) = ∏(p ≤ 99991) (1 - χ_d(p)/p)⁻¹,其中 9,592 个素数存储在 CUDA__constant__内存中。 - 组装:将 sqrt(d) * L / (2R) 四舍五入到最接近的整数。原子直方图更新用于聚合统计。
验证
- 在整个范围内随机抽取的 1,000 个判别式上,与 PARI/GP 的
qfbclassno()完全匹配。 - 对于 d < 10^4,h = 1 的比例为 42.13%,与 PARI 完全一致。
- 交叉验证:调节子值与 PARI 的
quadregulator()匹配到 12 位以上数字。
硬件详情
| 组件 | 规格 |
|---|---|
| 节点 | NVIDIA DGX B200 |
| GPU | 8× NVIDIA B200(每个 183 GB VRAM) |
| 总 VRAM | 1.43 TB |
| 互连 | NVLink 5 (NV18),全网格 |
| CPU | 2× Intel Xeon Platinum 8570(112 核 / 224 线程) |
| 系统内存 | 2 TB DDR5 |
计划扩展
| 判别式范围 | 估计判别式数量 | 估计时间(8× B200) |
|---|---|---|
| [10^10, 10^11) | ~270亿 | ~65小时(进行中) |
| [10^11, 10^12) | ~2700亿 | ~27天 |
| [10^12, 10^13) | ~2.7万亿 | ~270天 |
相关资源
- 源代码:https://github.com/cahlen/idontknow
- 实验页面:https://bigcompute.science/experiments/class-numbers-real-quadratic/
- 发现报告:https://bigcompute.science/findings/class-number-convergence/
- 所有实验:https://bigcompute.science
- Agent可读索引:https://bigcompute.science/llms.txt
引用
bibtex @dataset{humphreys2026classnumbers, title = {Class Numbers of Real Quadratic Fields: GPU-Accelerated Computation to 10^10}, author = {Humphreys, Cahlen}, year = {2026}, month = mar, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/cahlen/class-numbers-real-quadratic}, note = {2.74 billion fundamental discriminants, 8x NVIDIA B200} }
搜集汇总
数据集介绍
构建方式
在代数数论领域,大规模计算类数的数据集构建一直面临挑战。本数据集采用GPU加速计算范式,针对区间[10^9, 10^10)内的所有基本判别式d,系统计算其实二次域Q(√d)的类数h(d)。构建过程首先通过GPU平方自由筛分算法识别基本判别式,随后利用连分数展开在log空间计算调节子以避免溢出,最后通过基于欧拉积的L函数解析公式完成类数求值。整个流程在配备8块NVIDIA B200的DGX集群上实现全设备计算,耗时仅30分钟便完成了27.35亿个判别式的处理,并通过与PARI/GP的交叉验证确保了计算结果的精确性。
特点
该数据集在计算数论领域具有显著特征,其覆盖了前所未有的规模——包含27.35亿个基本判别式及其对应类数,这是首个在此尺度上公开可用的逐判别式类数表。数据分布呈现深刻的理论意义:类数h(d)=1的比例仅为16.70%,远低于Cohen-Lenstra启发式预测的75.4%渐近值,而h=2、4、8、16等2幂次类数合计占比达57%,揭示了在中等判别式范围内类群2部分的主导作用。这种非单调收敛现象为理解类群结构的演化规律提供了实证基础,数据集同时提供了完整的类数分布统计及p可除性观测值,为代数数论的实证研究建立了新的基准。
使用方法
研究人员可通过Hugging Face的datasets库直接加载该数据集进行流式访问。使用load_dataset函数指定配置名称'1e9_to_1e10'并设置streaming=True参数,即可按需迭代访问数据行,每行包含uint64类型的判别式和int32类型的类数两个字段。这种流式处理方式特别适合大规模数值分析,用户可在此基础上进行类数分布统计、Cohen-Lenstra启发式检验、类群结构相关性研究等计算数论探索。数据集同时提供了完整的复现代码与验证脚本,支持研究者在自有GPU集群上扩展计算至更大判别式范围,为理论数学的实证验证提供了可重复的计算框架。
背景与挑战
背景概述
在计算数论与代数数论领域,实二次域类数的分布规律是理解整数环算术复杂性的核心问题。由Cahlen Humphreys于2026年发布的`class-numbers-real-quadratic`数据集,依托bigcompute.science项目,利用8×NVIDIA B200 DGX集群的强大算力,在30分钟内计算了区间[10⁹, 10¹⁰)内所有27.4亿个基本判别式d对应的类数h(d)。该数据集首次公开了此规模下逐判别式的类数表,突破了先前Jacobson等人2006年工作中数据未公开的局限,为检验Cohen-Lenstra启发式猜想等经典理论提供了前所未有的实证基础。
当前挑战
该数据集旨在解决实二次域类数分布这一基础数论问题的计算与验证挑战。核心挑战在于,Cohen-Lenstra猜想预测类数h(d)=1的渐近概率约为75.446%,但观测数据显示在d~10¹⁰尺度下该比例仅为16.7%,且呈现非单调收敛现象,揭示了理论预测与中等规模数值实验间的巨大鸿沟,凸显了奇部分类群主导效应显现的极端缓慢性。在构建过程中,挑战主要源于海量判别式的高效处理,包括设计GPU平方自由筛法以避免CPU瓶颈、在log空间计算连分数展开以规避大整数溢出,以及利用欧拉乘积在常数内存中近似L函数值,这些均需精巧的并行算法与硬件协同优化方能实现。
常用场景
经典使用场景
在代数数论领域,类数分布的研究长期依赖于理论推测与有限规模的计算验证。该数据集通过GPU集群实现了对区间[10⁹, 10¹⁰)内全部27.4亿个基本判别式类数的高通量计算,为检验科恩-伦斯特拉(Cohen-Lenstra)启发式猜想提供了前所未有的实证基础。研究者可借此分析大尺度下类数的统计规律,特别是观察类数为1的比例如何随判别式增大而缓慢趋近于理论渐近值,从而深入理解实二次域类群结构的演化动力学。
衍生相关工作
基于此类大规模类数数据,可衍生出一系列深入研究。例如,精确拟合类数分布函数并修正现有启发式公式的误差项;探究类数与判别式其他不变量(如基本单位、连分数周期长度)的关联规律;发展更高效的类数计算算法以推进至更大判别式范围。此外,数据驱动的发现可能催生新的猜想,如关于类数特定值出现频率的精细结构,或推动对类群同构类型分布的高维统计分析,从而连接起代数数论与概率数论的交叉前沿。
数据集最近研究
最新研究方向
在计算数论领域,Cohen-Lenstra启发式猜想关于实二次域类数分布的渐近预测,与中等判别式范围内的实际观测数据之间存在显著差异,这构成了当前研究的前沿焦点。该数据集通过GPU集群对十亿量级判别式的类数进行大规模计算,首次公开揭示了在判别式达到10^10时,类数为1的比例仅为16.7%,远低于75.4%的渐近预测值,且分布呈现非单调收敛的复杂模式。这一发现不仅验证了类群2-部分(由判别式的素因子个数决定)在中等尺度上的主导作用,也凸显了奇部分收敛的极端缓慢特性,为理解代数数论中类群结构的深层演化规律提供了前所未有的实证基础。相关计算方法的突破,特别是基于GPU的筛法与连分数展开的高效实现,正推动着计算数论向更大数据规模与更高精度方向演进,直接影响着密码学与丢番图方程等关联领域的研究范式。
以上内容由遇见数据集搜集并总结生成


