PosterDNA
收藏arXiv2026-01-07 更新2026-01-09 收录
下载链接:
https://github.com/wuhaer/PosterVerse
下载链接
链接失效反馈官方服务:
资源简介:
PosterDNA是由华南理工大学与南京信息工程大学联合开发的商业级海报生成数据集,包含16.6万条样本,首创HTML排版文件以支持可扩展文本渲染。该数据集包含三个专项子集:蓝图创建子集(5.7万条)通过逆向工程生成多粒度用户需求,图形生成子集(10万条)涵盖插画、极简等四种设计风格,统一文本布局子集(9000条)提供HTML结构化输出。数据来源于专业设计师协作构建的高质量海报样本,采用多阶段标注流程确保文本密度与布局复杂性。主要应用于商业海报自动生成领域,解决高密度小字号文本渲染不准和后期编辑困难等核心问题。
PosterDNA is a commercial-grade poster generation dataset jointly developed by South China University of Technology and Nanjing University of Information Science and Technology. It contains a total of 166,000 samples, and it is the first to adopt HTML layout files to support scalable text rendering. The dataset includes three specialized subsets: 1. The Blueprint Creation Subset (57,000 samples), which generates multi-granularity user requirements via reverse engineering; 2. The Graphic Generation Subset (100,000 samples) covering four design styles such as illustration and minimalism; 3. The Unified Text Layout Subset (9,000 samples) that provides HTML structured output. The data is derived from high-quality poster samples collaboratively built by professional designers, and a multi-stage annotation pipeline is employed to ensure control over text density and layout complexity. Its main applications lie in the field of automated commercial poster generation, addressing core issues such as inaccurate rendering of high-density small-font text and difficulties in post-editing.
提供机构:
华南理工大学; 南京信息工程大学; INTSIG-SCUT联合实验室·文档分析与识别
创建时间:
2026-01-07
原始信息汇总
PosterVerse数据集概述
数据集名称
PosterDNA
数据集简介
PosterDNA是首个面向商业级、文本密集的海报生成数据集,包含基于HTML的细粒度规范。该数据集旨在为模块化训练和验证提供高质量样本。
数据集特点
- 商业级质量:数据集样本符合商业级海报标准。
- 文本密集设计:海报设计包含密集的文本内容。
- 细粒度规范:提供基于HTML的详细规格说明。
- 用途:支持模块化训练和验证。
数据集状态
根据项目TODO列表,数据集尚未发布。
许可信息
代码和数据集应在非商业研究目的下,依据CC BY-NC-ND 4.0许可进行使用和分发。
版权声明
- 此存储库仅可用于非商业研究目的。
- 商业用途请联系Prof. Lianwen Jin (eelwjin@scut.edu.cn)。
- 版权归属:2026年,华南理工大学深度学习与视觉计算实验室。
相关论文
- 论文标题:PosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
- 作者:Junle Liu, Peirong Zhang, Yuyi Zhang, Pengyu Yan, Hui Zhou, Xinyue Zhou, Fengjun Guo, Lianwen Jin
- 会议:AAAI Conference on Artificial Intelligence
- 年份:2026
- 论文链接:https://arxiv.org/abs/2601.03993
联系方式
如有疑问,可通过junle_liu@foxmail.com联系Junle Liu。
搜集汇总
数据集介绍
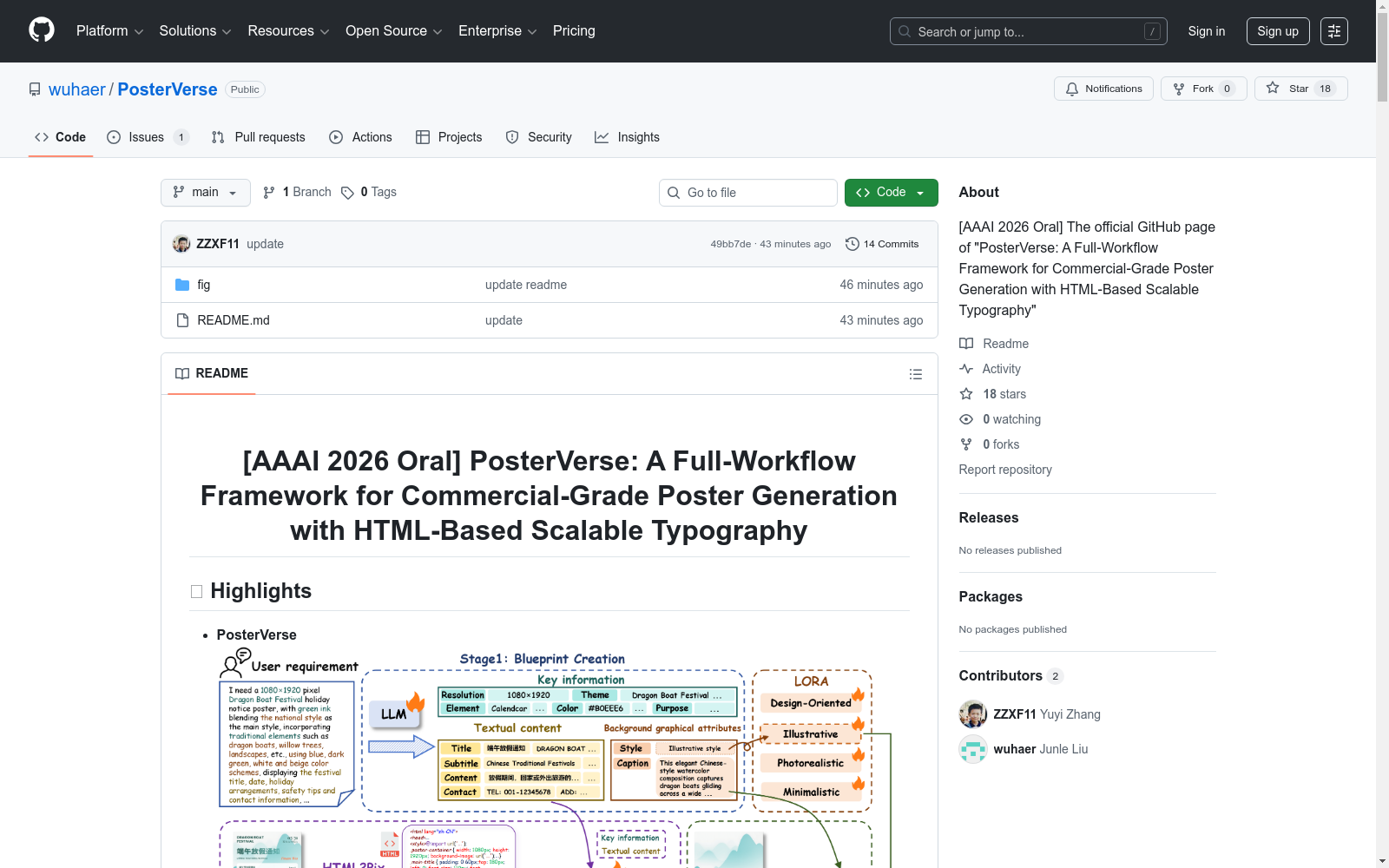
构建方式
在商业级海报设计领域,高质量数据集的构建是推动自动化设计技术发展的关键基础。PosterDNA数据集的构建采用了系统化的多阶段流程,首先从海量商业海报中筛选出包含密集文本内容的高质量样本,随后利用先进的大语言模型进行逆向工程,生成不同详细程度的用户需求描述。构建过程特别注重数据的结构化组织,将每个样本处理为“需求-图形-布局-海报”的四元组形式,并创新性地引入HTML排版文件作为标注格式,确保了文本渲染的精确性与可编辑性。整个数据集涵盖蓝图创建、图形生成和统一布局文本渲染三个专用子集,总计包含超过16万个样本,为模块化训练提供了全面支持。
特点
PosterDNA数据集在商业海报生成领域展现出若干鲜明特征。其核心创新在于首次为中文海报设计引入了基于HTML的排版文件,这一设计从根本上解决了小尺寸、高密度文本的渲染难题,确保了输出内容的绝对准确性。数据集具备高度的商业实用性与专业性,所有样本均包含复杂的布局设计和密集的文本信息,紧密贴合实际商业场景的需求。此外,数据集提供了全工作流程的覆盖数据,支持从需求解析到最终渲染的完整模型训练与验证。其结构化、细粒度的标注体系,不仅提升了模型的训练效率,也为后续的灵活编辑与定制化调整奠定了坚实基础。
使用方法
PosterDNA数据集专为支持模块化的海报生成模型训练而设计,其使用方法与PosterVerse框架的三阶段工作流程紧密对应。在蓝图创建阶段,研究人员可利用数据集中的多层级用户需求与对应的结构化设计规范,训练大型语言模型以准确解析和扩展用户意图。在图形背景生成阶段,数据集提供的无文本背景图像与分层提示词对,可用于微调扩散模型,生成符合特定风格的高质量视觉背景。在统一的布局文本渲染阶段,数据集提供的HTML标注文件是关键训练资源,能够指导多模态大语言模型学习如何将文本内容与视觉背景进行美学整合,并输出可编辑的、保真度极高的最终海报。这种分阶段、针对性的使用方式,极大提升了模型训练的效率和效果。
背景与挑战
背景概述
随着人工智能生成内容技术的迅猛发展,自动化商业海报设计已成为创意产业的重要趋势。然而,现有方法在生成高密度、小尺寸文本方面存在显著缺陷,且缺乏完整的、可编辑的工作流程。为应对这一挑战,华南理工大学与合合信息联合实验室的研究团队于2026年提出了PosterDNA数据集。该数据集作为PosterVerse框架的核心组成部分,是首个引入基于HTML排版文件的中文海报生成数据集,旨在通过提供细粒度、可扩展的文本渲染方案,从根本上解决商业级海报设计中文本准确性与布局灵活性的核心问题,为自动化设计系统提供了高质量的模块化训练与验证基础。
当前挑战
PosterDNA数据集致力于解决商业海报自动生成领域的两大核心挑战。在领域问题层面,其首要挑战在于如何精准合成高密度、小尺寸的文本,尤其是复杂的中文字符,同时确保文本语义的完整性与视觉美观度,这是现有文本到图像生成模型的普遍短板。在构建过程层面,数据集创建面临严峻挑战,包括需要从海量商业海报中逆向工程出多层次、细粒度的设计蓝图,并手动标注为结构化的HTML格式;同时,为确保数据质量,必须进行严格的美学筛选、去重与专业人工校正,整个构建过程耗时数月,其中人工校正环节占据了绝大部分工作量,对专业性与资源投入提出了极高要求。
常用场景
经典使用场景
在商业海报自动生成领域,PosterDNA数据集为端到端设计流程提供了关键支撑。该数据集通过精细标注的HTML排版文件,使模型能够学习复杂布局与高密度文本的精准渲染,尤其适用于需要严格遵循品牌规范与信息密度的营销材料生成。其经典应用场景在于训练和验证如PosterVerse等全流程框架,确保从用户需求解析到最终视觉输出的每个环节都能达到商用级质量标准,为自动化设计系统奠定了数据基础。
解决学术问题
PosterDNA数据集主要解决了海报生成研究中文本渲染准确性不足与工作流程碎片化两大核心问题。传统方法常因缺乏高质量、结构化的训练数据,导致生成文本易出现错字、遗漏或排版混乱,尤其在处理中文等高密度字符时表现欠佳。该数据集通过引入HTML格式的细粒度标注,实现了文本的可缩放渲染与灵活编辑,不仅提升了模型对小型密集文字的合成能力,还为布局规划与背景生成的协同优化提供了统一基准,推动了商用级海报生成技术的标准化发展。
衍生相关工作
基于PosterDNA数据集,研究者们衍生出一系列聚焦于文本-图像合成与布局规划的相关工作。例如,结合大语言模型的需求解析模块、针对多风格背景的定制化扩散模型,以及利用多模态大模型进行HTML端到端渲染的架构探索。这些工作进一步拓展了数据集的潜力,如在多语言海报生成、动态布局调整与交互式编辑等方向取得进展,形成了从数据到方法再到应用的完整研究链条,持续推动智能设计领域向更高精度与实用性演进。
以上内容由遇见数据集搜集并总结生成


