DataAnalysis_STARS
收藏魔搭社区2025-09-16 更新2025-08-16 收录
下载链接:
https://modelscope.cn/datasets/Starsniu/DataAnalysis_STARS
下载链接
链接失效反馈官方服务:
资源简介:
# 🫣课题Introduction
---
## 社交媒体文本情感分析
### 数据准备与预处理
* **文本清洗** :通过正则表达式等方法去除HTML标签、特殊符号和无关字符等噪声信息,提高文本质量和情感分析准确性。
* **数据选择** :从微博、推特等社交媒体平台收集涵盖正面、负面和中性等多种情感表达的用户评论数据,确保数据多样性和代表性。
* **清洗效果** :展示清洗前后文本对比,验证清洗效果,清洗后的文本更清晰,便于情感分析模型的训练和应用。
### 情感分析模型
* **英文情感分析** :使用NLTK库和VADER模型,VADER模型通过词典和规则判断文本情感,对英文评论情感分析效果良好。
* **中文情感分析** :应用SnowNLP,其结合中文语言特点,能准确判断中文评论情感,适应中文情感分析需求。
* **模型评估** :评估模型的准确率、召回率和F1值,通过交叉验证等方法确保情感分析结果可靠,为应用提供保障。
### 可视化与报告
* **情感分布饼图** :展示正面、负面和中性情感占比,直观呈现情感分布,便于快速了解用户情感倾向,为舆情监测提供依据。
* **情感词云** :展示高频情感词汇,突出情感表达核心词汇,帮助快速把握用户情感焦点,提升舆情分析效率。
* **报告撰写** :根据分析结果总结用户情感倾向和热点话题,为社交媒体运营提供数据支持,助力舆情管理和内容优化。
### 扩展与优化
* **混合编程** :结合Python和Java进行混合编程,充分利用两种语言优势,优化情感分析系统架构,提升性能和稳定性。
* **模型优化** :通过调整参数、改进算法优化情感分析模型,提高准确率,更好地适应不同场景需求。
* **技术选择** :探索深度学习模型BERT等多种情感分析技术和工具,根据项目需求选择合适技术,确保系统高效性和准确性。
---
# 🫨数据集Recommendation
---
## 来自[Kaggle](https://www.kaggle.com/datasets/cosmos98/twitter-and-reddit-sentimental-analysis-dataset)
> 从 Twitter 和 Reddit 中提取的推文和评论用于情感分析。
### 背景
这是一个作为大学项目的一部分创建的数据集,项目主题是使用 PySpark 对多源社交媒体平台进行情感分析。
这两个数据集分别包含来自 Twitter 的带有情感标签的推文和来自 Reddit 的带有情感标签的评论。
1. Twitter 数据集
2. Reddit 数据集
所有这些推文和评论都是使用各自的 API(Tweepy 和 PRAW)提取的。这些推文和评论是关于纳伦德拉·莫迪和其他领导人,以及人们对下一任总理的看法(在印度 2019 年举行的大选背景下)。
所有来自 Twitter 和 Reddit 的推文和评论都使用 Python 的 re 库以及 NLP 进行了清理,并为每个推文/评论分配了从 -1 到 1 的情感标签。
1. 0 表示中性推文/评论
2. 1 表示积极情感
3. -1 表示消极推文/评论
### 数据集结构
Twitter.csv 数据集包含大约 163K 条带有情感标签的推文。
Reddit.csv 数据集包含大约 37K 条带有情感标签的评论。
因此,每个数据集通常有两列,第一列包含清理后的推文和评论,第二列指示其情感标签。
### 原始数据集
* Twitter_Data.csv
* Reddit_Data.csv
---
## **来自[DataFountain](https://www.datafountain.cn/competitions/423)**
### 赛题介绍
新型冠状病毒(COVID-19)感染的肺炎疫情牵动着全国人民的心,全国同舟共济、众志成城,打响了一场没有硝烟的疫情阻击战。习近平指出:要鼓励运用大数据、人工智能、云计算等数字技术,在疫情监测分析、病毒溯源、防控救治、资源调配等方面更好发挥支撑作用。
为助力疫情防控和疫情之后的经济社会恢复工作,推动北京市政府数据开放,吸纳大数据产业顶尖社会资源,充分释放专业人才智慧资源,北京市经济和信息化局、中国计算机学会大数据专家委员会联合主办 **科技战疫·大数据公益挑战赛** 。
本赛题也是第二十六届全国信息检索学术会议 (The 26th China Conference on Information Retrieval, CCIR 2020)评测大赛赛题 。
### 赛题背景
2019新型冠状病毒(COVID-19)感染的肺炎疫情发生对人们生活生产的方方面面产生了重要影响,并引发国内舆论的广泛关注,众多网民参与疫情相关话题的讨论。为了帮助政府掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,本赛题针对疫情相关话题开展网民情绪识别的任务。
### 赛题任务
给定微博ID和微博内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的。
### 数据集使用
竞赛数据:竞赛数据归数据提供单位所有,赛题及数据在官方竞赛平台进行免费开源,数据提供方授权参赛人员使用提供的数据进行指定比赛的模型训练工作,参赛人员不得将数据用于任何商业用途。
> **若做科研使用,请注明数据来源于相关数据提供单位;**
### 数据简介
数据集依据与“新冠肺炎”相关的230个主题关键词进行数据采集,抓取了2020年1月1日—2020年2月20日期间共计100万条**微博**数据,并对其中10万条数据进行人工标注,标注分为三类,分别为:1(积极),0(中性)和-1(消极)。
### 数据说明
竞赛数据以csv格式进行存储,包括nCoV_100k.labled.csv和nCoV_900k.unlabled.csv两个文件,其中:
**nCoV_100k.labled.csv:** 包含10万条用户标注的微博数据,具体格式如下:
[微博id,微博发布时间,发布人账号,微博中文内容,微博图片,微博视频,情感倾向]
1. 微博id,格式为整型。
2. 微博发布时间,格式为xx月xx日 xx:xx。
3. 发布人账号,格式为字符串。
4. 微博中文内容,格式为字符串。
5. 微博图片,格式为url超链接,[]代表不含图片。
6. 微博视频,格式为url超链接,[]代表不含视频。
7. 情感倾向,取值为{1,0,-1}。
**nCoV_900k.unlabled.csv**为90万条未标注的微博数据,包含与“新冠肺炎”相关的90万条未标注的微博数据,具体格式如下:
[微博id,微博发布时间,发布人账号,微博中文内容,微博图片,微博视频]
1. 微博id,格式为整型。
2. 微博发布时间,格式为xx月xx日 xx:xx。
3. 发布人账号,格式为字符串。
4. 微博中文内容,格式为字符串。
5. 微博图片,格式为url超链接,[]代表不含图片。
6. 微博视频,格式为url超链接,[]代表不含视频。
### 原始数据集
- nCoV_100k.labled.csv
- nCoV_900k.unlabled.csv
---
# 使用方式
1、进入[魔塔社区](https://www.modelscope.cn/my/overview)
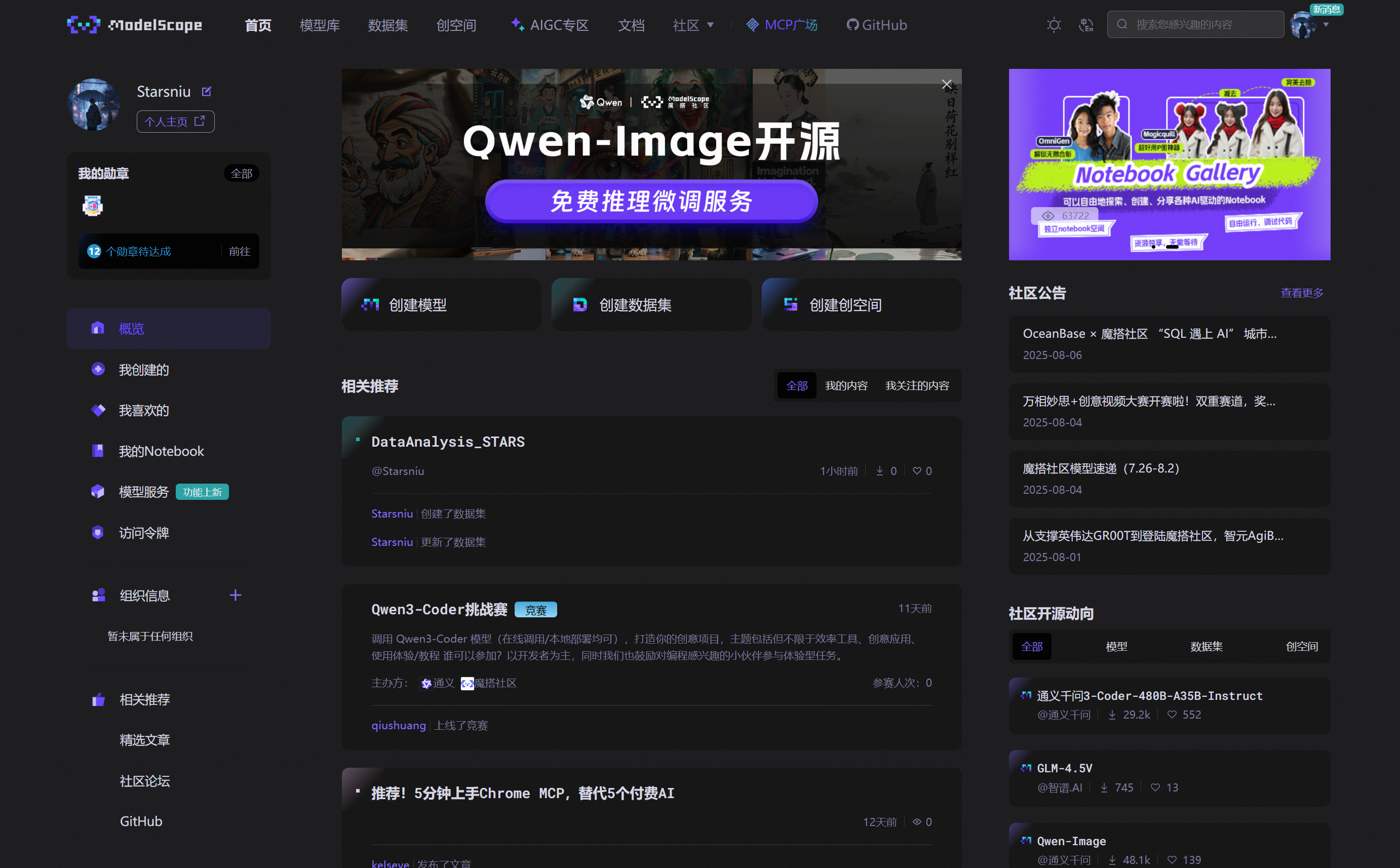
2、点击 `我的NoteBook(需要注册登录后进入首页)`
3、选择 `魔塔平台免费实例`
4、选择 `方式一`并 `启动`
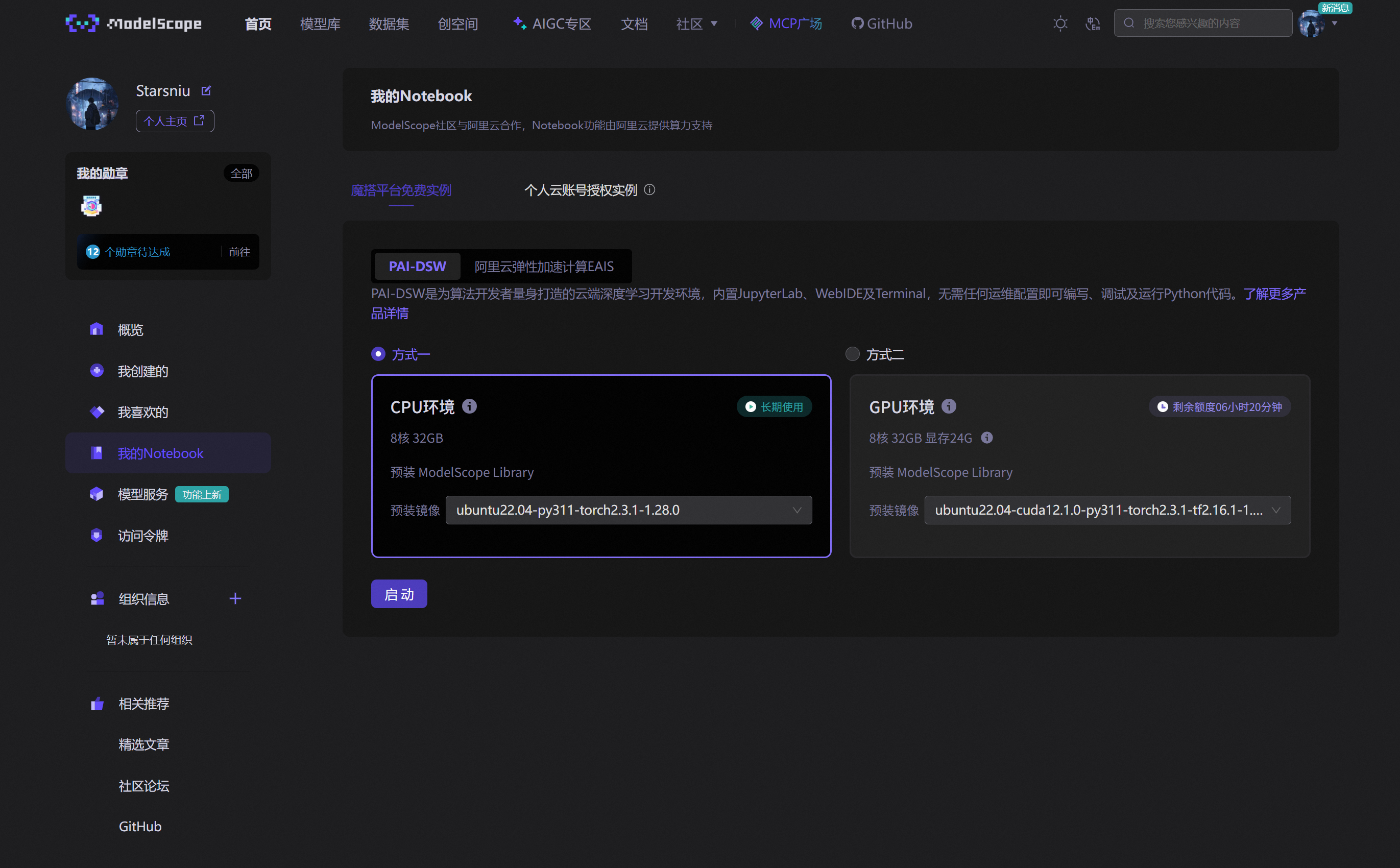
等待一段时间后点击 `查看NoteBook`进入 `JupyterLab`
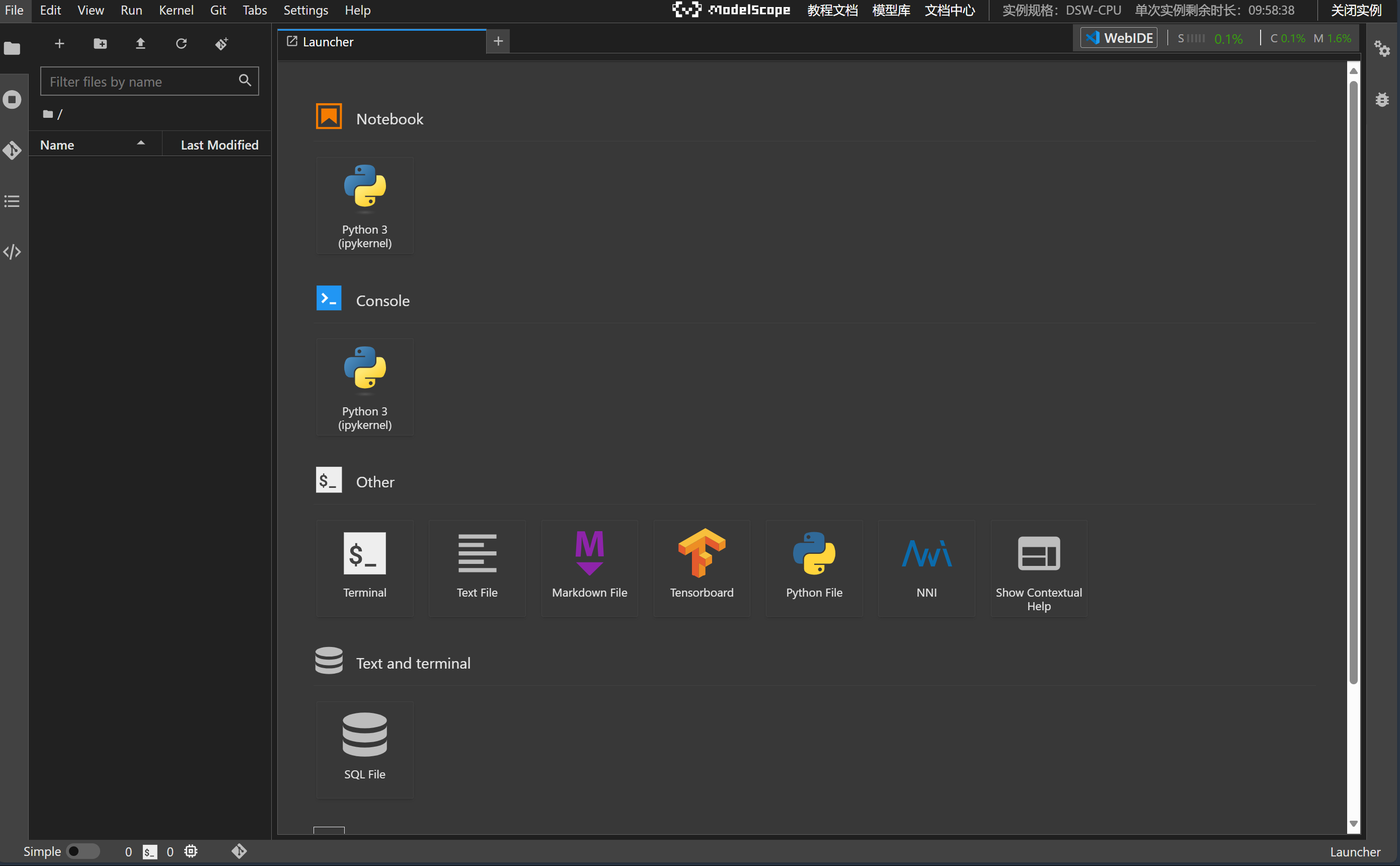
5、选择 `Other`的 `Terminal`
```bash
git lfs install
git clone https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS.git
```
将上述内容复制粘贴到 `终端`运行
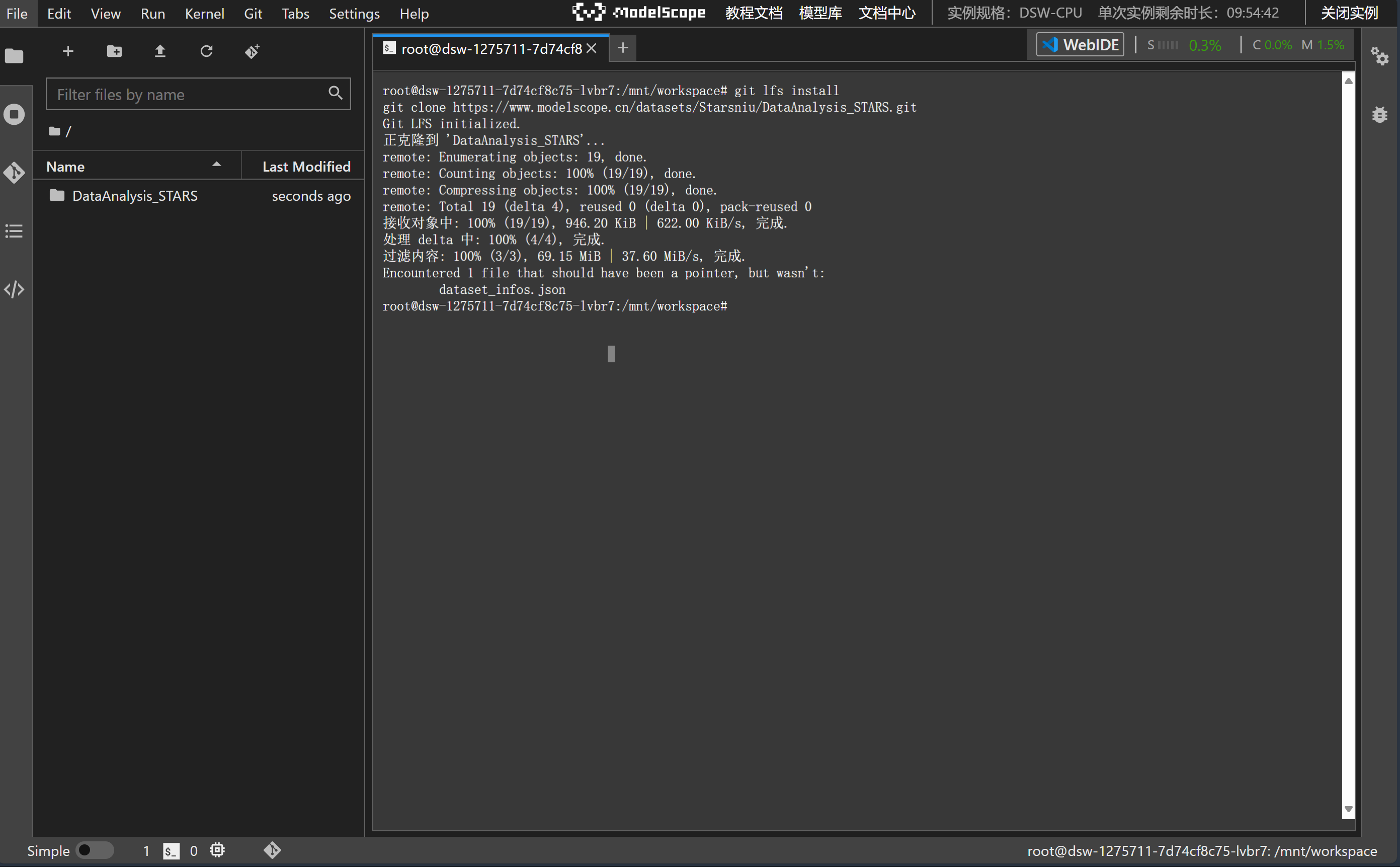
选择 `DA.ipynb`就可以一键运行
---
# [数据集页面](https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS)
```html
https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS
```
数据集文件元信息以及数据文件,请浏览“数据集文件”页面获取。
**下载方法**
- SDK
```python
#数据集下载
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('Starsniu/DataAnalysis_STARS')
#您可按需配置 subset_name、split,参照“快速使用”示例代码
```
- GIT
```bash
# 请确保 lfs 已经被正确安装
git lfs install
git clone https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS.git
```
---
> **license: MIT License**
---
# 🫣 Project Introduction
## Social Media Text Sentiment Analysis
### Data Preparation and Preprocessing
* **Text Cleaning**: Remove noise information such as HTML tags, special symbols and irrelevant characters using regular expressions and other methods to improve text quality and the accuracy of sentiment analysis.
* **Data Selection**: Collect user comment data covering positive, negative and neutral emotional expressions from social media platforms such as Weibo and Twitter to ensure data diversity and representativeness.
* **Cleaning Effect**: Show the text comparison before and after cleaning to verify the cleaning effect. The cleaned text is clearer, which facilitates the training and application of sentiment analysis models.
### Sentiment Analysis Model
* **English Sentiment Analysis**: Use the NLTK library and VADER model. The VADER model judges text sentiment through lexicons and rules, and performs well in English comment sentiment analysis.
* **Chinese Sentiment Analysis**: Apply SnowNLP, which combines the characteristics of the Chinese language, can accurately judge the sentiment of Chinese comments, and meets the needs of Chinese sentiment analysis.
* **Model Evaluation**: Evaluate the accuracy, recall and F1-score of the model, and ensure the reliability of sentiment analysis results through cross-validation and other methods to provide guarantees for applications.
### Visualization and Report
* **Sentiment Distribution Pie Chart**: Show the proportion of positive, negative and neutral sentiments, intuitively present the emotional distribution, help quickly understand user emotional tendencies, and provide a basis for public opinion monitoring.
* **Sentiment Word Cloud**: Show high-frequency sentiment words, highlight core sentiment-expressing words, help quickly grasp the focus of user sentiment, and improve the efficiency of public opinion analysis.
* **Report Writing**: Summarize user emotional tendencies and hot topics based on analysis results, provide data support for social media operations, and assist in public opinion management and content optimization.
### Expansion and Optimization
* **Hybrid Programming**: Combine Python and Java for hybrid programming, make full use of the advantages of both languages, optimize the sentiment analysis system architecture, and improve performance and stability.
* **Model Optimization**: Optimize the sentiment analysis model by adjusting parameters and improving algorithms to improve accuracy and better adapt to different scenario needs.
* **Technology Selection**: Explore various sentiment analysis technologies and tools such as the deep learning model BERT, and select appropriate technologies according to project requirements to ensure the efficiency and accuracy of the system.
---
# 🫨 Dataset Recommendation
---
## From [Kaggle](https://www.kaggle.com/datasets/cosmos98/twitter-and-reddit-sentimental-analysis-dataset)
> Tweets and comments extracted from Twitter and Reddit for sentiment analysis.
### Background
This dataset was created as part of a university project focused on multi-source social media platform sentiment analysis using PySpark. The two datasets respectively contain sentiment-labeled tweets from Twitter and sentiment-labeled comments from Reddit.
1. Twitter Dataset
2. Reddit Dataset
All these tweets and comments were extracted using their respective APIs (Tweepy and PRAW). The content is about Narendra Modi and other leaders, as well as people's views on the next prime minister against the backdrop of the 2019 Indian general election.
All tweets and comments from Twitter and Reddit were cleaned using Python's `re` library and NLP, and each tweet/comment was assigned a sentiment score ranging from -1 to 1.
1. 0 indicates neutral tweets/comments
2. 1 indicates positive sentiment
3. -1 indicates negative tweets/comments
### Dataset Structure
The `Twitter.csv` dataset contains approximately 163,000 sentiment-labeled tweets.
The `Reddit.csv` dataset contains approximately 37,000 sentiment-labeled comments.
Each dataset typically has two columns: the first column contains cleaned tweets and comments, and the second column indicates its sentiment label.
### Original Datasets
* Twitter_Data.csv
* Reddit_Data.csv
---
## From [DataFountain](https://www.datafountain.cn/competitions/423)
### Competition Introduction
The pneumonia epidemic caused by COVID-19 has affected the hearts of people across the country, and the entire nation has stood together and fought a battle without smoke. Xi Jinping pointed out: It is necessary to encourage the use of big data, artificial intelligence, cloud computing and other digital technologies to better play a supporting role in epidemic monitoring and analysis, virus tracing, prevention, control and treatment, resource allocation and other aspects.
To help epidemic prevention and control and post-epidemic economic and social recovery work, promote the opening of government data in Beijing, attract top social resources from the big data industry, and fully release the wisdom resources of professional talents, the Beijing Municipal Bureau of Economy and Information Technology and the Big Data Expert Committee of China Computer Federation jointly hosted the **Science and Technology Anti-Epidemic · Big Data Public Welfare Challenge**.
This competition is also the evaluation competition topic of the 26th China Conference on Information Retrieval (CCIR 2020).
### Competition Background
The outbreak of pneumonia caused by COVID-19 in 2019 has had an important impact on all aspects of people's lives and production, and has aroused widespread attention from domestic public opinion. Many netizens participated in discussions on epidemic-related topics. To help the government grasp the real public opinion situation and scientifically and efficiently carry out prevention and control publicity and public opinion guidance, this competition aims to carry out the task of identifying netizens' emotions for epidemic-related topics.
### Competition Task
Given the Weibo ID and Weibo content, design an algorithm to perform emotion recognition on the Weibo content, and judge whether the Weibo content is positive, negative or neutral.
### Dataset Usage
The competition data is owned by the data provider. The competition questions and data are freely open-sourced on the official competition platform. The data provider authorizes participants to use the provided data for model training of the specified competition. Participants shall not use the data for any commercial purposes.
> **If used for scientific research, please indicate that the data comes from the relevant data provider;**
### Data Introduction
The dataset was collected based on 230 topic keywords related to "COVID-19", and a total of 1 million Weibo data were captured from January 1, 2020 to February 20, 2020. Among them, 100,000 pieces of data were manually annotated, which are divided into three categories: 1 (positive), 0 (neutral) and -1 (negative).
### Data Description
The competition data is stored in CSV format, including two files: `nCoV_100k.labled.csv` and `nCoV_900k.unlabled.csv`, where:
**nCoV_100k.labled.csv**: Contains 100,000 pieces of user-annotated Weibo data, the specific format is as follows:
[Weibo ID, Weibo release time, publisher account, Weibo Chinese content, Weibo images, Weibo videos, emotional tendency]
1. Weibo ID: Integer format.
2. Weibo release time: Format as xx month xx day xx:xx.
3. Publisher account: String format.
4. Weibo Chinese content: String format.
5. Weibo images: URL hyperlink, [] means no images.
6. Weibo videos: URL hyperlink, [] means no videos.
7. Emotional tendency: Value range {1, 0, -1}.
**nCoV_900k.unlabled.csv** is 900,000 unlabeled Weibo data related to "COVID-19", the specific format is as follows:
[Weibo ID, Weibo release time, publisher account, Weibo Chinese content, Weibo images, Weibo videos]
1. Weibo ID: Integer format.
2. Weibo release time: Format as xx month xx day xx:xx.
3. Publisher account: String format.
4. Weibo Chinese content: String format.
5. Weibo images: URL hyperlink, [] means no images.
6. Weibo videos: URL hyperlink, [] means no videos.
### Original Datasets
- nCoV_100k.labled.csv
- nCoV_900k.unlabled.csv
---
# Usage Method
1. Enter the [ModelScope Community](https://www.modelscope.cn/my/overview)

2. Click `My NoteBook (need to register and log in to enter the homepage)`
3. Select `ModelScope Platform Free Instance`
4. Select `Method 1` and `Start`

Wait for a period of time, then click `View NoteBook` to enter `JupyterLab`

5. Select `Terminal` under `Other`
bash
git lfs install
git clone https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS.git
Copy and paste the above content into the `Terminal` to run

Select `DA.ipynb` to run with one click

---
# [Dataset Page](https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS)
html
https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS
For dataset file metadata and data files, please browse the "Dataset Files" page.
**Download Methods**
- SDK
python
# Dataset Download
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('Starsniu/DataAnalysis_STARS')
# You can configure subset_name and split as needed, refer to the "Quick Use" sample code
- GIT
bash
# Please ensure that lfs is installed correctly
git lfs install
git clone https://www.modelscope.cn/datasets/Starsniu/DataAnalysis_STARS.git
---
> **license: MIT License**
---
提供机构:
maas
创建时间:
2025-08-12
搜集汇总
数据集介绍
背景与挑战
背景概述
DataAnalysis_STARS是一个专注于社交媒体文本情感分析的数据集,包含数据预处理、情感分析模型应用及可视化报告等内容。此外,还推荐了来自Kaggle和DataFountain的Twitter、Reddit评论和COVID-19相关微博的情感分析数据集,为研究者提供了丰富的资源。
以上内容由遇见数据集搜集并总结生成


