jiangjiechen/ekar_chinese
收藏Hugging Face2023-01-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jiangjiechen/ekar_chinese
下载链接
链接失效反馈官方服务:
资源简介:
ekar_chinese数据集是一个用于类比推理和解释生成任务的中文数据集。该数据集包含1655个中文问题,来源于中国公务员考试。每个问题都有候选答案和解释,解释用于说明类比推理的过程。数据集支持两种任务模式:EASY模式和HARD模式。EASY模式允许使用查询解释作为输入的一部分,而HARD模式则不允许。数据集的创建目的是帮助开发能够正确推理的类比推理系统。
提供机构:
jiangjiechen
原始信息汇总
数据集概述
数据集名称
- 名称: ekar_chinese
数据集摘要
- 摘要: E-KAR
v1.1包含1,655个中文问题和1,251个英文问题,源自中国的公务员考试,要求解决这些问题需要大量的背景知识。该数据集特别设计了自由文本解释方案,为每个问题和候选答案手动注释了解释。
支持的任务
- 任务1: 类比问答 (
analogical-qa) - 任务2: 解释生成 (
explanation-generation)
语言
- 语言: 中文
数据集结构
数据实例
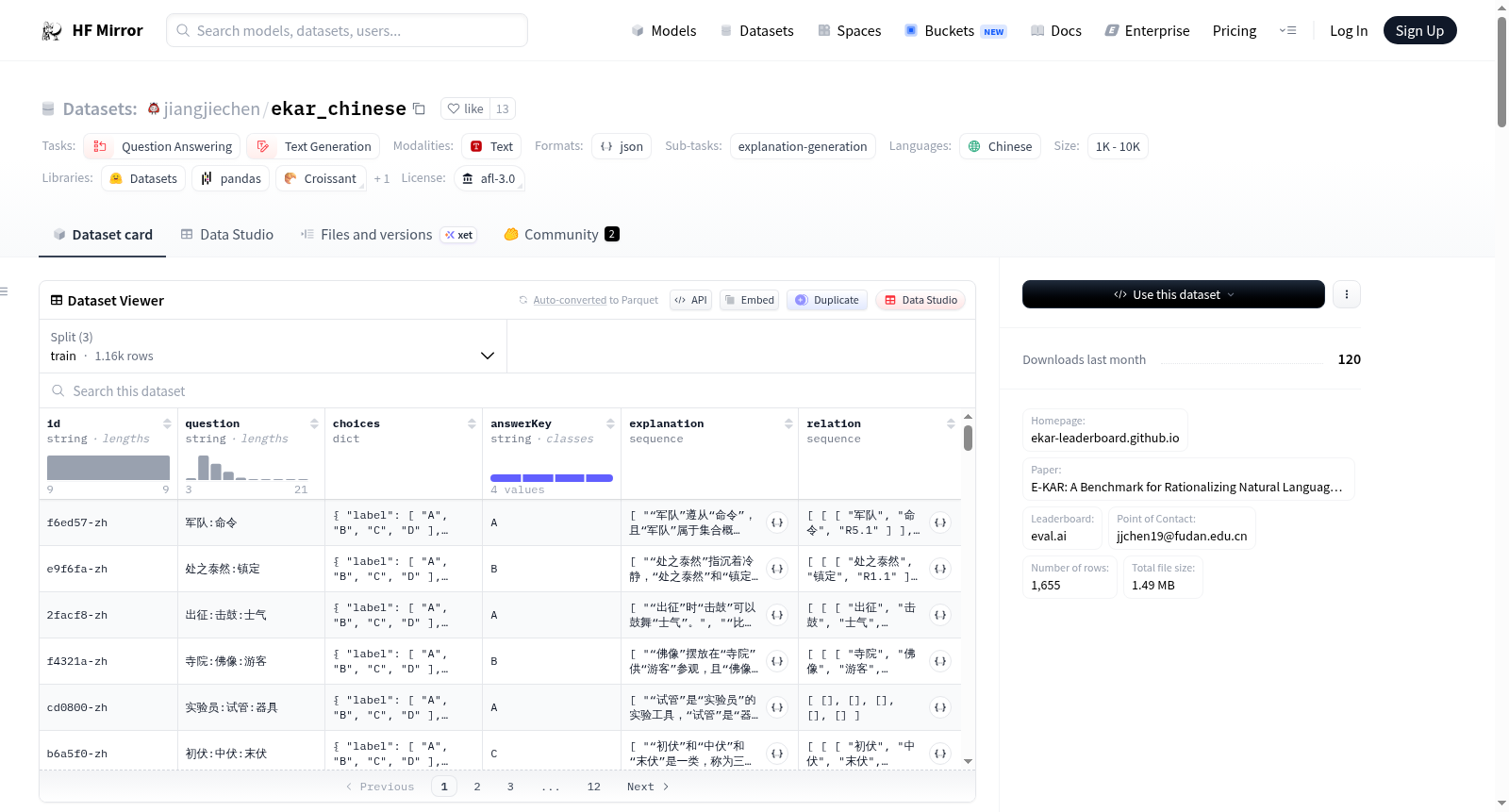
- 示例结构: json { "id": "string identifier", "question": "query terms", "choices": { "label": ["A", "B", "C", "D"], "text": ["candidate answer terms"] }, "answerKey": "correct answer", "explanation": ["explanations for query and candidate answers"], "relation": ["annotated relations for terms in query and candidate answers"] }
数据字段
- 字段1: id (字符串标识符)
- 字段2: question (查询词)
- 字段3: choices (候选答案词)
- 字段4: answerKey (正确答案)
- 字段5: explanation (查询和候选答案的解释)
- 字段6: relation (查询和候选答案中词的注释关系)
数据分割
- 分割详情:
名称 训练 验证 测试 default 1155 165 335
数据集创建
数据集来源
- 来源: 中国的公务员考试
数据集偏差
- 偏差描述: 数据集可能包含偏向中国文化的信息,因为它源自中国的公务员考试。
数据集限制
- 限制1: 解释注释过程主要是事后进行的,仅反映推理结果,不提供中间推理的监督。
- 限制2: 每个问题仅提供一个可能的解释,而实际上可能有多个。
数据集管理
数据集创建者
- 创建者: Jiangjie Chen, Rui Xu, Ziquan Fu, Wei Shi, Xinbo Zhang, Changzhi Sun 等来自复旦大学和字节跳动的同事。
搜集汇总
数据集介绍
构建方式
在自然语言处理与认知科学交叉领域中,类比推理能力的评测一直是研究难点。E-KAR中文数据集基于中国公务员考试题目构建,经过严格的人工筛选与标注流程,最终收录了1655道中文题目。每个题目均包含查询词对、四个候选答案、正确答案标识以及人工撰写的自由文本解释。数据集还提供了语义关系标注,如R3.7表示原材料关系,以支撑深层次的推理过程分析。数据划分为训练集1155条、验证集165条和测试集335条,测试集答案保持盲态,确保评估的公正性。
特点
该数据集的核心特色在于其知识密集型与解释驱动性。题目要求模型不仅识别词语间的类比关系,还需生成合理的自由文本解释,揭示推理依据。这种设计迫使模型实现“为正确理由而正确”的推理,而非简单匹配表面模式。此外,数据集支持两种任务模式:EASY模式允许使用查询解释作为输入,HARD模式则完全依赖模型自主推理,从而评估不同层次的类比推理能力。数据集还包含中英双语版本,便于跨语言研究。
使用方法
研究者可基于该数据集开展两类核心任务:类比问答与解释生成。对于类比问答,模型需从四个候选中选出与查询词对形成最佳类比的答案;对于解释生成,模型需为每个查询和候选答案生成合理的推理解释。数据集通过HuggingFace库直接加载,使用load_dataset函数即可获取。训练时可采用标准序列到序列模型或预训练语言模型,评估指标包括准确率与解释质量评分。建议结合EASY与HARD两种模式进行对比实验,以全面衡量模型的推理鲁棒性。
背景与挑战
背景概述
类比推理作为人类认知的核心能力之一,在自然语言处理领域中始终是极具挑战性的研究课题。由复旦大学、字节跳动等机构的研究人员于2022年提出的E-KAR中文数据集(ekar_chinese),旨在构建首个可解释的知识密集型类比推理基准。该数据集包含1655个源自中国公务员考试的中文问题,要求模型不仅具备丰富的背景知识以解答类比推理题目,还需生成自由文本解释以阐明推理依据。这一开创性工作由陈江杰、徐锐等学者主导,相关论文发表于ACL 2022 Findings,并配套提供了在线排行榜(eval.ai),显著推动了可解释类比推理研究的发展,为评估模型是否真正理解类比关系而非盲目匹配提供了重要标尺。
当前挑战
E-KAR数据集所面临的挑战主要体现于两方面。在领域问题层面,类比推理任务要求模型同时具备知识检索、关系抽象与逻辑泛化能力,现有最先进模型在解释生成与问题回答两个子任务上均表现欠佳,尤其在HARD模式下(禁止使用查询解释作为输入),模型性能大幅下降,暴露出其对隐含语义关系建模的脆弱性。在数据集构建过程中,挑战同样严峻:中文公务员考试题目本身蕴含大量文化特定背景知识,翻译与注释工作需确保跨语言一致性;此外,解释标注多为事后归因,仅反映推理结果而非中间过程,且每个问题仅提供一种可行解释,忽视了推理路径的多样性,这限制了数据对模型逐步推理能力的监督效能。
常用场景
经典使用场景
E-KAR中文数据集作为首个面向自然语言类比推理的可解释知识密集型基准,其经典使用场景集中于两项核心任务:类比问答与解释生成。在类比问答中,模型需从多项选择中甄别出与给定问题对构成最佳类比关系的选项,例如从‘植物:煤炭’的原材料关系中选出‘牛奶:酸奶’。该任务要求模型不仅理解语义关系,还需调用外部知识进行跨域映射。而在解释生成任务中,模型需为每个类比判断生成自由文本的理由,阐明关系匹配的逻辑链条,从而揭示推理过程的内部机制。这种双任务设计使得E-KAR成为评估语言模型深层认知能力的试金石。
实际应用
在实际应用中,E-KAR数据集所塑造的类比推理能力可迁移至多个高价值场景。在教育领域,它可用于开发智能辅导系统,自动解析学生类比题目的解题思路并生成个性化反馈;在知识管理场景中,类比推理引擎能辅助专利检索或科研发现,通过跨领域关系映射揭示隐含的技术关联;在法律与政策分析中,模型可基于历史案例的类比逻辑生成裁决建议或政策影响评估。此外,E-KAR的解释生成特性使其天然适配可解释AI系统,例如在金融风控中,模型不仅能判断风险模式相似性,还能输出可审计的推理路径,提升决策透明度与合规性。
衍生相关工作
E-KAR数据集催生了一系列具有影响力的后续工作。在方法论层面,研究者基于其双任务框架提出了联合学习范式,如利用对比学习增强关系表征的鲁棒性,或设计层次化解码器以协同生成解释与答案。在评估维度上,相关工作进一步拓展了类比推理的边界,例如引入多语言版本以检验跨文化迁移能力,或融合知识图谱增强推理的深度与广度。代表性工作包括基于E-KAR的硬模式(HARD mode)挑战,迫使模型在不依赖查询解释的条件下独立完成推理,这一设定直接启发了后续关于‘零样本类比推理’的探索。此外,该数据集还被用作预训练语言模型(如GPT-3、BERT)认知能力的诊断工具,揭示了大规模模型在结构化关系理解上的系统性缺陷。
以上内容由遇见数据集搜集并总结生成


