L2M3 (Large Language Model MOF Miner)
收藏arXiv2024-03-31 更新2024-08-06 收录
下载链接:
http://arxiv.org/abs/2404.13053v1
下载链接
链接失效反馈官方服务:
资源简介:
L2M3数据集是由韩国科学技术高级研究院化学与生物分子工程系开发的,专注于金属有机框架(MOF)的属性数据。该数据集通过分析超过40,000篇研究文章,提取了32种定义明确的属性,并进一步将MOF合成过程分类为21个独特类别,增强了数据集的粒度。数据集的创建过程涉及使用先进的语言模型自动提取和组织MOF数据。L2M3数据集的应用领域广泛,包括气体存储、分离、催化及药物递送等,旨在通过实验数据提高机器学习预测的准确性,解决仅依赖模拟数据可能带来的问题。
The L2M3 dataset, developed by the Department of Chemical and Biomolecular Engineering at the Korea Advanced Institute of Science and Technology (KAIST), focuses on property data of metal-organic frameworks (MOFs). By analyzing over 40,000 research articles, it extracts 32 well-defined properties and further categorizes MOF synthesis processes into 21 distinct categories, thereby enhancing the dataset's granularity. The development of this dataset involves the automatic extraction and organization of MOF data using advanced language models. The L2M3 dataset has a wide range of application scenarios, including gas storage, separation, catalysis, drug delivery and more. It aims to improve the accuracy of machine learning predictions with experimental data, addressing potential issues caused by relying solely on simulated data.
提供机构:
韩国科学技术高级研究院化学与生物分子工程系
创建时间:
2024-03-31
搜集汇总
数据集介绍
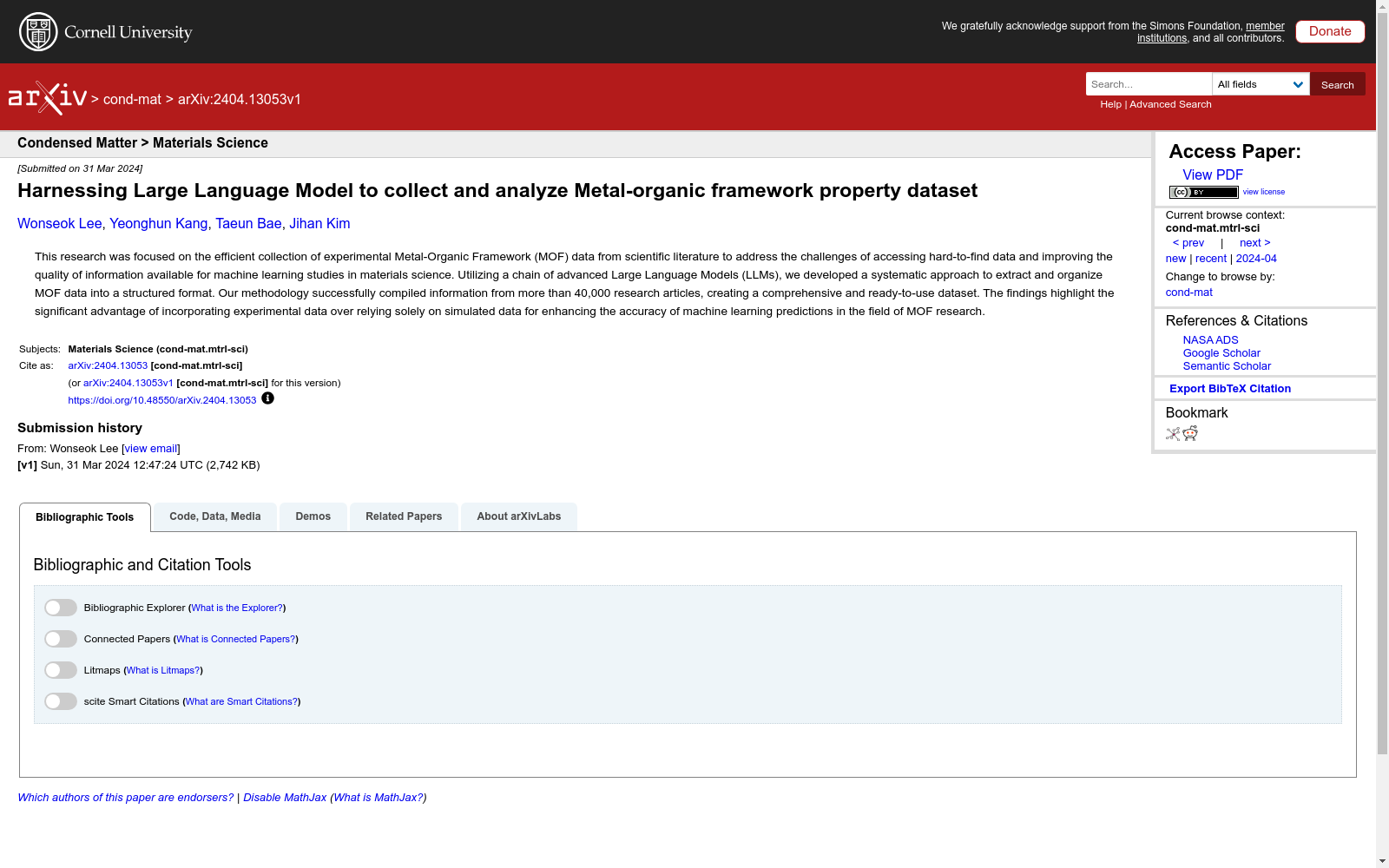
构建方式
在金属有机框架(MOF)研究领域,数据的高效收集与整合是推动材料科学机器学习应用的关键。L2M3数据集通过一套基于大语言模型(LLM)的自动化挖掘系统构建而成,该系统精心设计了三个专用智能体——表格智能体、合成条件智能体与性质智能体,分别从科学文献的表格与文本中提取信息。整个流程涵盖分类、包含与提取三个核心阶段,并借助匹配智能体对材料名称与符号进行标准化处理,最终将提取的数据与剑桥结构数据库(CSD)中的晶体结构信息进行关联。通过对超过四万篇学术论文的系统性挖掘,该数据集成功汇集了MOF的合成条件与多种物理化学性质,形成了一套结构清晰、可直接用于机器学习研究的综合性资源。
特点
L2M3数据集展现出多方面的显著特点。其覆盖范围极为广泛,不仅包含了超过32种明确定义的MOF性质(如比表面积、孔体积、分解温度等),还将合成过程细致划分为21个不同类别,极大提升了数据的粒度与实用性。数据集深度融合了实验数据,尤其注重收集那些难以通过模拟获得的性质信息,从而弥补了传统计算数据与实验现实之间的差距。在数据质量方面,该数据集通过先进的LLM流程实现了高精度提取,各项任务的F1分数普遍超过0.95,确保了信息的可靠性与一致性。此外,数据集与CSD数据库的集成提供了丰富的晶体学元数据,为深入理解MOF的结构-性能关系奠定了坚实基础。
使用方法
该数据集为MOF领域的机器学习研究提供了强大的数据支持。研究人员可直接利用其结构化的性质与合成数据,训练预测模型以加速新材料的设计与发现。数据集特别适用于探索实验数据与模拟数据在预测准确性上的差异,例如通过对比基于实验数据训练的模型与基于模拟数据训练的模型性能,揭示实验数据对于提升预测可靠性的关键作用。此外,数据集可与ChatMOF等交互式工具结合,实现基于自然语言的合成条件查询与材料元数据检索,为材料科学家提供了一个动态、智能的数据探索平台。在具体应用中,用户可根据研究目标筛选特定性质或合成类别的子集,结合描述符模型、图神经网络或多模态Transformer等先进算法,开展有针对性的材料性能预测与逆向设计研究。
背景与挑战
背景概述
金属有机框架(MOF)作为一类具有可调孔隙和功能的多孔材料,在气体存储、分离、催化及药物递送等领域展现出广阔应用前景。然而,MOF的多样性源于其庞大的金属-配体组合空间,这为系统性地收集与整理其实验数据带来了显著挑战。传统上,材料科学领域的数据集多依赖于计算模拟,而实验数据往往散落于海量科学文献中,难以被高效挖掘与利用。在此背景下,韩国科学技术院(KAIST)的Jihan Kim教授团队于近期创建了L2M3(大型语言模型MOF挖掘者)数据集。该数据集旨在通过先进的大型语言模型链,从超过四万篇研究论文中自动化提取并结构化MOF的合成条件与物性数据,从而构建一个全面且可直接用于机器学习研究的实验数据集。L2M3的诞生标志着材料信息学领域在利用人工智能技术整合实验知识方面迈出了关键一步,其通过弥合理论模拟与实验验证之间的鸿沟,显著提升了机器学习模型在预测MOF性质时的准确性与可靠性。
当前挑战
L2M3数据集致力于解决材料科学中一个核心问题:如何高效、准确地从非结构化的科学文献中挖掘金属有机框架的实验数据,以支持数据驱动的材料发现与设计。这一领域问题的挑战在于,实验数据通常以自由文本或复杂表格形式嵌入文献,其表述方式多样且缺乏统一标准,使得传统基于规则的信息提取方法难以实现高覆盖率与高精度。在数据集构建过程中,研究团队面临多重具体挑战。首先,需要设计一个能够同时处理文本与表格数据的智能代理系统,以应对科学文献中多样的数据呈现形式。其次,为确保提取数据的质量与一致性,必须开发精细的提示工程与模型微调策略,使大型语言模型能够准确理解并分类合成过程、识别特定物性及其数值单位。再者,数据整合阶段需将提取的信息与剑桥结构数据库等权威资源进行匹配与标准化,以消除材料命名与符号的歧义。最后,随着处理文献数量的增长,论文格式的多样性可能导致挖掘精度下降,因此需要在处理规模与保持准确性之间取得平衡,这构成了数据集构建中的持续挑战。
常用场景
经典使用场景
在金属有机框架(MOF)材料科学领域,数据驱动的材料发现依赖于高质量、结构化的实验数据集。L2M3数据集通过大语言模型自动化挖掘超过四万篇学术文献,系统性地提取了MOF的合成条件、晶体参数、孔隙特性及热稳定性等32种关键性质,并以标准化JSON格式整合。该数据集最经典的应用场景在于为机器学习模型提供大规模、高精度的实验训练数据,支撑从高通量筛选到逆向设计的全流程研究,尤其适用于预测MOF的吸附性能、催化活性及结构稳定性等核心性质。
解决学术问题
L2M3数据集有效解决了MOF研究中实验数据分散、获取困难及与模拟数据存在系统偏差的学术挑战。通过提供大规模实验验证的性质数据,该数据集显著提升了机器学习模型预测实验结果的准确性,实证研究表明,基于实验数据训练的模型其预测R²值可达0.892,远高于基于模拟数据训练的模型。这弥合了理论计算与实验验证之间的鸿沟,为材料基因工程中的数据可靠性问题提供了切实解决方案,并推动了数据驱动材料设计范式的范式转变。
衍生相关工作
L2M3数据集催生了多项前沿交叉研究,其中最具代表性的是与多模态预训练模型MOFTransformer的结合,实现了跨材料体系的通用迁移学习。基于该数据集开发的ChatMOF系统,融合了材料搜索、性质预测与遗传算法生成模块,开创了自主人工智能在材料科学中的应用先河。同时,数据集支撑了图神经网络CGCNN在MOF稳定性预测中的性能优化,并衍生出针对合成条件文本挖掘的细粒度分类模型,推动了自然语言处理与材料信息学的深度融合。
以上内容由遇见数据集搜集并总结生成


