clcp_clf
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/aarabil/clcp_clf
下载链接
链接失效反馈官方服务:
资源简介:
README文件详细介绍了多个数据集的信息,包括配置名称、特征、数据类型、分割和大小。数据集以文本和假设特征构建,标签分为蕴涵和非蕴涵两类。每个数据集都有指定的训练和测试分割的示例数量和字节大小,以及整体的下载和数据集大小。文件还包含了每个分割和数据集的数据文件路径。
创建时间:
2025-05-24
原始信息汇总
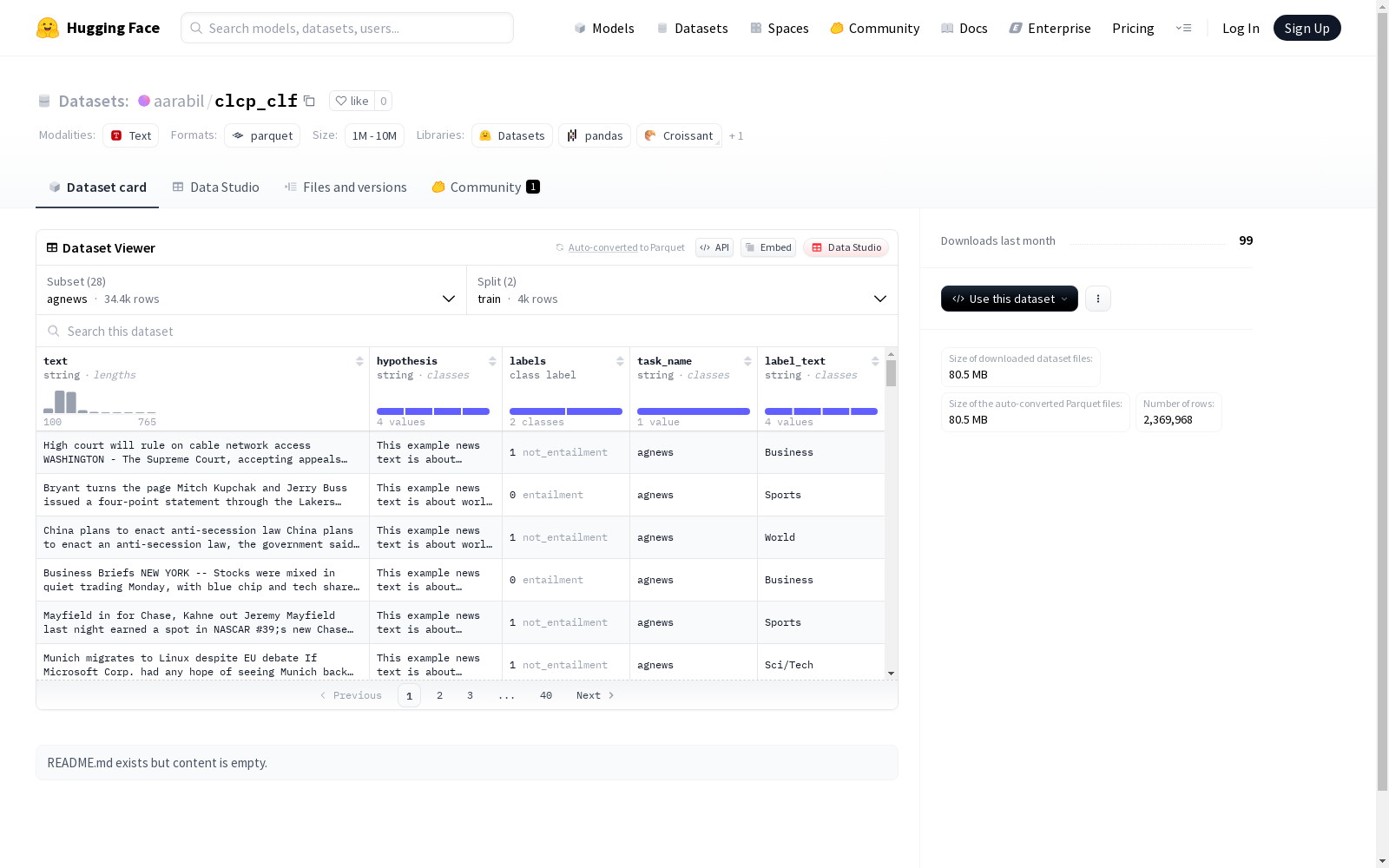
数据集概述
数据集基本信息
- 名称: aarabil/clcp_clf
- 类型: 多配置文本分类数据集
- 任务: 文本蕴含识别(entailment classification)
数据集配置
共包含28个配置,涵盖多个领域:
新闻与评论类
agnews: 新闻分类- 训练集: 4,000条
- 测试集: 30,400条
imdb: 电影评论- 训练集: 2,000条
- 测试集: 20,000条
rottentomatoes: 电影评论- 训练集: 2,000条
- 测试集: 2,132条
商业与金融类
amazonpolarity: 亚马逊产品评价- 训练集: 2,000条
- 测试集: 20,000条
financialphrasebank: 金融短语- 训练集: 2,524条
- 测试集: 2,070条
yelpreviews: Yelp评论- 训练集: 1,542条
- 测试集: 20,000条
社交媒体与对话类
appreviews: 应用评论- 训练集: 2,000条
- 测试集: 8,000条
emocontext: 情感上下文- 训练集: 4,000条
- 测试集: 22,036条
emotiondair: 情感对话- 训练集: 5,036条
- 测试集: 12,000条
empathetic: 共情对话- 训练集: 4,226条
- 测试集: 81,344条
特定领域类
banking77: 银行客服- 训练集: 9,508条
- 测试集: 221,760条
manifesto: 政治宣言- 训练集: 10,000条
- 测试集: 953,008条
massive: 多语言语音指令- 训练集: 9,794条
- 测试集: 175,466条
wellformedquery: 结构化查询- 训练集: 2,000条
- 测试集: 5,934条
偏见与毒性检测类
biasframes_intent: 意图偏见- 训练集: 2,000条
- 测试集: 7,296条
biasframes_offensive: 冒犯性内容- 训练集: 2,000条
- 测试集: 7,676条
biasframes_sex: 性别偏见- 训练集: 2,000条
- 测试集: 8,808条
hateoffensive: 仇恨言论- 训练集: 2,152条
- 测试集: 2,586条
hatexplain: 仇恨言论解释- 训练集: 2,958条
- 测试集: 2,922条
wikitoxic_identityhate: 身份仇恨- 训练集: 2,000条
- 测试集: 11,424条
wikitoxic_insult: 侮辱性内容- 训练集: 2,000条
- 测试集: 16,854条
wikitoxic_obscene: 淫秽内容- 训练集: 2,000条
- 测试集: 17,382条
wikitoxic_threat: 威胁内容- 训练集: 1,760条
- 测试集: 10,422条
wikitoxic_toxicaggregated: 综合毒性- 训练集: 2,000条
- 测试集: 20,000条
其他类
capsotu: 对话理解- 训练集: 4,648条
- 测试集: 70,455条
spam: 垃圾邮件- 训练集: 1,865条
- 测试集: 2,070条
trueteacher: 教育领域- 训练集: 2,000条
- 测试集: 17,910条
yahootopics: Yahoo话题- 训练集: 10,000条
- 测试集: 500,000条
数据特征
所有配置共享相同特征结构:
text: 文本内容 (string)hypothesis: 假设文本 (string)labels: 标签0: entailment1: not_entailment
task_name: 任务名称 (string)label_text: 标签文本 (string)
数据分割
每个配置均包含:
- 训练集 (train)
- 测试集 (test)
数据规模
各配置数据规模差异较大,最小为spam(606KB),最大为manifesto(422MB)
搜集汇总
数据集介绍
构建方式
clcp_clf数据集通过整合多个公开文本分类数据集构建而成,涵盖新闻分类、情感分析、毒性检测等多个自然语言处理领域。每个子数据集如AGNews、IMDb等都经过标准化处理,统一转化为蕴含识别任务格式,包含文本、假设和标签三要素。数据划分遵循原始数据集结构,保留训练集和测试集比例,确保评估的可靠性。
特点
该数据集最显著的特点是任务多样性,包含22种不同领域的文本分类任务,每个任务都具有明确的二分类标签体系。数据规模呈现差异化特征,从数千到数百万样本不等,为模型提供丰富的训练场景。文本内容涵盖正式新闻、社交媒体、金融术语等多类型语料,具有较高的语言复杂性。
使用方法
使用该数据集时,建议根据具体任务选择对应的子数据集配置。加载数据可采用HuggingFace数据集库的标准接口,通过config_name参数指定目标领域。典型工作流程包括文本预处理、假设生成和蕴含关系分类,评估时应关注模型在不同领域间的迁移表现。对于小样本子集,可采用交叉验证提升结果稳定性。
背景与挑战
背景概述
clcp_clf数据集是一个多任务文本分类数据集,涵盖了新闻分类、情感分析、金融文本分类、毒性检测等多个自然语言处理任务。该数据集由多个子数据集组成,如AG News、Amazon Polarity、Banking77等,每个子数据集都针对特定的文本分类问题进行了标注。数据集的构建旨在为研究者提供一个统一的平台,用于评估和比较不同文本分类模型在多样化任务上的性能。通过整合多个领域的文本数据,clcp_clf数据集为跨领域文本分类研究提供了丰富的实验材料,推动了自然语言处理领域的发展。
当前挑战
clcp_clf数据集面临的主要挑战包括:1) 领域多样性带来的分类难度,不同子数据集的文本风格和语义特征差异显著,模型需要具备强大的泛化能力;2) 数据标注的一致性,尤其是在毒性检测等主观性较强的任务中,标注标准难以统一;3) 数据规模不平衡,部分子数据集的训练样本较少,可能导致模型在这些任务上表现不佳;4) 多任务学习的复杂性,如何有效共享不同任务之间的知识仍需进一步探索。
常用场景
经典使用场景
在自然语言处理领域,clcp_clf数据集以其丰富的文本分类任务配置成为研究文本蕴含关系的经典基准。该数据集通过多组预设的文本-假设对,为模型提供了判断两个句子是否存在逻辑蕴含关系的训练环境,特别适用于测试模型在跨领域文本中的推理能力。从新闻分类到情感分析,其多样化的子集设计为研究者提供了验证模型泛化性能的理想平台。
衍生相关工作
基于该数据集衍生的研究工作包括跨任务迁移学习框架CLCP-MTL,该框架通过共享底层表征提升了多任务下的蕴含判断性能。在可解释AI方向,HateCheck基准利用数据集的wikitoxic子集开发了针对仇恨言论检测的细粒度评估体系,推动了内容安全领域模型透明度的研究进展。
数据集最近研究
最新研究方向
在自然语言处理领域,clcp_clf数据集因其涵盖文本蕴含任务的多样性而备受关注。该数据集整合了多个子集,如agnews、amazonpolarity和hatexplain等,广泛应用于情感分析、仇恨言论检测和金融文本分类等前沿研究。近年来,随着预训练语言模型的兴起,研究者们利用该数据集探索零样本和小样本学习在文本蕴含任务中的表现,特别是在跨领域迁移学习方面取得了显著进展。此外,针对数据集中的偏见和毒性内容,学术界正致力于开发更公平、更鲁棒的分类模型,以应对社交媒体和在线平台中的内容审核挑战。
以上内容由遇见数据集搜集并总结生成


