Long SFT Dataset
收藏arXiv2025-09-30 收录
下载链接:
https://chatqa2-project.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集旨在提升模型处理长达128k标记的长上下文序列的能力,通过整合现有长上下文数据集和合成数据而构建。数据集不仅包含了高质量遵循指令的数据集,还融入了专为训练具有长上下文能力模型而设计的对话式问答数据。此外,该数据集还针对长上下文理解和检索增强生成任务进行了专门的指令调优。
This dataset is designed to enhance models' capacity for handling long-context sequences up to 128k tokens. It is constructed by integrating existing long-context datasets and synthetic data. The dataset not only contains high-quality instruction-following datasets, but also incorporates conversational question-answering data specifically tailored for training models with long-context capabilities. Additionally, this dataset features specialized instruction tuning data for long-context understanding and retrieval-augmented generation (RAG) tasks.
提供机构:
ChatQA Project
搜集汇总
数据集介绍
背景与挑战
背景概述
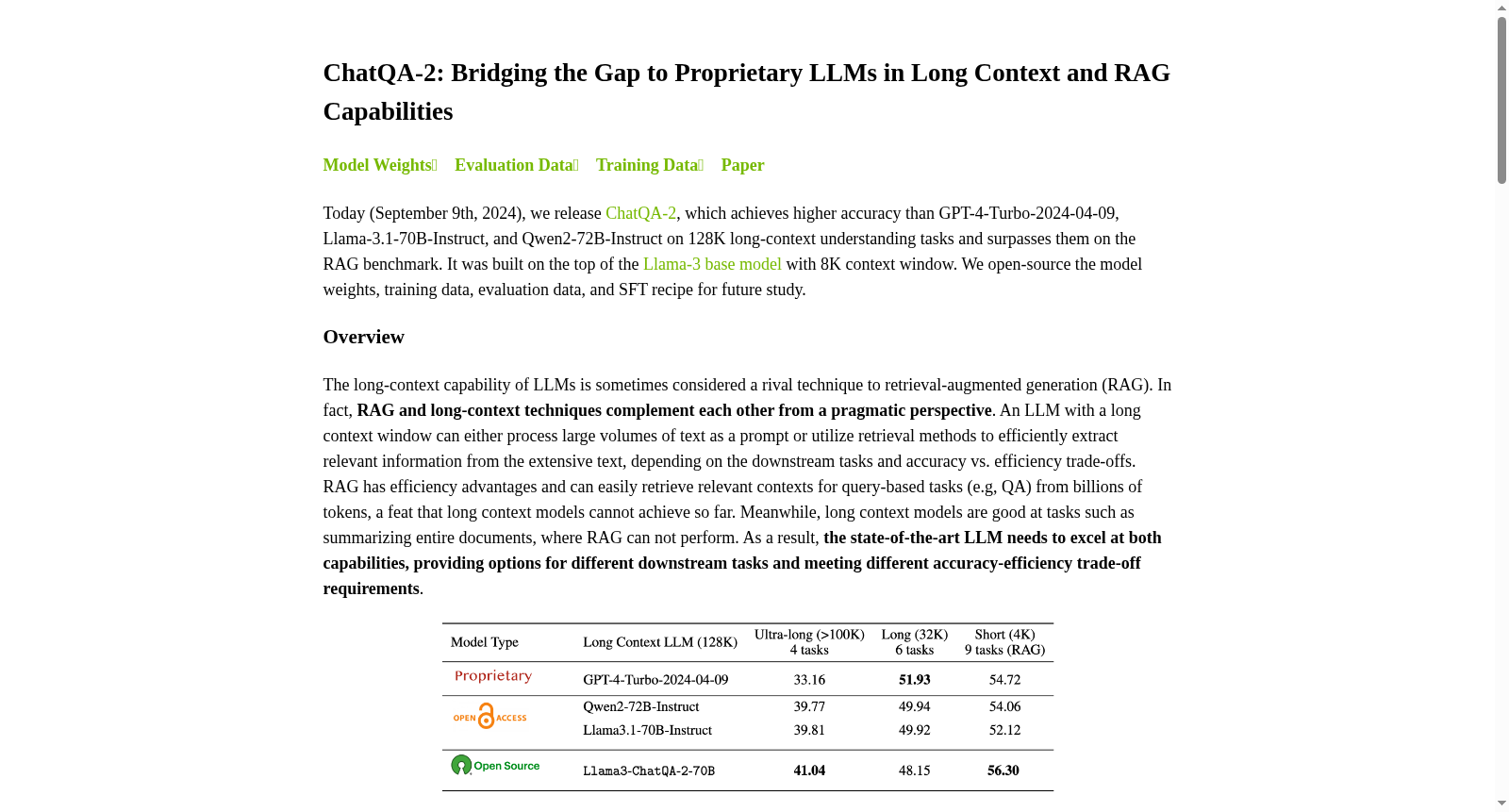
Long SFT Dataset是一个用于训练和评估长上下文理解任务的数据集,特别针对ChatQA-2模型的设计和优化。该数据集支持128K长上下文任务,并在多个基准测试中表现出色,超越了包括GPT-4-Turbo在内的多个先进模型。数据集的开源资源和训练方法为研究长上下文模型提供了重要支持。
以上内容由遇见数据集搜集并总结生成


